튜닝 종류
- RDBMS 튜닝 종류는 크게 아래와 같이 나뉨
- 파라미터 튜닝
- JOIN 전략
- 인덱스 전략
- 데이터 아키텍처 전략
- SQL 튜닝
파라미터 튜닝
- 각 작업 별 주로 설정하는 파라미터를 위주로 설명
- DB 파라미터 튜닝
variables value 설명 innodb_buffer_pool_size 1GB (default) → 증가 클 수록 쿼리 실행 시간 단축 (OS RAM의 80%) innodb_log_file_size 134MB (default) → 증가 클 수록 쿼리 실행 시간 단축 (OS RAM의 80%) innodb_log_buffer_size 8MB (default) → 유지 또는 128MB 로 증가 large transaction을 수행할 때 필요 innodb_flush_method O_DIRECT (default) → 유지 [ fdatasync ] DB -> OS캐시 -> DataFile
[ O_DIRECT ] DB -> DataFile
innodb_buffer_pool 설정으로, OS캐시를 사용하지 않아도 때문에(중복 저장으로 인한 메모리 낭비) O_DIRECT로 사용innodb_flush_log_at_trx_commit 1 (default) → 유지 1은 트랜잭션 즉시 처리
0은 트랜잭션을 모아 1초 간격으로 처리key_buffer_size 16MB (default) → 유지 메모리에 있는 인덱스 블록에서 사용되는 버퍼의 크기 - Query 파라미터 튜닝
value 설명 join_buffer_size 262KB join 쿼리에서 사용하는 버퍼 크기 optimizer_switch 최적화 관련 여러 옵션들이 있음 (index, join 등) - 서버 파라미터 튜닝
value 설명 have_query_cache NO query_cache_size thread_cache_size query_cache_type thread_cache_size 9
JOIN 전략
- 적절한 Join type을 사용해야 함
- INNER/OUTER/FULL OUTER JOIN
- Join Method는 일반적으로 데이터베이스 시스템의 옵티마이저에 의해 선택됨
- Nested loop join
- Hash join
- Sort merge join
인덱스 전략
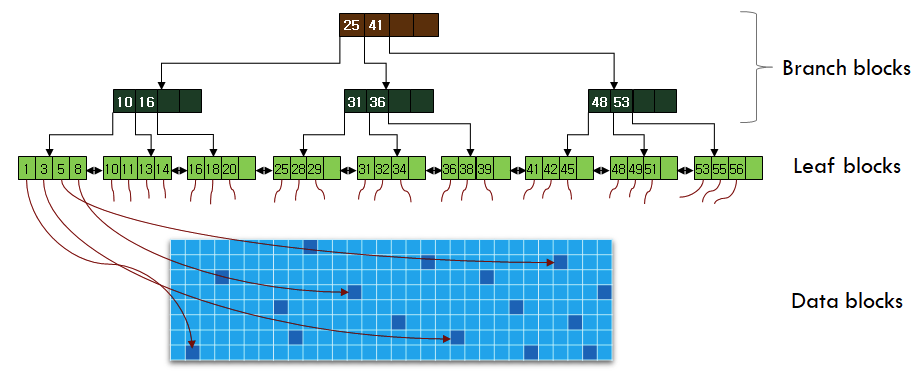
- MySQL InnoDB 엔진은 인덱스 트리 구조를 B tree 구조를 사용하여 테이블의 컬럼 값을 사용 해 데이터 위치를 검색
- 컬럼의 값을 B-Tree 구조체에 입력하고 Root node부터 Leaf node까지 짧은 액세스 단계를 거쳐 특정 row를 빠르게 찾을 수 있게 됨
-
인덱스 설정 기준
- 수정이 되지 않는 컬럼
- 조회 시 WHERE 절에 잘 들어가는 컬럼 선택
- Cardinality가 높은 컬럼(유니크한 컬럼 값, uid)
- 인덱스로 설정이 되는 컬럼은 순서가 빠를 수록 성능이 좋음 (인덱스의 블록 액세스 최소화)
-
인덱스 스캔 종류
1. range
- B-Tree 수직 탐색 후 leaf node level에서 필요한 범위까지 탐색 (leaf는 Linked list로 연결되어 있음)
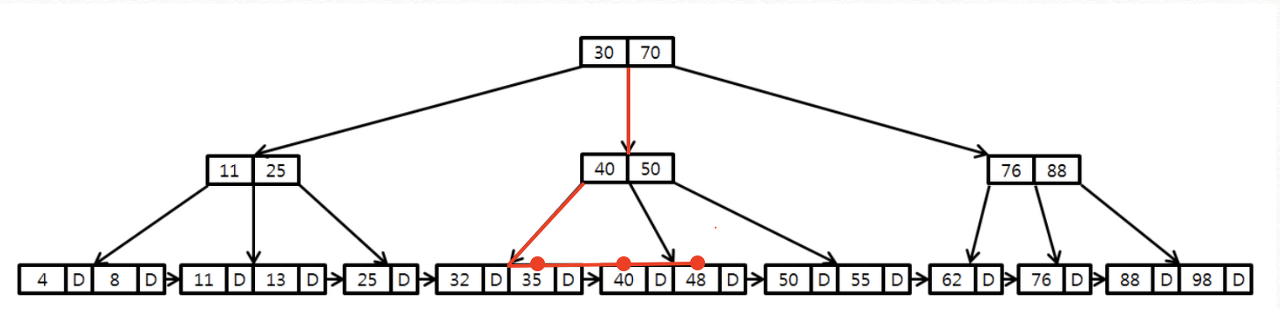
- 범위 조건 설정 시 (<, >, BETWEEN, IS NULL, IS NOT NULL 등) range scan 수행
SELECT * FROM table1 WHERE table1_id > 1;- full
- 인덱스에 저장된 데이터를 full scan
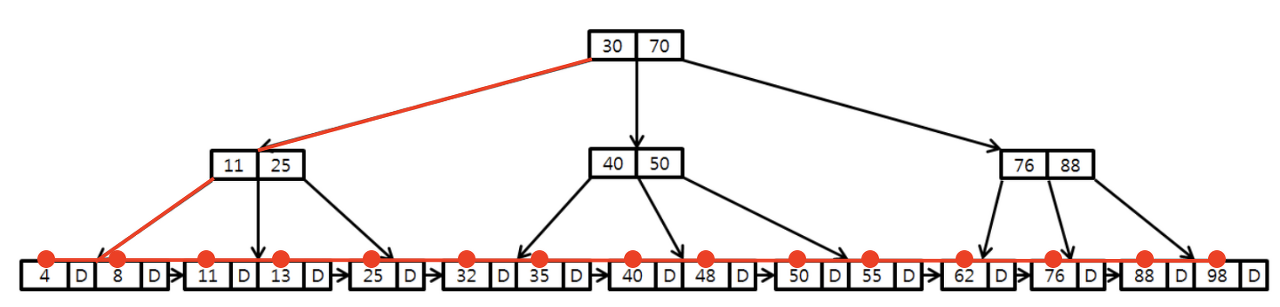
SELECT COUNT(*) FROM table1;- unique
- 쿼리 수행 시 하나의 값만 반환된다는 것을 보장할 때 사용
- PK나 Unique로 설정된 컬럼 조건을 상수값 또는 동등 조건으로 주었을 때 수행됨
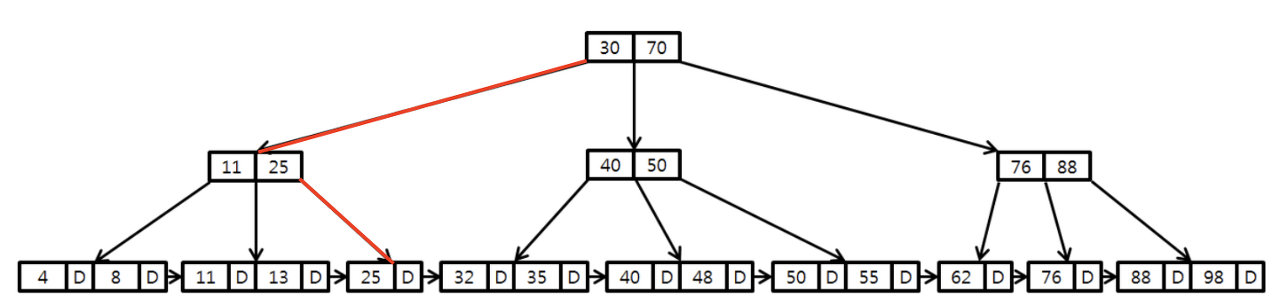
SELECT * FROM table1 WHERE table1_id = 25;데이터 아키텍처 전략
- 데이터 아키텍처에서 고려해야 할 항목들
- 데이터 요구 분석
- 데이터베이스 종류 및 저장 엔진 선택 (RDBMS, NoSQL, Graph DB / InnoDB 등)
- 데이터 표준화, 모델링, Relation, 명명 규칙,
- 사용자 계정 권한 및 접근 제어 정책
- 데이터 보관 주기, 로그 관리, 백업 전략
- 파티셔닝
- 정의 : 크기가 큰 테이블을 관리하기 용이하도록 작은 단위로 쪼개서 저장하는 단위
- 종류
2-1. range
- 컬럼 값의 범위 기준 (예: 연도별 범위 2020.01.01~2020.12.31)
2-2. list
- 컬럼 값이 Key(Enum)인 경우 (예: Spring, Summer)
2-3. hash
- Range, List로 균등하게 나누기 어려운 경우 사용
(patition 갯수만 설정하면 MySQL이 테이블을 훑고 알아서 나눠줌)
- View와 UDF(User Define Function) 사용 최소화
2-1. 보안을 위한 View외의 무분별한 View 생성은 최소화- UDF (예: 스칼라 서브 쿼리)는 과도한 블럭 액세스 유발할 수 있음
- 데이터 모델 변경
- d데이터 모델이 변경되지 않도록 초기 설계 단계에서 최대한 모델링을 잘 정리해야 함
SQL 튜닝
- SQL의 성능 판단 기준은 실행 시간과 블럭 액세스 횟수
- 옵티마이저가 항상 최적의 실행 계획을 수립해주지 않는 경우가 있기 때문에 Hint를 사용하는 방법도 있음
-
Hint
USE 키워드: 특정 인덱스를 사용하도록 권장IGNORE 키워드: 특정 인덱스를 사용하지 않도록 지정FORCE 키워드: USE 키워드와 동일한 기능을 하지만, 옵티마이저에게 보다 강하게 해당 인덱스를 사용하도록 권장USE INDEX FOR JOIN: JOIN 키워드는 테이블간 조인뿐 아니라 레코드 검색하는 용도까지 포함USE INDEX FOR ORDER BY: 명시된 인덱스를 ORDER BY 용도로만 사용하도록 제한USE INDEX FOR GROUP BY: 명시된 인덱스를 GROUP BY 용도로만 사용하도록 제한
SELECT * FROM TABLE1 USE INDEX (COL1_INDEX, COL2_INDEX) WHERE COL1=1 AND COL2=2 AND COL3=3; SELECT * FROM TABLE2 IGNORE INDEX (COL1_INDEX) WHERE COL1=1 AND COL2=2 AND COL3=3; SELECT * FROM TABLE3 USE INDEX (COL1_INDEX) IGNORE INDEX (COL2_INDEX) FOR ORDER BY IGNORE INDEX (COL3_INDEX) FOR GROUP BY WHERE COL1=1 AND COL2=2 AND COL3=3; -
악성 쿼리 수정
- 동일한 테이블 여러번 액세스 하는 경우
- 스칼라 서브쿼리 - 적절한 JOIN문을 사용하지 않고 SELECT문에 무분별한 스칼라 서브쿼리를 사용
- DB 함수 사용 → DATE 관련 함수, CASE WHEN 함수, Converting 함수 등 API서버에서 처리할 수 있는 부분은 비즈니스 로직으로 처리
