Apache Spark 개인적 실습했던 내용을 옮겨보고자 한다.
서버 스펙 : 4대 서버(Mater Node 1대 / Worker Node 3대)
테스트 데이터 : 테스트 데이터 6.5G
작업 내용 : 테스트 데이터 GroupBy/Aggregate 연산 진행
Apache Spark 사용 이유?
-
Single Machine(Python) 테스트
→ OutOfMemory로 작업 Killed -
Single Machine(PySpark Local Mode) 테스트
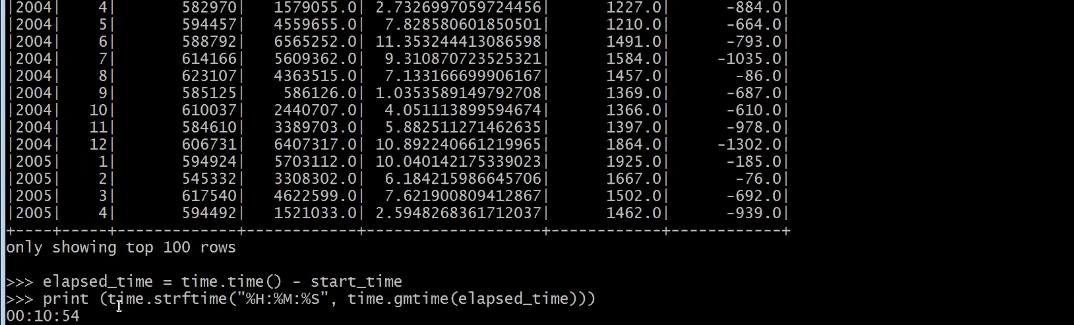
→ 대용량 데이터 처리하는 메커니즘이 달라 느리지만 작업은 오류없이 완료
- Apache Spark(Pyspark Yarn Mode) 실행
-
- Pyspark YarnMode 실행(Default)
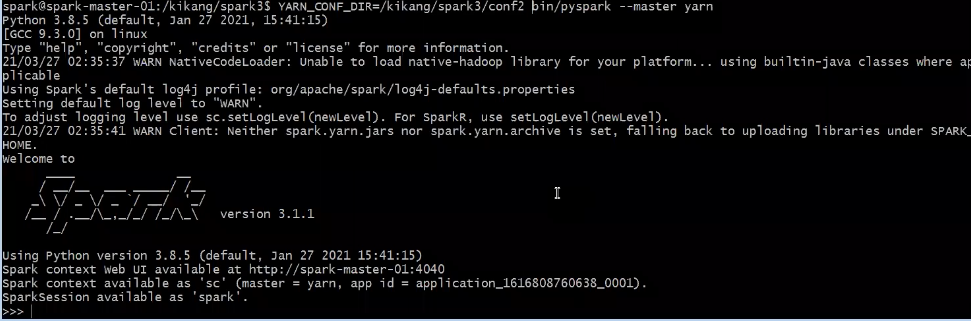
- Pyspark YarnMode 실행(Default)
-
- 해당 Application 상세정보 확인
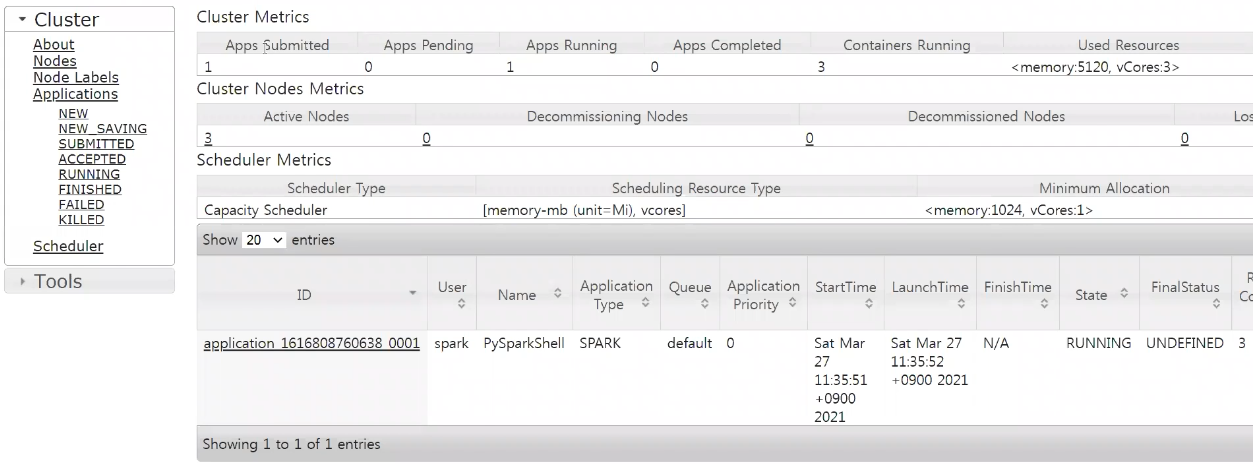
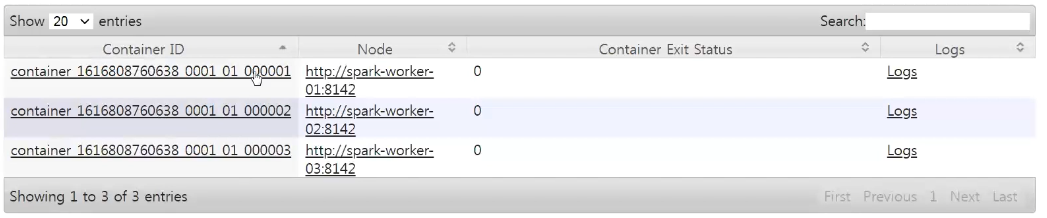

- 해당 Application 상세정보 확인
-
- 3개의 Executor가 동일한 메모리를 가지지 않는 이유는 ?
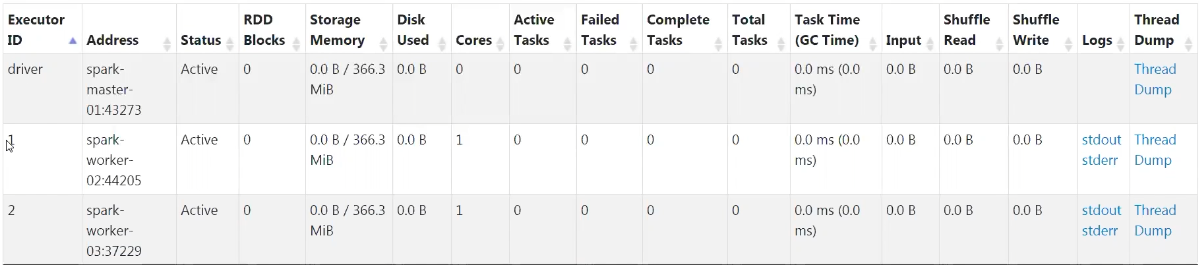
→ Spark Driver는 기본적으로 1G/1Core로 생성이되고 , Executor들은 메모리(오버헤드 1G) 붙은 상태로 생성이 됨
- 3개의 Executor가 동일한 메모리를 가지지 않는 이유는 ?
-
- Pyspark YarnMode 실행(Memory 2G/Core 2/Executor 4)


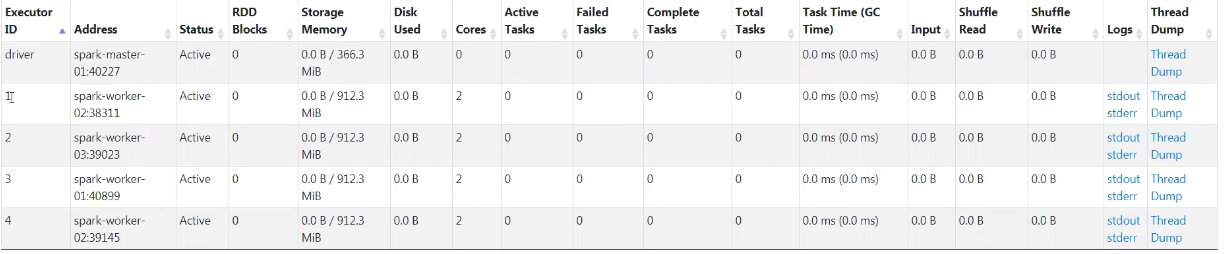
- Pyspark YarnMode 실행(Memory 2G/Core 2/Executor 4)
-
- 해당 Application 실행 상황을 보면 Executor 4개(Memory 3G(Overhead +1)/Core 2) , Spark Driver(Memory 1G/Core 1) 구동된 걸 확인 할수 있음
-
Apache Spark(Pyspark Yarn Mode) 로컬 데이터 연산 실습
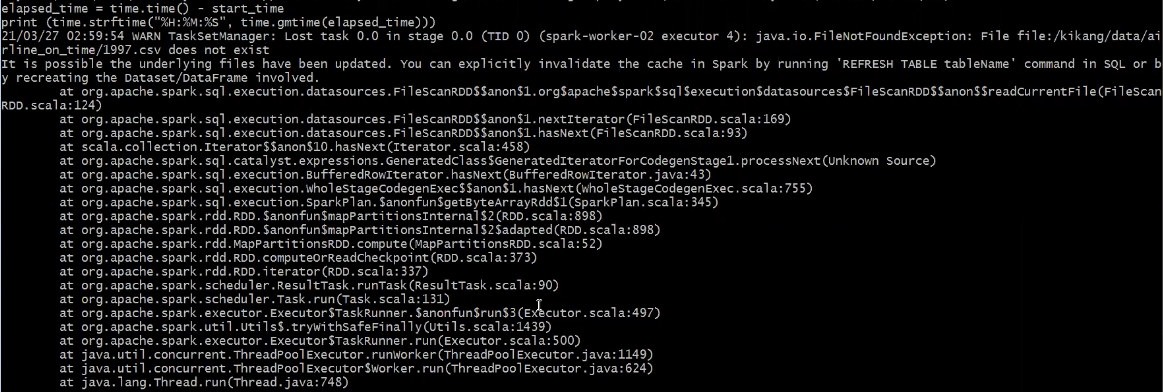
→ FileNotFoundException 발생 이유 : 데이터를 병렬 처리로 처리 도중 2번 WorkNode에서 1997.csv 파일을 찾지 못해 발생한 오류. 해당 파일을 모든 WorkNode에 카피 후 다시 실습 진행
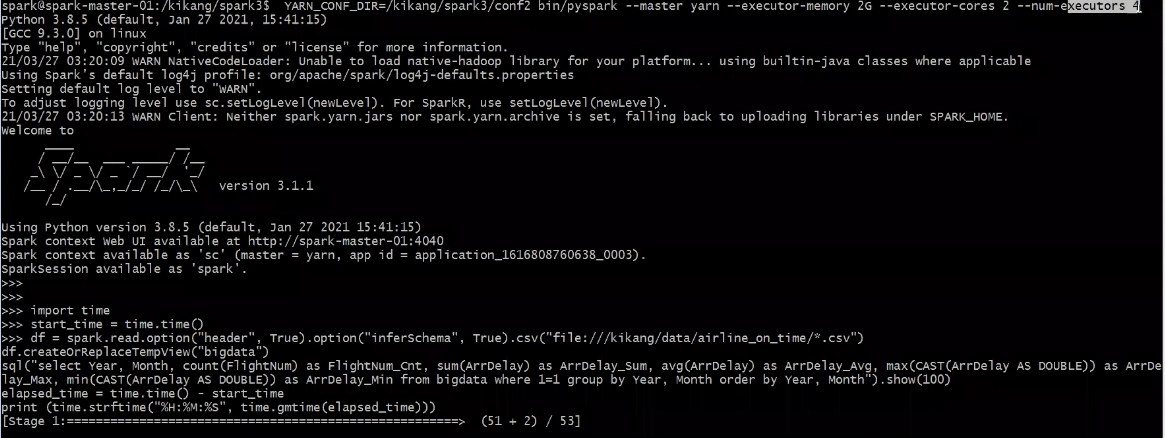
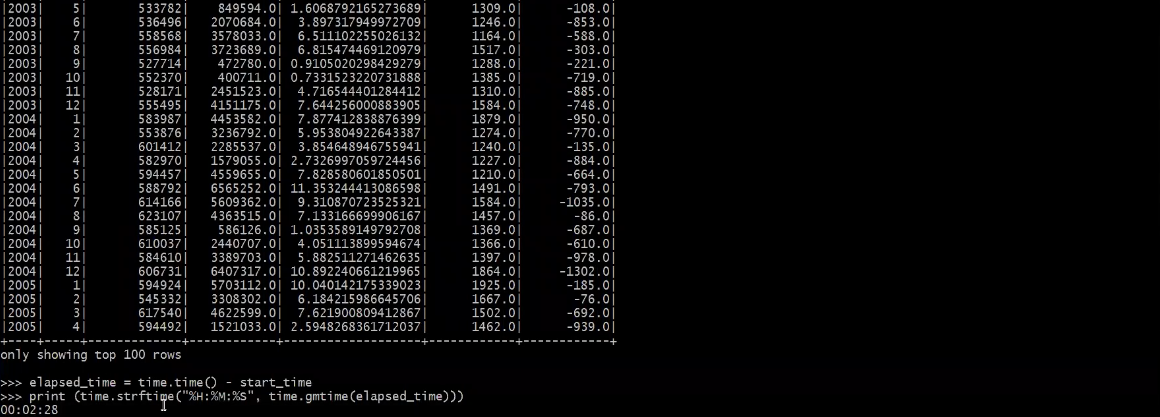
오류 없이 작업이 성공하였고, 앞선 실습(Pyspark Local Mode)에서 싱글노드 환경에서 작업을 실행했을 때와 처리속도가 3배이상 차이가 발생함.
분산 처리 과정
Spark Driver가 분석 파일을 읽고 Hadoop Block Size(128MB) 만큼 나눠서 WorkNode Executor에 배분
각 데이터 작업 완료 후 노드별로 데이터 집계를 진행(집계 진행 시 네트워크 통신을 통해 데이터 이동이 발생하기에 남발되면 속도가 저하됨)
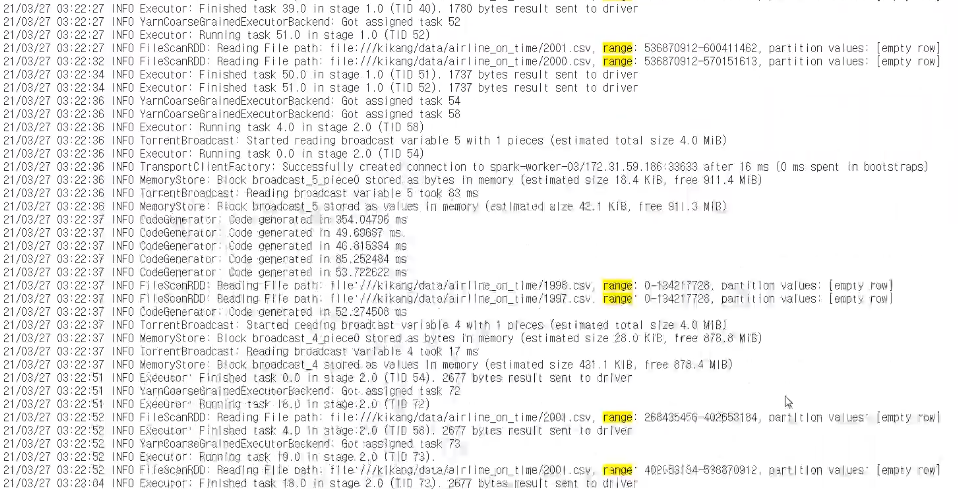
-
Apache Spark(Pyspark Yarn Mode) Hadoop 데이터 연산 실습
앞서 데이터 연산 실습한 데이터를 Local 아닌 Hadoop 올려 실습 진행
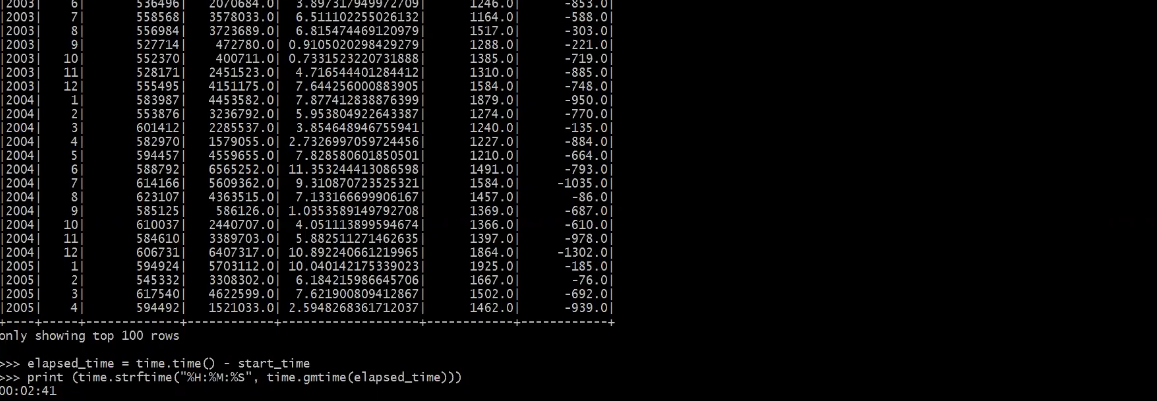
-
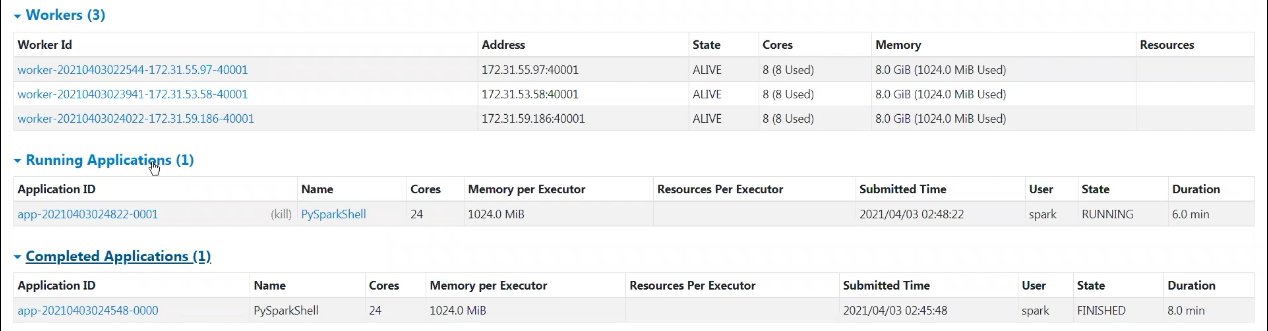
Apache Spark(Pyspark Standalone) 실행(Default)
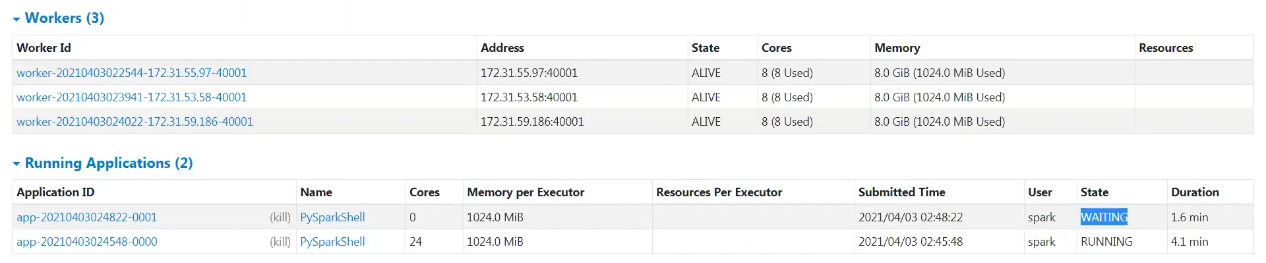
Standalone 모드에 경우 Core수를 주지않으면 전부 할당됨. Executor Memory의 경우는 1G 할당.
2번째로 실행된 Application는 1번째로 실행된 Application이 Core 자원을 전부할당받아 사용중이기에 반환할 때까지, 대기하게 됨.
1번째 어플리케이션 완료 후 회수받은 자원으로 2번째 Application이 실행되는 것을 확인할 수 있음.
-
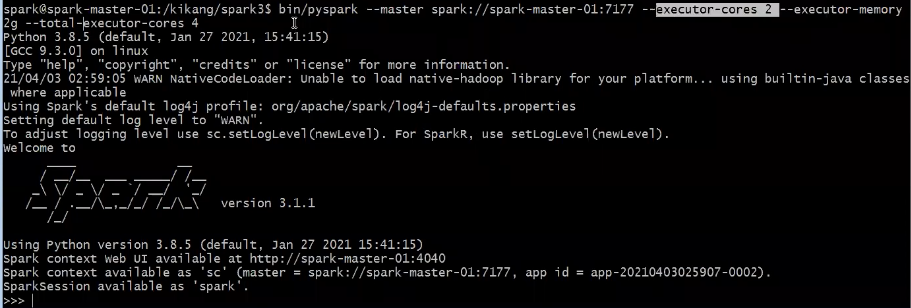
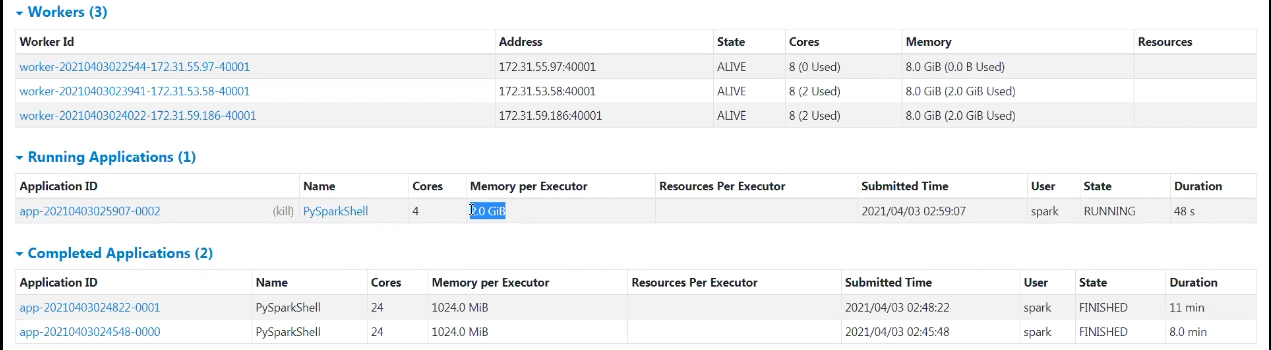
Apache Spark(Pyspark Standalone) 실행(Core 2/Memory 2G/Executor 4)
Zepplin 환경 실습
-
Spark RDD 와 Spark DataFrame 비교

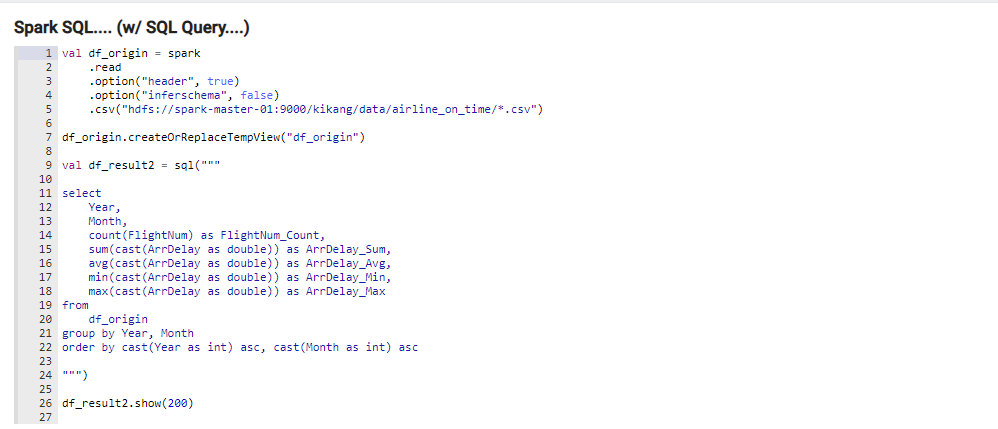
둘다 작업 속도는 차이가 없음(SparkSQL도 결국은 내부적으로 RDD로 작업이 수행되기 때문)같은 데이터 처리 작업을 하는 코드이지만 직관성면에서 차이가 큼. -
Spark Join(Shuffle/Broadcast) Network 통신방식 차이
-
- Shuffle Join
전체 노드 간 통신을 유발
셔플 조인은 전체 노드 간 통신이 발생
그리고 조인에 사용하는 특정 키나, 키 집합을 어떤 노드가 가졌는지에 따라 해당 노드와 데이터를 공유
네트워크 복잡해지고 많은 자원 사용
즉, 전체 조인 프로세스가 진행되는 동안 모든 워커 노드에서 통신이 발생
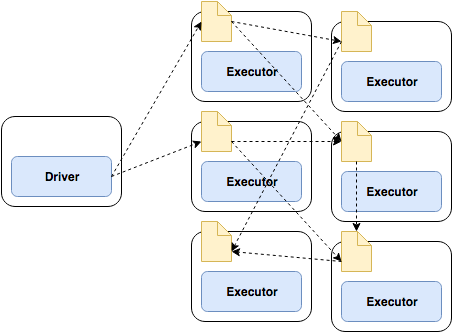
- Shuffle Join
-
- Broadcast Join
테이블이 단일 워커 노드의 메모리 크기에 적합할 정도로 충분히 작다면, 조인 연산 최적화가능
브로드케이스 조인으로, 작은 Dataframe을 클러스터의 전체 워커노드에 복제
자원을 많이 사용하는 것 처럼 보일 수 있지만, 조인 프로세스 내내 전체 노드가 통신하는 현상을 방지 할 수 있음
조인 시작 시, 단 한번만 복제가 수행되고, 그 이후로는 개별 워커가 다른 워커를 기다리거나 통신할 필요없이 작업 수행
브로드케이스 조인은 이전 조인과 마찬가지로 대규모 노드 간 통신 발생
하지만 그 이후로는 노드사이의 추가적인 통신 발생하지 않음
따라서 모든 단일 노드에서 개별적으로 조인이 수행되므로, CPU가 큰 병목구간이 됨
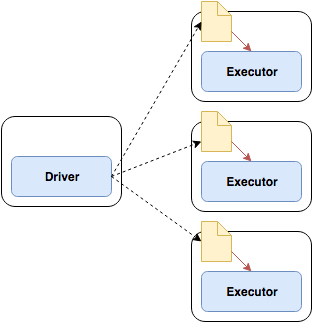
- Broadcast Join
-
Spark Cache / persist
cache() 와 persist는 첫 Action 실행 후 RDD 정보를 메모리 또는 디스크에 저장해 다음 Action 수행할 때 불필요한 재생성 필요없이 원하는 작업 즉시 실행할 수 있게 해주는 메소드
cache() 메서드와 persist()메서드는 둘 다 로드된 데이터를 저장공간상에 올려두는 작업을 하며,
RDD.cache()는 persist(StorageLevel.MEMORY_ONLY)
DF_cache()는 persist(StorageLevel.MEMORY_AND_DISK) 로 작동한다.
DF.cache()는 df.persist(StorageLevel.MEMORY_AND_DISK) 와 같다고 볼 수 있다.
1.cache()
RDD 데이터를 메모리에 저장하고, 만약 저장 메모리 공간이 충분치 않다면 부족한 용량만큼 저장하지 않음.2.persist()
StorageLevel Option을 통해 저장위치(메모리/디스크)와 저장방식(직렬화여부) 등 상세히 지정할 수 있는 기능 제공. -
RDD Cache vs DataFrame Cache
강의 때 무조건 데이터프레임 캐시가 좋다고하셨는데 찾아보고 추후 기재예정.

