1. 컬렉션 프레임워크
- 자바는 널리 알려져 있는 자료구조로 객체들을 효율적으로 추가, 삭제, 검색 할 수 있도록 인터페이스와 구현 클래스를 java.util 패키지에서 제공한다. 이들을 총칭해서 컬렉션 프레임워크라고 부른다.
- 주요 인터페이스로는 List, Set, Map이 있다.
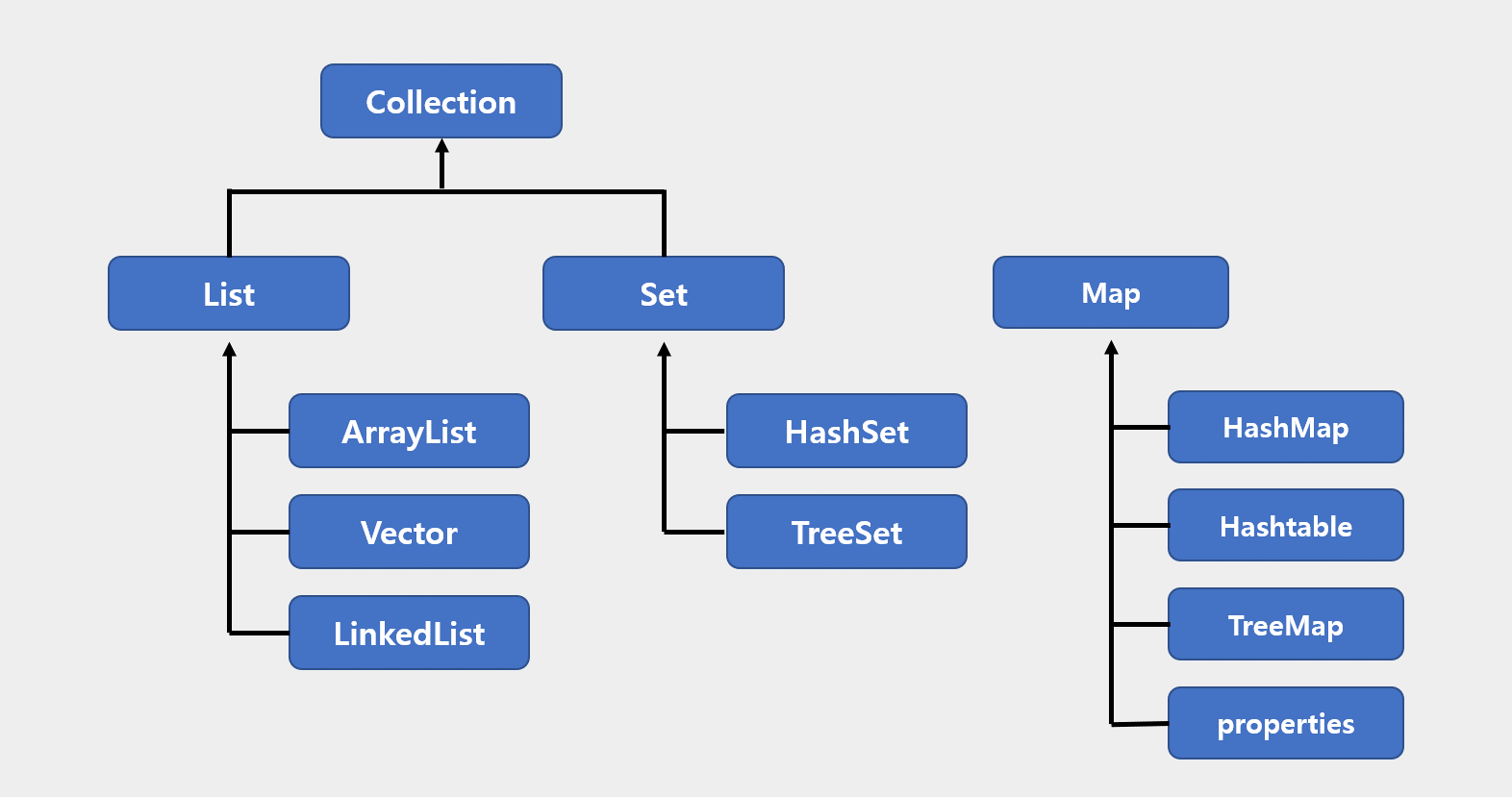
1) List 컬렉션
- 배열과 비슷하게 객체를 인덱스로 관리한다.
- 배열과의 차이점은 저장 용량이 자동으로 증가하며, 객체를 저장할 때 자동 인덱스가 부여된다는 것이다. 그리고 추가, 삭제, 검색을 위한 다양한 메소드들이 제공된다.
- List 컬렉션은 객체 자체를 저장하는 것이 아니라 객체의 번지를 참조한다. 그렇기 때문에 동일한 객체를 중복 저장할 수도 있다. null도 저장이 가능하며, 이 경우에는 해당 인덱스는 객체를 참조하지 않는다.
- ArrayList, Vector, LinkedList 등이 있다.
주요 메소드
객체 추가
- boolean add(E element) : element를 맨 끝에 추가
- void add(int index, E e) : 해당 index에 e를 추가
- E set(int index, E e) : 해당 index에 저장된 객체를 e로 바꾼다.
객체 검색
- boolean contains(Object o) : o가 저장되어 있는지 확인
- E get(int index) : 해당 index에 저장된 객체 리턴
- boolean isEmpty() : 컬렉션이 비어있는지 확인
- int size() : 저장되어 있는 전체 객체 수를 리턴
객체 삭제
- void clear() : 저장된 모든 객체를 삭제
- E romove(int index) : 해당 index에 저장된 객체 삭제
- boolean romove(Object o) : 주어진 객체 o를 삭제
(1) ArrayList
List<String> list = new ArrayList<String>();
List<String> list = new ArrayList<>();
// E 타입 파라미터를 생략하면 왼쪽 List에 저장된 타입을 따라간다.
-
ArrayList에 객체를 추가하면 0번 인덱스부터 차례대로 저장된다.
-
특정 인덱스의 객체를 제거하면 바로 뒤 인덱스부터 마지막 인덱스까지 모두 앞으로 1씩 당겨진다. 마찬가지로 특정 인덱스에 객체를 삽입하면 해당 인덱스로부터 마지막 인덱스까지 모두 1씩 밀려난다.
-
인덱스를 이용해서 객체를 찾거나 맨 마지막에 객체를 추가하는 경우에는 좋은 성능을 발휘한다. 하지만 빈번한 객체 삭제와 삽입이 일어나는 곳에서는 LinkedList를 사용하는 것이 낫다.
(2) Vector
List<E> list = new Vector<E>();
List<E> list = new Vector<>(); -
ArrayList와 동일한 내부 구조를 가지고 있다.
-
다른점은 Vector는 동기화된 메소드로 구성되어 있기 때문에 멀티 스레드가 동시에 Vector의 메소드를 실행할 수 없고, 하나의 스레드가 메소드 실행을 완료해야만 다른 스레드가 메소드를 실행할 수 있다.
-
그래서 멀티 스레드 환경에서 안전하게 객체를 추가, 삭제할 수 있다. 이것을 스레드에 안전하다고 표현한다.
(3) LinkedList
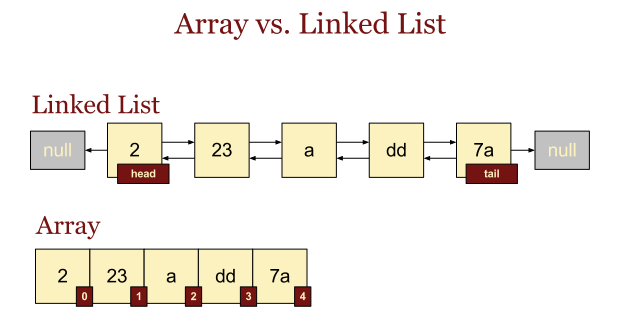
-
ArrayList는 내부 배열에 객체를 저장해서 관리하지만, LinkedList는 인접 참조를 링크해서 체인처럼 관리한다.
-
LinkedList에서 특정 인덱스의 객체를 제거하면 앞뒤 링크만 변경되고 나머지 링크는 변경되지 않는다. 특정 위치의 삽입도 마찬가지이다.
| 구분 | 순차적으로 추가/삭제 | 중간에 추가/삭제 | 검색 |
|---|---|---|---|
| ArrayList | 빠르다 | 느리다 | 빠르다 |
| LinkedList | 느리다 | 빠르다 | 느리다 |
2) Set 컬렉션
- List 컬렉션은 객체의 저장 순서를 유지하지만, Set 컬렉션은 저장 순서가 유지되지 않는다.
- 객체를 중복해서 저장할 수 없고, 하나의 null만 저장할 수 있다.
- HashSet, LinkedHashSet, TreeSet 등이 있다.
주요 메소드
- 인덱스로 관리하지 않기 때문에 인덱스를 매개값으로 갖는 메소드가 없다.
객체 추가
- boolean add(E e) : e를 저장한다. 성공적으로 저장되면 true를 리턴하고 중복 객체면 false를 리턴한다.
객체 검색
- boolean contains(Object o) : 주어진 객체가 있는지 확인한다.
- boolean isEmpty() : 컬렉션이 비어있는지 확인한다.
Iterator<E> iterator(): 저장된 객체를 한 번씩 가져오는 반복자를 리턴한다.- Interator 메소드
- boolean hasNext() : 가져올 객체가 있으면 true 리턴, 없으면 false 리턴
- E next() : 컬렉션에서 하나의 객체를 리턴
- void remove() : Set 컬렉션에서 객체 제거한다. Interator의 메소드이지만, 실제 Set 컬렉션에서 객체가 제거된다.
- int size() : 저장되어 있는 전체 객체 수를 리턴한다
객체 삭제
- void clear() : 저장된 모든 객체를 삭제
- boolean remove(Object o) : 주어진 객체를 삭제
1) HashSet
Hash<E> set = new HashSet<E>();- 객체들을 순서 없이 저장하고 동일한 객체는 중복 저장하지 않는다.
- hashCode() -> equals() 결과가 true면 동일한 객체로 판단한다.
- 위의 특성을 이용하여 hashCode()를 적절하게 오버라이딩 한다면, 매개값이 같은 객체의 중복 저장을 피할 수 있다.
3) Map 컬렉션
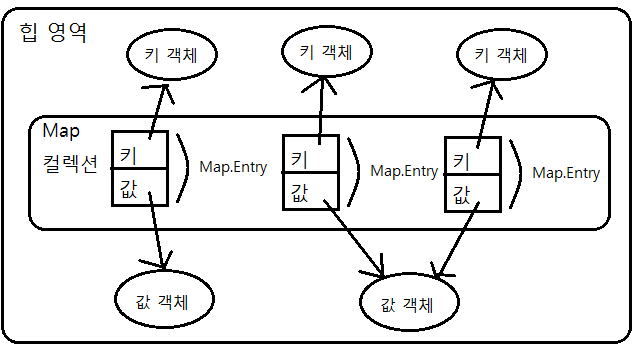
- 키와 값으로 구성된 Map.Entry 객체를 저장하는 구조를 가지고 있다.
- Entry는 Map 인터페이스 내부에 선언된 중첩 인터페이스이다.
- 키는 중복 저장될 수 없지만 값은 중복 저장될 수 있다. 만약 기존에 저장된 키와 동일한 키로 값을 저장하면 기존의 값은 없어지고 새로운 값으로 대체된다.
- HashMap, Hashtable, LinkedHashMap, Properties, TreeMap 등이 있다.
주요 메소드
객체 추가
- V put(K key, V value) : 주어진 키로 값을 저장한다. 새로운 키일 경우 null 리턴한고 동일한 키가 있을 경우 값을 대체하고 이전 값을 리턴한다.
객체 검색
- boolean containsKey(Object key) : 주어진 키가 있는지 확인
- boolean containsValue(Object value) : 주어진 값이 있는지 확인
- Set<Map.Entry<K, V>> entrySet() : 키와 값의 쌍으로 구성된 모든 Map.Entry 객체를 Set에 담아서 리턴
- V get(Object key) : 주어진 키의 값을 리턴
- boolean isEmpty() : 컬렉션이 비어있는지 확인
Set<K> keySet(): 모든 키를 Set 객체에 담아서 리턴- int size() : 저장된 키의 총 수를 리턴
Collection<V> values(): 저장된 모든 값을 Coolection에 담아서 리턴
객체 삭제
- void clear() : 모든 Map.Entry(키와 값)을 삭제
- V remove(Object key) : 주어진 키와 일치하는 Map.Entry를 삭제하고 값을 리턴
(1) HashMap
Map<String, Integer> map = new HashMap<String, Integer>();
Map<String, Integer> map = new HashMap<>();- hashCode(), equals()가 같다면 동등한 객체로 간주한다.
- 주로 키타입은 String을 많이 사용하는데, String은 문자열이 같을 경우 동등 객체가 될 수 있도록 hashCode()와 equals() 메소드가 재정의되어 있다.
(2) Hashtable
Map<String, Integer> map = new Hashtable<String, Integer>();
Map<String, Integer> map = new Hashtable<>();- HashMap과 동일한 내부 구조를 가지고 있다.
- hashCode(), equals()가 같다면 동등한 객체로 간주한다.
- 차이점은 Hashtable은 동기화된 메소드로 구성되어 있기 때문에 멀티 스레드가 동시에 Hashtable이 메소드들을 실행할 수 없고, 하나의 스레드가 실행을 완료해야만 다른 스레드를 실행할 수 있다.
- 멀티 스레드 환경에서 안전하게 객체를 추가, 삭제할 수 있기 때문에 Hashtable은 스레드에 안전하다.
2. LIFO와 FIFO 컬렉션
- LIFO : Last In First Out, 나중에 넣은 객체가 먼저 빠저나가는 자료구조이다. 스택이 해당된다.
- FIFO : First In First Out, 먼저 넣은 객체가 먼저 빠저나가는 자료구조이다. 큐가 해당된다.
1) Stack
Stack<E> stack = new Stack<E>();
Stack<E> stack = new Stack<>();주요 메소드
- E push(E item) : 주어진 객체를 스택에 넣는다.
- E peek() : 스택의 맨 위의 객체를 가져온다. 객체를 스택에서 제거하지 않는다.
- E pop() : 스택의 맨 위 객체를 가져온다. 객체를 스택에서 제거한다.
2) Queue
Queue<E> queue = new LinkedList<E>();
Queue<E> queue = new LinkedList<>();- Queue 인터페이스를 구현한 대표적인 클래스는 LinkedList이다.
주요 메소드
- boolean off(E e) : 주어진 객체를 넣는다.
- E peek() : 객체 하나를 가져온다. 객체를 큐에서 제거하지 않는다.
- E poll() : 객체 하나를 가져온다. 객체를 큐에서 제거한다.

do for me