[Upstage AI Lab]
1.[Upstage AI Lab] OT 후기

1일차 3기는 약 80~90명 정도 인원이 함께 하게 되었다 인원을 신경써서 선발했다고 하지만 웬만해서는 다 붙여준 것 같다 (지원할때 AI 기본 지식과 코딩테스트를 구글폼으로 제출하는데 결과에 대해 걱정하지는 않아도 될듯) 그래도 질문이나 자기소개를 들어보면 대부분
2.[Upstage AI Lab] python basics

파이썬 헷갈리는/유용한 문법
3.[Python] SRT 자동예매

python으로 SRT 티켓 자동 예매
4.[Python] Playstore 댓글 크롤링
어플 댓글들을 수집해보자
5.[Python] FAST API란?

API가 뭔지 알아보자FAST API : 이미지 분류, database CRUD 구현SLACK API : slack bot으로 메시지 보내기
6.[Upstage AI Lab]

주요 개념들을 정리해보자RAG StreamlitscheduilingFAST API데이터베이스OLLAMA - local에서 모델 돌릴 수 있음call back과 webhook 차이API
7.[Python] 슬랙봇 만들기
AI times, kaggle crawling기상청 API 호출미세먼지 API 호출GPT 전달Slack 으로 전달 Fast API 서버 구축
8.Git, Github, Git bash
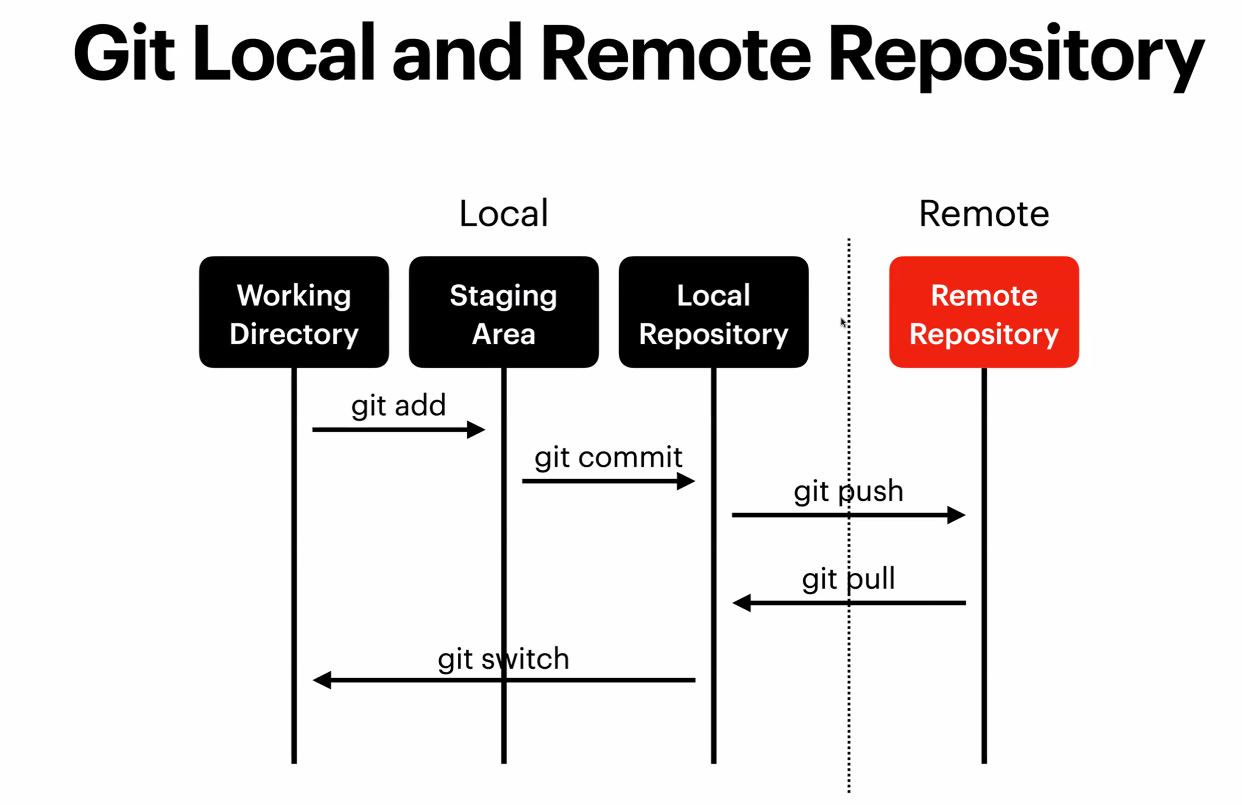
pwd: 현재 작업 중인 디렉토리 확인ls: 파일과 객체 목록 확인ls -a: 숨겨진 파일까지 모두 보기mkdir: 폴더 생성touch: 파일 생성mv README.md dest: 파일을 다른 위치로 옮기기mv ../\*.py ./: 상위 디렉토리의 모든 파이썬 파일을
9.[통계학] ANOVA, T-test, p-value, MLE, Post-hoc analysis
T-test: 두 집단 평균이 동일한지 비교 두 분포가 정규분포를 따르고 등분산성을 가질 때 (두 집단이 같은 분산을 가짐) 독립표본(independent) t test: 서로 다른 변인에 대한 결과 비교 대응표본(paired sample) t test
10.[python] 탐색적 데이터 분석(EDA : Exploratory Data Analysi)
pd.read_excel()의 argument에는 다음의 것들이 있다. sheet_name : 엑셀의 몇번째 sheet를 가져올지 header : 몇번째 행을 column으로 할지 index_col : 몇번째 열을 index으로 할지 header , index_col
11.[Upstage AI Lab] Deep Learning

Gradient descent는 주어진 데이터셋에 대해 손실 함수(Loss)를 최소화하기 위한 최적화 알고리즘이다. 모든 샘플에 대해 손실을 계산하고 이를 기반으로 가중치를 업데이트한다. 하지만 모든 샘플을 사용하여 계산하면 연산량이 너무 많아진다. 이 문제를 해결하기
12.[Upstage AI Lab] K-fold cross validation

Validation을 선택할 때, 똑같은 데이터로만 split 할 경우 성능을 측정하는 일반화 성능이 떨어진다. 왜냐하면 train 데이터를 랜덤으로 추출한 80%의 데이터로 정할 때와 다른 데이터 80%를 학습할 때의 성능이 다를 수 있기 때문이다. 마찬가지로 val
13.[Upstage AI Lab] AutoEncoder
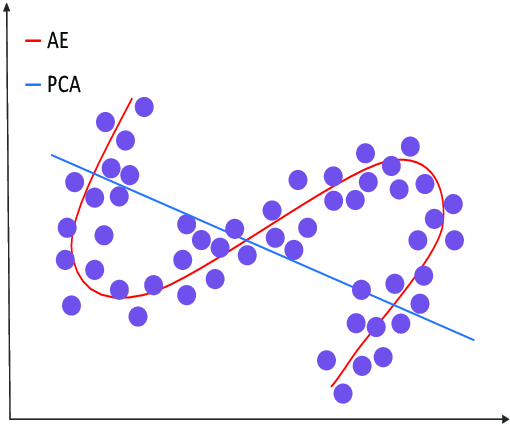
오토인코더를 한마디로 정의하자면 딥러닝 기반의 비지도학습 방법이다. Input 데이터의 차원을 축소하는 Encoder와 이를 다시 복원하는 Decoder로 이루어져있다. 입력과 출력이 똑같은 구조로 무엇을 하나 싶을 수 있지만 활용범위가 굉장히 넓다.주로 사용되는 것은
14.MLE(Maximum Likelihood Estimation)
베이즈정리에서 사후확률을 구할 때, 가능도를 이용해서 구하는 것을 알 수 있다. 여기서 나오는 가능도를 최대화 한다는것은 우리가 원하는 데이터가 '어떤 확률 분포'에서 가장 잘 나올법한지 찾는것 의미한다.즉, 어떤 parameter가 그 데이터를 가장 잘 설명하는 데이
15.[Error] ModuleNotFoundError: No module named 'yaml'
yaml은 모델의 config 파일을 저장하는 형태다.야믈,야멀 로 발음한다 pip install yaml 하면 설치가 안된다.다음과 같이 설치해야 한다.pip install pyyamljson 파일 보다 가독성이 좋고 간결해서 많이 쓴다고 한다.
16.[Wandb error] Path is not a directory: ./checkpoint-1170
wandb를 checkpoint로 설정하면 마지막 파일이 저장되지 않고 에러가 발생한다.checkpoint 대신 end를 사용했더니 checkpoint로 저장이 되면서 에러도 발생하지 않았다.ckeckpont : 매 epoch 마다 모델을 저장end : 마지막 epoc
17.[json error]ValueError: Trailing data

오류 상황 :pd.read_json('file.json')json 파일을 pandas로 읽어서 dataframe으로 받으려고 할 때, Trailing data 에러가 발생했다.문제 원인 : SON 파일은 하나의 객체 또는 배열로 묶여 있어야 하는데 구분자 없이 들어가
18.LLM prompt engineering
대화 요약 경진대회에서 LLM을 써보는 시도를 했다.gpt-4.0 API를 쓰다보니 좋은 결과를 위해 prompt engineeering 필요성을 느끼게 되었다. 기왕 유료로 쓰는거 최선의 결과를 얻어야 하기에 prompt engineering을 정리하였다.few sh
19.[Error] Out of Memory
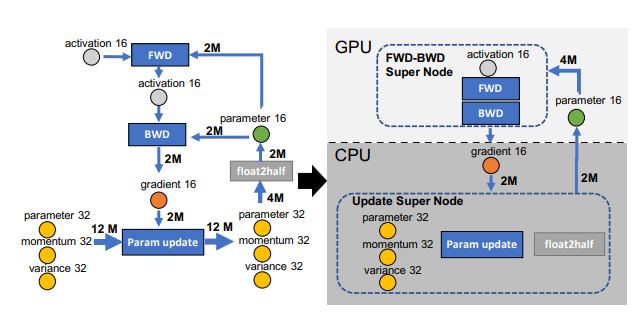
메모리 문제는 주로 딥러닝 모델을 학습하거나 추론할 때 발생하는 GPU의 메모리(RAM) 부족으로 인해 발생한다. 1. GPU와 RAM GPU (Graphics Processing Unit): 딥러닝에서 계산을 빠르게 수행하기 위해 사용하는 프로세서이다. 특히 병렬