메모리 문제는 주로 딥러닝 모델을 학습하거나 추론할 때 발생하는 GPU의 메모리(RAM) 부족으로 인해 발생한다.
1. GPU와 RAM
-
GPU (Graphics Processing Unit): 딥러닝에서 계산을 빠르게 수행하기 위해 사용하는 프로세서이다. 특히 병렬 처리가 뛰어나므로 대규모 데이터 연산에 적합하다.
-
GPU RAM (메모리): GPU가 작업을 처리할 때 필요한 데이터를 저장하는 메모리이다. 딥러닝에서 이미지, 텍스트 등의 데이터는 모두 GPU 메모리에 적재되는데, 이 메모리가 부족하면 Out of Memory (OOM) 에러가 발생한다.
2. GPU RAM에서 발생하는 문제
- 모델 크기: 딥러닝 모델의 크기가 클수록 메모리 사용량이 증가한다. 대형 모델을 사용할 경우 GPU RAM이 이를 감당하지 못할 수 있다.
- 배치 크기: 모델이 한 번에 처리해야 하는 데이터의 크기(배치)가 클수록 더 많은 메모리를 사용한다.
해결 방법:
1. 모델 축소
모델의 파라미터 수를 줄이거나, 더 작은 모델을 사용하는 방법이 있습니다.
2. 배치 크기 축소
배치 크기를 줄이면 한 번에 처리하는 데이터 양이 줄어들어 메모리 사용량을 감소시킬 수 있다.
3. 양자화(Quantization)
원리: 양자화는 모델의 가중치나 입력값을 더 작은 비트 크기로 변환하여 메모리 사용량을 줄이는 기술입니다. 예를 들어, 32비트 부동소수점(FP32) 대신 16비트(FP16) 또는 8비트(INT8)로 표현하여 메모리를 절약할 수 있다.
Weight의 개별 parameter 값을 표현하는 방식을 변경해서 메모리 사용량을 감축한다.
- 일반적인 실수의 표현 방식 : 32bit Floating-point number
- 숫자 1개를 표현하기 위해 4Byte 소모 - 양자화 표현 방식 : 16bit Floating-point number
- 숫자 1개를 표현하기 위해 2Byte 소모
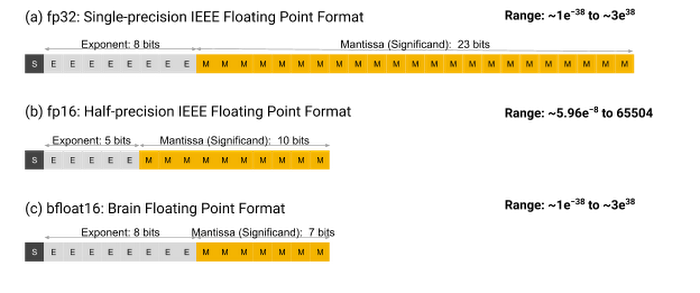
장점: 메모리 절약, 연산 속도 증가.
단점: 모델 성능이 약간 감소할 수 있지만, 잘 설계된 양자화 기법을 사용하면 성능 저하를 최소화할 수 있습니다.
4. Gradient Accumulation
원리: 모델 학습 중 배치 크기를 줄이면 메모리 사용량은 줄지만 학습 속도가 느려질 수 있습니다. Gradient Accumulation은 작은 배치를 여러 번 반복하여 기울기를 누적한 후, 한 번에 업데이트하는 방식입니다. 이렇게 하면 큰 배치 크기를 사용하는 것과 같은 효과를 얻을 수 있지만, 메모리 사용량은 줄어든다.
과정:
1. 작은 배치에서 각 미니배치마다 기울기를 계산.
2. 기울기를 누적하여 저장.
3. 일정 횟수마다 (누적 후) 한 번에 가중치를 업데이트.
장점: 적은 배치로도 큰 배치 효과를 얻을 수 있음
5. LoRA (Low-Rank Adaptation)
원리: LoRA는 기존의 대규모 모델을 사용할 때, 전체 모델을 업데이트하지 않고, 저차원(낮은 랭크)의 매트릭스만을 업데이트하는 방식. 이를 통해 모델의 메모리 사용량을 크게 줄이면서도 성능을 유지할 수 있다.
과정: 원본 모델은 고정. 작은 부가적인 매트릭스만 학습하면서 성능을 유지.
단점: 성능이 많이 안좋을 수 있음
6. Gradient Checkpointing
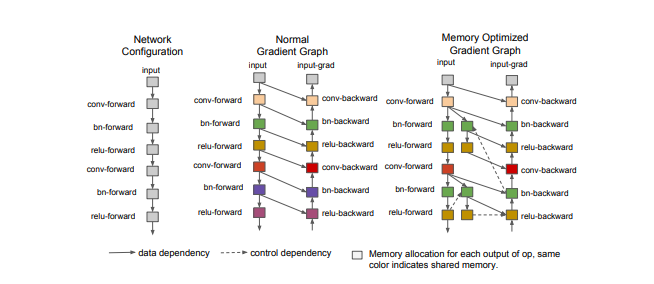
원리: Forward pass에서 계산한 weight들을 모두 저장하면 메모리 사용량이 커진다. 이 중 일부 중간 값만 저장하고 나머지는 필요할 때, 다시 계산하도록 해서 메모리 사용을 줄인다.
장점: 메모리를 줄일 수 있어서 큰 모델을 사용할 수 있다
단점: 다시 계산해야해서 속도가 느려진다
7. CPU Offloading
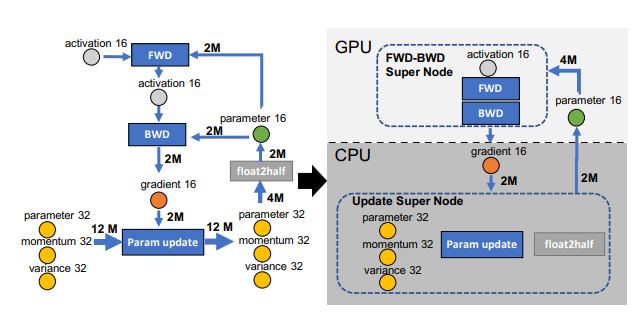
원리: 모든 계산을 GPU를 쓰는 대신, 일부 데이터를 CPU로 옮기는 방법.
장점: 비용효율적인 CPU 메모리 활용.
단점: 성능 저하가 생길 수 있음
