코드스테이츠 36,37일차 (07월 20일, 07월 21일)
Same Origin 개념을 이해하다
cors 공부 할 때 same origin이 뭔지 감이 오지 않았다. 그동안 express 서버에서 send메소드 인자에 입력한 'hello world'가 서버를 구동시키는 ip, port 주소를 쳤을 때 나타나는 지 이유를 몰랐다. 서버와 클라이언트는 각자 따로 구현해야 한다는 게 머릿속에 박혀있었다. 국비 학원 다닐 때, 게임 서버와 클라이언트를 따로 두었다. 노마드 강의를 들을 때도 클라이언트와 서버를 나누어서 진행했다. 그 결과 서버와 클라이언트는 무조건 나누어야 한다는 생각이 머릿속에 박혔다.
하지만 서버가 열려있는 ip, port 주소에 html을 띄울 수 있다는 걸 알고 나서는 신세계를 본 기분이었다. 서버는 그저 새까만 터미널에 끊임없이 올라오는 글자들로 가득찬 어떤 것이라 생각했기 때문이다. 서버가 구동중인 ip, port 주소에서 static 파일을 브라우저에 출력하는 것이 곧 same origin이였던 것이다!
리액트도 실은 임의의 서버로 구동 중이라는 것도 알게 되었다. 실제 서버로 옮기기 전 테스트용으로 서버를 돌렸던 거다. 왜 dev-server라는 말이 나오는 지 이해가 된다. 실제 서버에서 구동하기 위해서는 브라우저가 해석할 수 있는 정적 파일 형태로 제공해줘야 하기 때문에 build라는 과정을 거친다. 리액트 dev-server는 그때 그때 변경된 스크립트를 트랜스파일링해주지만 실제 서버는 그런 기능이 없기 때문이다. 부과적으로 build를 하면 코드 압축과 더불어 난독화를 시켜준다.
SPA, client routing with server routing
SPA(Single Page Application) 는 페이지 이동 없이 한 페이지 내에서 사용자의 상호작용에 맞추어 부분적으로 갱신하는 방식이다. 한 페이지라는 말은 url이 고정된다는 말이다. 문제는 앞으로가기, 뒤로가기 기능이 history에 기록된 url을 통해서 이뤄지는데 url이 고정되면 기록을 할 수 없다. 그래서 직접 History API에 접근해서 클라이언트에서만 유효한 fake url을 생성하여 이 문제를 해결한다. 하지만 fake url을 직접 새 창에 입력하면 404에러를 만나게 되는데, 그 까닭은 주소창에 입력된 url은 클라이언트 쪽에서 반응을 하지 않고 서버에 요청을 보내기 때문이다. 서버에서는 해당 url을 처리할 로직이 없으므로 404에러를 보낸다. 따라서 클라이언트에서 만들어낸 url을 서버에서도 라우트 시켜줄 필요가 있다. 페이지는 동일하기 때문에 같은 html을 response해주면 클라이언트측에서 자동으로 라우팅해준다.
const express = require('express');
const path = require('path');
const app = express();
// static 설정을 해주지 않으면 빈 페이지만 랜더링 된다.
// public 폴더 내의 모든 정적 파일 접근이 가능해진다.
// 주소창에 http://localhost:8080/index.html을 치면 화면에 랜더링이 된다.
app.use(express.static(path.join(__dirname,'public'));
app.get('/', (req,res)=>{
res.sendFile(path.join(__dirname,'public','index.html'));
}
app.listen(8080,()=>{
console.log('server listening on http:localhost:8080');
});
클라이언트에서 request의 body에 담겨진 email에 응답 메일을 보내는 기능을 구현하다가 비동기를 사용해야 했는데, 비동기 처리가 생각보다 간단하다. 그저 handler에 async 를 붙여주면 된다.
app.post('/contact', async (req,res) =>{
// 비동기 처리
});
코드스테이츠 38,39,40일차 (07월 22일, 07월 23일, 07월 24일)
드디어 데이터베이스(DB)를 다룬다. 이번 스프린트에서, 필요한 데이터들을 파악하고 데이터 구조를 설계한 후 서버로부터 전달받은 데이터들을 유의미하게 가공하여 저장하거나 요청에 맞게 필터링하여 저장된 데이터를 가져오는 일련의 과정을 배운다. 학원에서 살짝 다뤄본 적이 있고 계속 데이터 처리과정에 흥미가 있어서 기대했다. 물론 첫 날부터 그 기대감이 처참히 무너졌지만 말이다....
mysql 설치부터 애를 먹었다. 몇 번이나 지우고 다시 설치하기를 반복했다. 덕분에 mysql 다루는 것에 온전히 집중을 못해서 아쉬웠다. 살짝 맛보기로 배운건 정말 맛보기에 불과했다는 것도 깨달았다. sql 파일이 어떤 기능을 하는지 파악을 못했고 JOIN 개념이 어려웠다. 처음 진입이 어려웠지 테스트를 한 번 통과한 뒤부터는 스피드하게 문제를 풀었다.
다음주에 배울 ORM(쿼리문을 프로그래밍 언어처럼 쓸 수 있도록 도와준다)이 더 많이 쓸테지만 그 기반을 다뤄보는 것이 배움의 깊이가 더해질 거라 생각한다. 대부분 SELECT와 JOIN이 많이 쓰인다고 하니 이부분만 집중적으로 정리하도록 한다.
Database
1. Database의 필요성
- 데이터베이스는 In-memory 방식과 File I/O 방식의 한계점을 극복하기 위해 고안되었다.
데이터 저장방식
1. In-memory : 서버가 구동되는 동안에만 존재하는 휘발성 메모리에 저장된다.
2. File I/O : fs모듈을 사용하여 file 형태로 저장. 데이터를 불러올 때 파일 전체를 읽은 후 필터링
해야 한다.
3. Database : sql을 사용해서 데이터베이스에 데이터를 추가/수정/삭제를 용이하게 해준다. 영구적으로 데이터를 저장한다.
- SQL(Structured Query Language) : DB에 접근하여 데이터를 조작하는 구문. SELECT columns FROM table_name; 과 같이 특정한 명령어와 패턴을 사용한다.
2. Database 구조
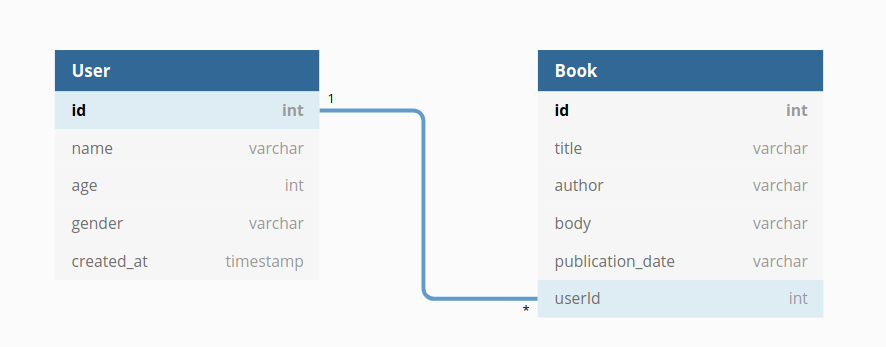
- 데이터베이스는 여러 개의 테이블(entity: 데이터 단위)로 이루어져있다.
- 테이블은 엑셀처럼 columns, rows로 구성되며 각각의 column은 field라 지칭하고 각각의 row는 record라 부른다.
- field : 데이터의 특성, 속성
- record : field에 맞게 입력된 실제 데이터 값

- schema : 테이블의 속성들을 정의하고 각 테이블 간의 관계를 표시
SQL
START
- 데이터베이스 생성 : CREATE DATABASE
<DB이름>;- 생성된 데이터베이스 확인 :
SHOW DATABASES;- 데이터베이스 선택 :
USE <DB이름>;- 테이블 생성 :
CREATE TABLE User( # CREATE TABLE <테이블명> id int NOT NULL auto_increment, # 기본적으로 <field명> <타입>으로 선언, auto_increment 는 자동으로 값을 1증가 시켜줌 email varchar(255) NOT NULL, # NOT NULL 은 record 생성시 비우면 안 되는 필드를 의미 password varchar(255) NOT NULL, profileId int, PRIMARY KEY (id), # 각각의 record를 구별시켜주는 고유값 FOREIGN KEY (profileId) REFERENCES User_Profile(id) # 다른 테이블을 참조할 수 있도록 다른 테이블의 고유값을 연결 );
- 생성된 테이블 확인 :
DESC <테이블명>;
SELECT Statement
- 데이터베이스에서 데이터를 불러올 때 사용
SELECT columns FROM table_name;
SELECT email FROM User; # User테이블에서 email 컬럼에 해당하는 값만 가져오기
SELECT * FROM User; # User테이블에서 모든 컬럼에 해당하는 값 가져오기
SELECT * FROM User WHERE id=1; # User테이블에서 id가 1인 record의 모든 컬럼 값 가져오기
SELECT DISTINCT country FROM User_Profile; # DISTINCT : User_Profile에서 중복된 컬럼 값은 하나로 취급
SELECT COUNT(id) FROM User_Profile WHERE age < 30; # COUNT : User_Profile에서 age 컬럼값이 30이하인 record 수 구하기
SELECT * FROM User_Profile ORDER BY age DESC; # ORDER BY : User_Profile에서 age가 큰 순서대로 출력 ( 기본은 ASC : 작은 순서대로 출력)
SELECT * FROM User_Profile WHERE city='seoul' LIMIT 1; # LIMIT : User_Profile에서 city컬럼 값이 seoul인 record 1개 가져오기
SELECT CONCAT(first_name, ' ' , last_name) AS UserName FROM User_Profile; # CONCAT : 컬럼값 연결시켜 출력, AS : 별칭 지어주기
SELECT * FROM User_Profile WHERE age > (SELECT AVG(age) FROM User_Profile); # AVG : 컬럼값들의 평균값 계산, subquery는 소괄호()를 사용해 묶어준다
- 두 테이블에서 데이터를 불러올 때는 JOIN을 사용한다.
- A INNER JOIN B : 두 테이블이 연결된 값 (B테이블과 연결된 필드가 null이 아닌 값)
- A LEFT JOIN B : 두 테이블이 연결된 값 (B테이블과 연결된 필드가 null이 아닌 값) + A테이블만 있는 값( B테이블과 연결되는 필드값이 null)
- A RIGHT JOIN B : 두 테이블이 연결된 값 (B테이블과 연결된 필드가 null이 아닌 값) +B테이블만 있는 값( A테이블과 연결되는 필드값이 null)
- A FULL OUTER JOIN B : 두 테이블이 연결된 값(B테이블과 연결된 필드가 null이 아닌 값) + A테이블만 있는 값( B테이블과 연결되는 필드값이 null) + B테이블만 있는 값( A테이블과 연결되는 필드값이 null)
# SELECT A테이블의 columns, B테이블의 columns FROM A테이블 INNER JOIN B테이블 ON 조건식
SELECT User_Profile.first_name, User_Profile.last_name, User.email FROM User INNER JOIN User_Profile ON User.profileId = User_Profile.id;
코드스테이츠에서 말한 T(W)IL의 표준을 보는 것만 같네요. bb 잘 보고 있습니다 ㅎㅎ