Spark
1.Spark Partition
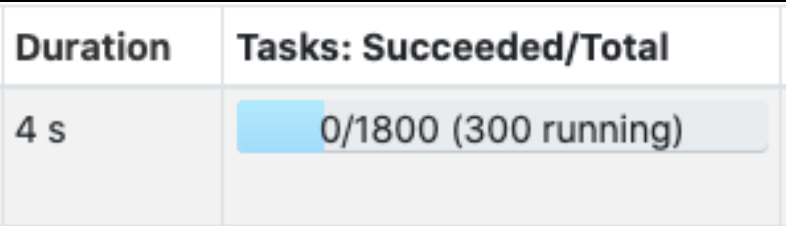
Partition은 RDDs나 Dataset를 구성하고 있는 최소 단위 객체이다. 각 Partition은 서로 다른 노드에서 분산 처리된다.Spark에서는 하나의 최소 연산을 Task라고 표현하는데, 이 하나의 Task에서 하나의 Partition이 처리된다. 또한,
2.Apache Spark
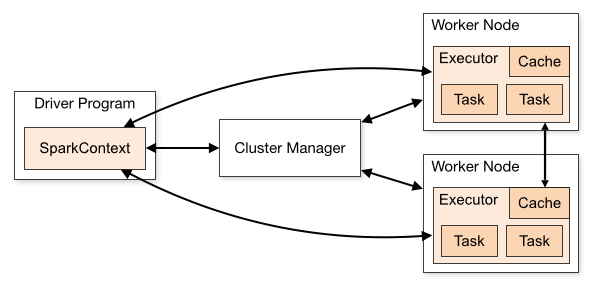
패스트 캠퍼스를 통해 Apache Spark를 이용한 빅데이터 분석 입문 과정 교육을 정리했던걸 옮겨보자 한다.Apache Spark는 대용량 데이터를 다루기 위한 빠르고 범용적인 인메모리 기반 클러스터 컴퓨팅 엔진In-Memory 기반 기술이라는 점 중요!Disk에서
3.Apache Spark 실습
spark 개인적 실습했던 내용을 옮겨보고자 한다. 서버 스펙 : 4대 서버(Mater Node 1대 / Worker Node 3대) 테스트 데이터 : 테스트 데이터 6.5G 작업 내용 : 테스트 데이터 GroupBy/Aggregate 연산 진행실습 Apache Spa
4.Spark Standalone 구성

회사 내부적으로 Spark을 사용하여 프로세스를 처리할 일이 생김.기존에는 CDP,HDP,CDH 등 빅데이터 클러스터 환경에 구축되어 있는 Spark 사용하여 작업을 했지만 해당 Spark은 Hadoop 환경에 귀속이 되어있기에 해당 종속성을 최대한 제거한 채로 환
5.Spark RDD & BlockManager 내부 구조
Spark에서 파일을 읽으면,Executor가 파일 블록을 읽어 자신의 BlockManager 메모리(또는 디스크) 에 저장하고,Driver의 BlockManagerMaster는 그 위치와 상태를 논리적으로 기록합니다.Driver는 데이터를 직접 들고 있지 않고, 오직
6.Spark 전체 계층 구조
───────────────────────────────────────────────User API 계층───────────────────────────────────────────────• Spark SQL, DataFrame, Dataset, RDD API─────
7.Spark Declarative Pipelines
예전회사에서 있을때부터 테스트하고, 작성해야하지 말만 하고 정리안했던 Spark Declarative Pipelines 내용에 대해서 정리해본다. > Apache Spark 4.0(Spark Connect 기반)과 함께 공식화된 Declarative Pipelines