아파치 하둡 실습
1.아파치 하둡 _ T 아카데미
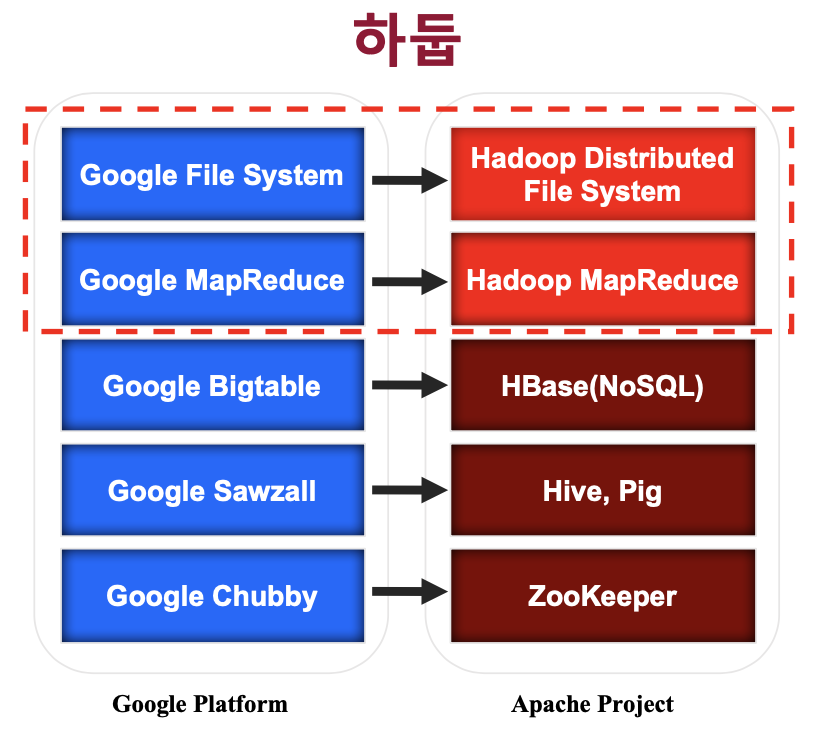
하둡을 배워야 하는 이유? 우리는 데이터 홍수의 시대에 살고 있으며, 하둡은 비정형 데이터를 포함한 빅데이터를 다루기 위한 가장 적절한 플랫폼이다 데이터 증가로 하둡을 적용하는 회사들은 급증하고 있으며, 하둡 전문가는 항상 부족하다. 하둡은 2007년에 첫 탄생이후
2.하둡 설치
하둡 3.3.0 설치하둡 설치 링크하이브 3.1.2 설치하이브 설치 링크압축풀기tar xvfz hadoop-3.3.0.tar.gztar xvfz hive-3.1.2하둡 설정 디렉토리로 이동cd hadoop-3.3.0/etc/hadoop/환경파일(hadoop-env.sh
3.HDFS 이해(1) - 하둡 분산 파일 시스템
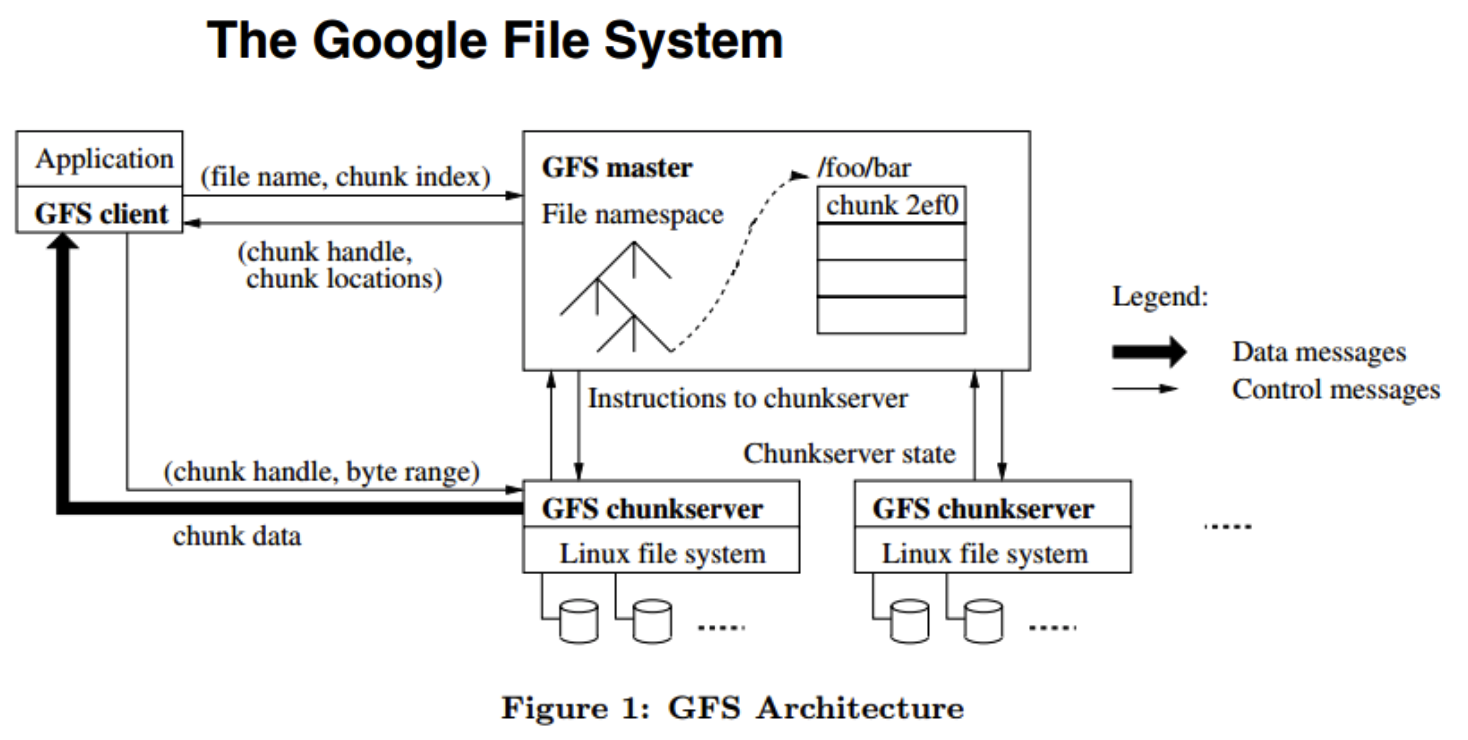
아래 그림은 앞에서 말한 구글 파일 관리 시스템 논문 중 한 부분이다물리적으로 여러대의 서버가 하나의 클러스터처럼 동작하는 그런 플랫폼을 의미그런 분산 플랫폼들의 아키텍쳐를 크게 두개로 구분하면 master-slave구조와 master가 없는 구조로 나눌수가 있다mas
4.HDFS 이해(2) - HDFS 사용자 커맨드
version mkdir ls put copyFromLocal get copyToLocal cat mv cp version
5.HDFS 이해(3) - 하둡 2.0버전
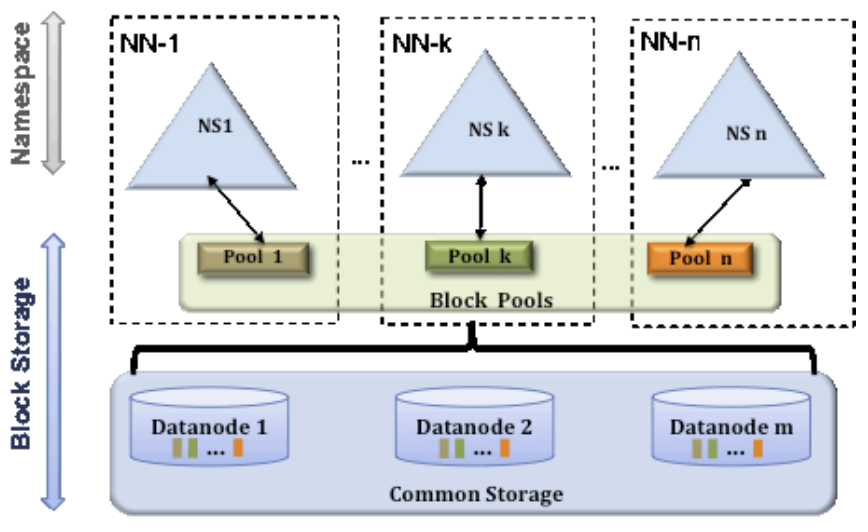
마스터 서버 장애를 해결하기 위한 부분이 가장 큰 변화 포인트그림에서 SNN(Secondary Name Node)와 Active NN는 기존처럼 존재하는데 추가적으로 Stanby Name Node가 추가된 모습을 볼 수 있다Stanby Name Node데이타노드가 블록
6.MapReduce 이해(1)

2004년 구글에서 발표한 Lage Cluster에서 Data Processing을 하기 위한 알고리즘https://static.googleusercontent.com/media/research.google.com/ko//archive/mapreduce-osd
7.MapReduce 이해(2)
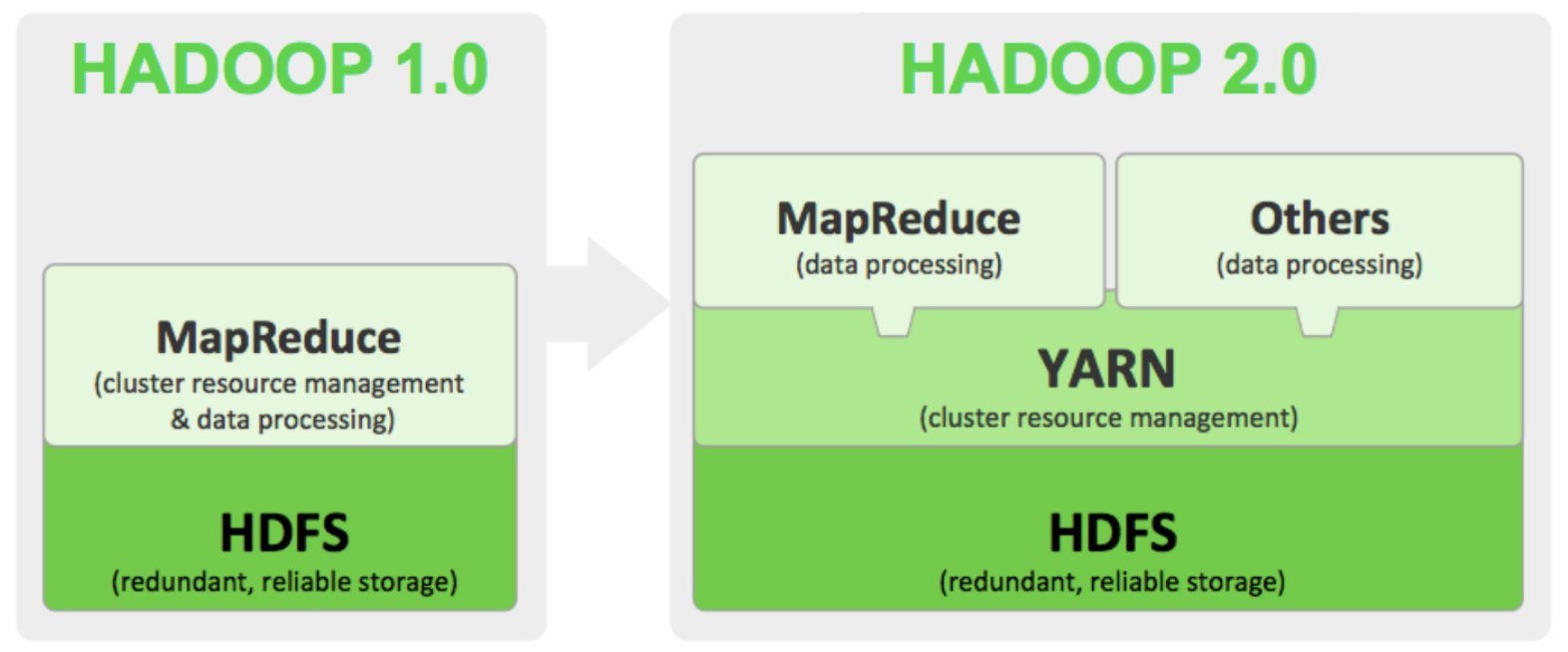
기존에 맵리듀스에서 자원관리와 데이터 처리를 같이하던 것에서 YARN에게 클러스터의 자원 관리를 맡기고 맵리듀스는 데이터 처리를 하도록 분할 하였다. 또한 맵리듀스 이외의 다른 Data Processing 방식도 수용가능한 아키텍쳐로 변경되었다기존 맵리듀스1에서는 40
8.HDFS 활용

크지않은 데이터에 하둡을 적용하는것은 오히려 느리므로 적합하지 않다파일사이즈가 기본적으로 크게 해서 관리하는것이 좋다. 작은 파일들이 여러개로 저장되있는것이 더 안좋다헤르 라는 압축유형이 존재하는데, 작은 파일들을 헤르로 모아서 압축을 해서 보통 관리를 한다데이터 파일