하둡을 배워야 하는 이유?
우리는 데이터 홍수의 시대에 살고 있으며, 하둡은 비정형 데이터를 포함한 빅데이터를 다루기 위한 가장 적절한 플랫폼이다
데이터 증가로 하둡을 적용하는 회사들은 급증하고 있으며, 하둡 전문가는 항상 부족하다. 하둡은 2007년에 첫 탄생이후 3점대 버전(2020년 기준)까지 나온 성숙한 기술이다
하둡에코시스템은 Governance, Finance, Backing, Insurance, Heathcar 등 사회 전반에 걸쳐 적용되고 있다
하둡의 탄생
더그 커팅은 검색엔진에 들어가는 색인기로서 인덱싱 라이브러리 Lucene을 오픈소스로 공개 하였다
여기에 아들 프로젝트로 웹 검색 엔진 프로젝트인 Nutch를 탄생시켰으며, 여기서 또 아들 프로젝트로 빅데이터 처리 프로젝트인 hadoop을 탄생시켰다
Lucene (루신) -> Nutch -> Hadoop
진화과정
웹 검색엔진을 만들기 위해서는 웹 크롤링을 해야하고 크롤링한 데이터를 저장한 다음에 루신 인덱싱 라이브러리로 색인을 해야한다. 하지만 너무 많은 데이터가 존재하므로 대규모 분산 병렬 처리를 해야하는데 이를 어떤 아키텍쳐로 가져가야 큰 데이터를 처리하므로서 생기는 문제점을 처리할 수 있을까 고민하다가 구글의 파일 시스템 논문과 맵리듀스 논물을 참고하여 너치 분산 파일시스템을 개발하게 된다
구글에서 대규모 데이터를 병령 분산 처리하기 위해 사용하는 알고리즘이 Map Reduce이고 맵리듀스의 동작 방식이 적힌 논문
맵리듀스를 만든 구글개발자 - 제프 딘
구글 시스템과의 매칭
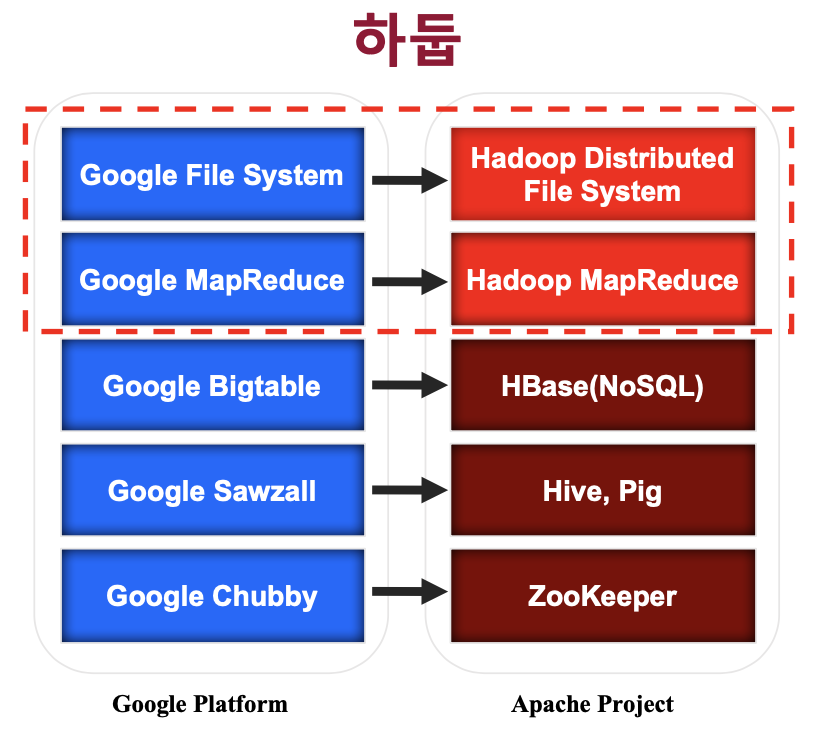
HBase
기존 데이터베이스를 떠올리면 RDBMS와 같은 관계형 데이터베이스(MySql, Oracle)를 생각하게 된다
관계형DB의 경우 데이터를 저장하는 저장소로 공유 스토리지를 사용하게 되는데(센, 나스) 데이타의 저장량이 늘어나고 공유 스토리지를 연산하는 컴퓨팅 리소스가 늘어나면 어느정도 수준까지는 성능이 증가하지만 일정 수준 이상으로 증가를 하면 디스크I/O쪽에서 보틀넥(병목현상)이 걸리면서 성능이 떨어지는 현상이 존재한다.
따라서 이를 해결하기 위해 DB도 분산 데이터 베이스, 즉 분산 노드에 저장되는 데이타베이스가 많이 발전을 하고 있으며 대표적인 것이 HBase이다
Hive
분산 데이터 베이스로 관리되는 HBase의 데이터를 일반적으로 사용하는 관계형 데이터베이스 Sql로 관리할 수 없냐는 니즈에 답하기 위해 나온 프로젝트
sql로 관리를 하기 위해서는 데이터가 정형 데이터야 하며 비정형, 반정형 데이터의 경우에는 다시 MapReduce로 프로그래밍을 할 필요가 있다
계층구조로 보는 관련 플랫폼
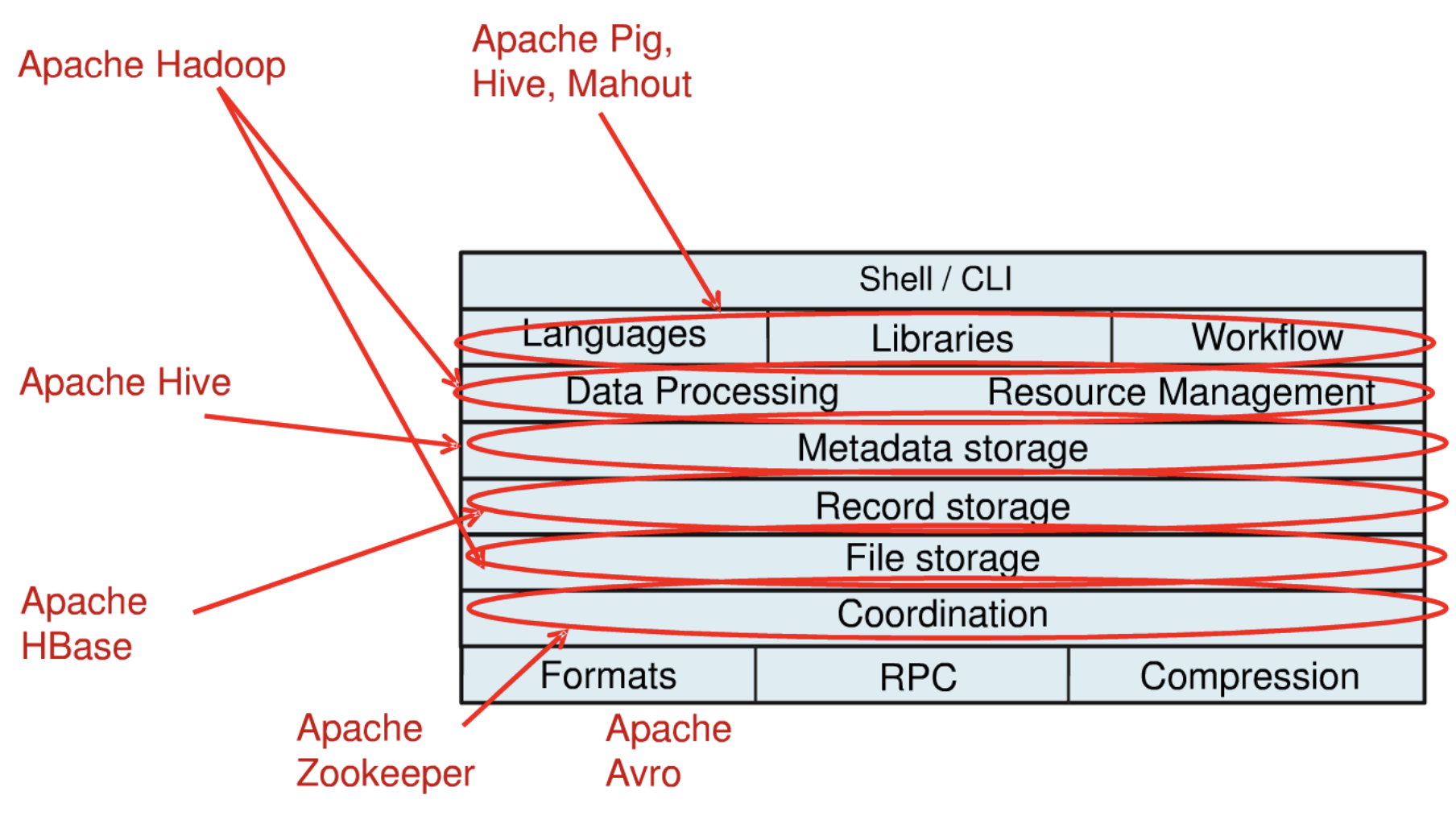
Hadoop : 데이터를 저장하고 프로세싱하는 영역에 해당
- 이런 데이터를 저장을하고 프로세싱을 할때 분산처리를 하기 때문에 리소스 Management 부분이 필요로 한다
Hive : 기본적으로 저장되어있는 데이터의 Metadata를 참조해서 쿼리를 던지게 된다
HBase : 분산 데이터 베이스
ZooKeeper : Coordinate역활
Avro : Serialization Framwork으로 데이터를 송수신 할때 데이터를 직렬화하고 역직렬화할때 사용하는 프레임워크로 볼수 있으며, 서버와 클라이언트 프로그래밍을 할때 경량 애플리케이션으로 구성을 할수 있는 프레임워크로 사용되기도 한다
Serialization
직렬화 또는 시리얼라이제이션은 컴퓨터 과학의 데이터 스토리지 문맥에서 데이터 구조나 오브젝트 상태를 동일하거나 다른 컴퓨터 환경에 저장하고 나중에 재구성할 수 있는 포맷으로 변환하는 과정
Deserialization
역직렬화는 직렬화된 파일 등을 역으로 직렬화하여 다시 객체의 형태로 만드는 것
프레임워크가 추가되는 모습
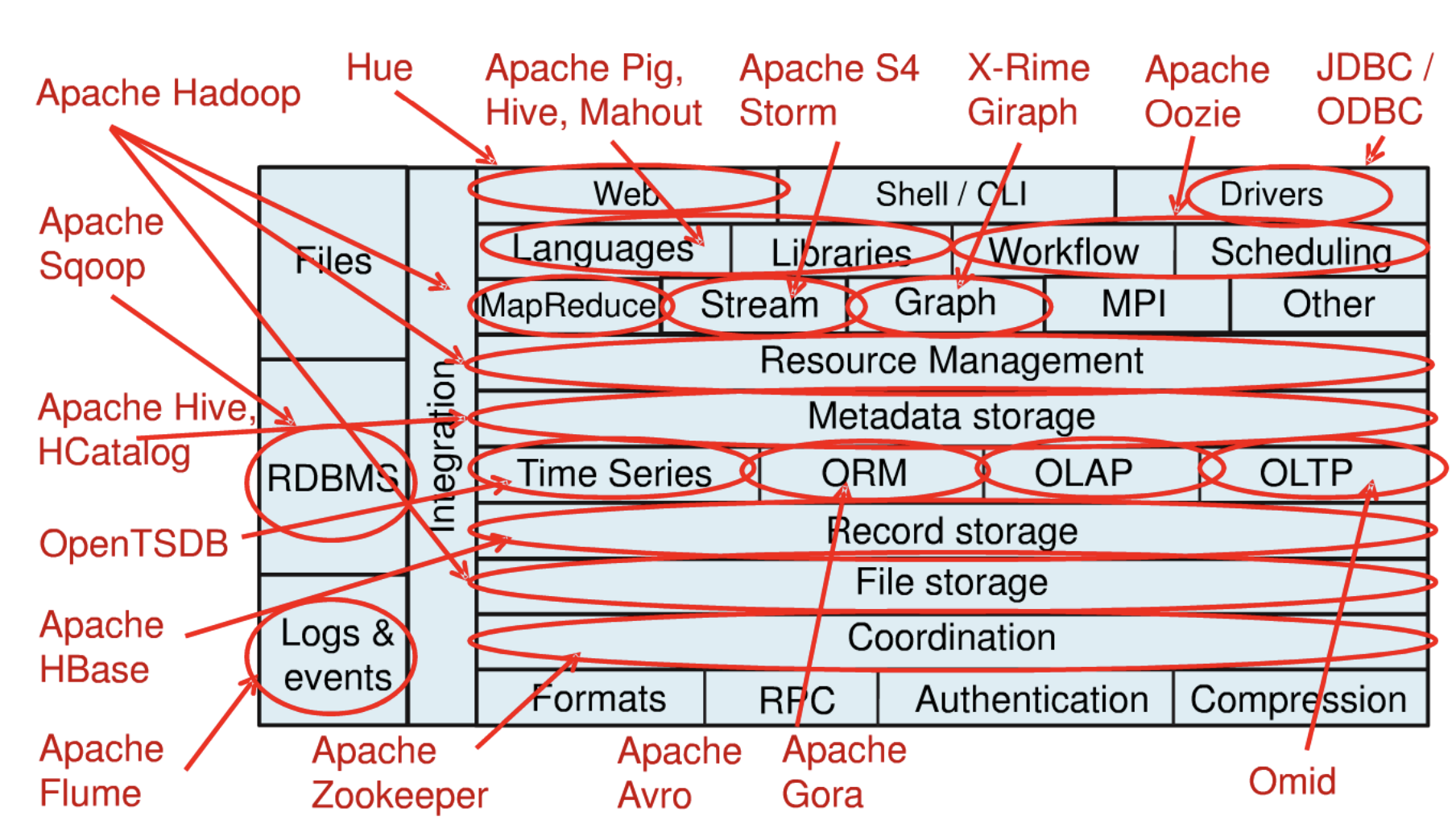
빅데이터 Big Data
(하둡 덕분에)이제는 더이상 많은 데이터를 저장하기 위해 큰 비용이 들지 않는다
-> 데이터로부터 새로운 Insight와 사업기회를 찾기 위한 노력과 시장확대
컴퓨터의 모래알화(작고 싸다), 네트워크의 공기화(어디든 있고 싸다)
-> 저렴한 물건들도 똑똑해지고, 네트웍을 품기 시작했다
결과적으로 큰 데이터를 쉽게 싸게 저장할 수 있는 하둡으로 인해 기록되지 않던 사람들의 생활이 데이터로 남게 되고, 많은 센서데이터들이 데이터를 남기고 저장하게 되었다
현재의 데이터는 사람이 분석할 양을 넘었으며 Machin Leaning을 통해 컴퓨터가 분석하도록 하고있다
데이터 분석 환경 구축
- DT, AI 시대
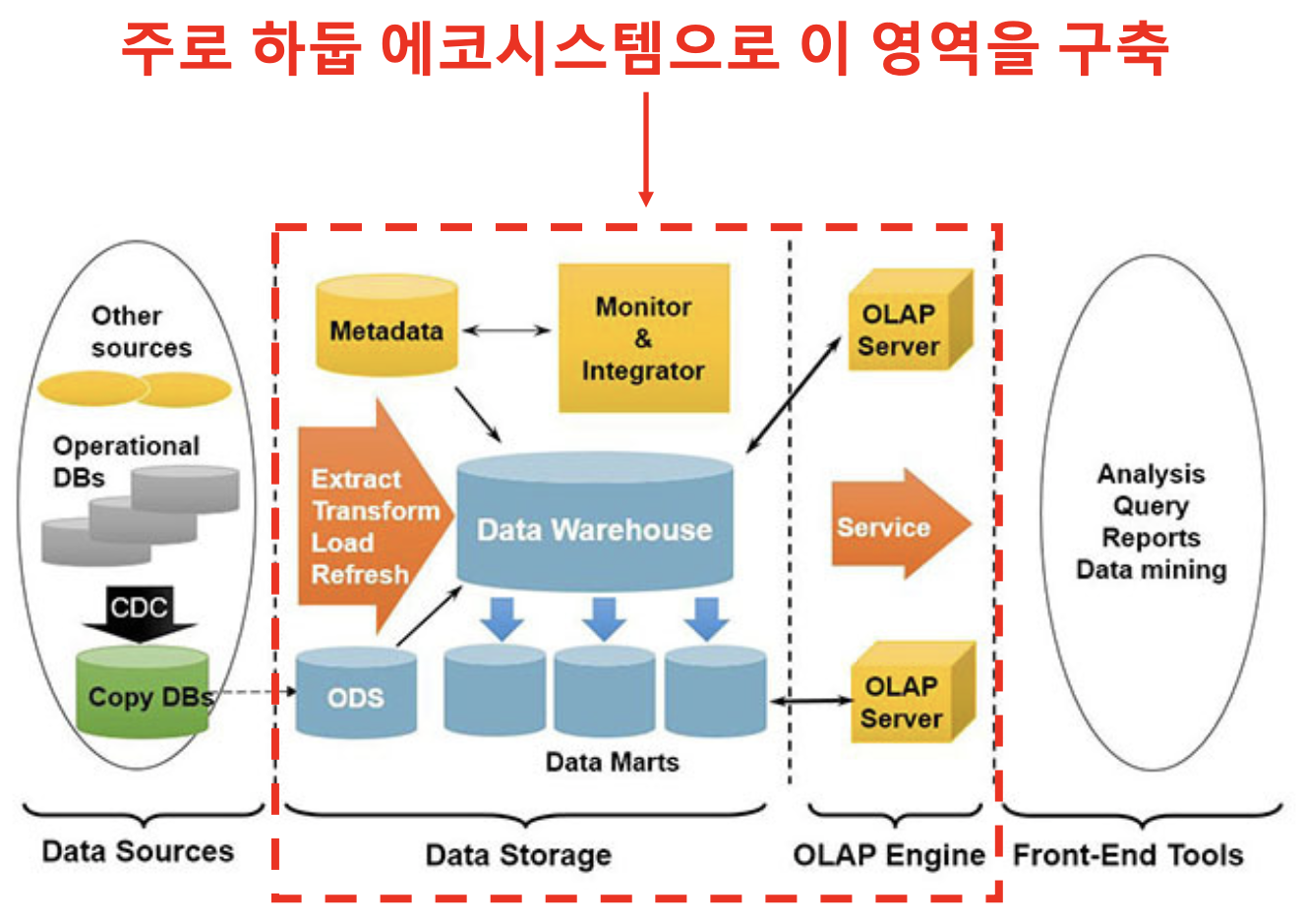
다양한 곳에서 수집된 데이타를 Operational Data Store에 주고 여기서 Data WareHouse에 통합을 한 후에 이 통합된 데이터에서 유의미한 데이터를 뽑은 Data Marts를 만들고 이를 활용해서 서비스를 제공하는 형태이다
-> 데이터에서 패턴을 찾아서 비니지스 기회로
