LLM의 inference 과정을 설명
허깅페이스 모델의 generate 함수를 직접 구현하여 구체적 설명
생성 전략의 간략한 소개
Transformer 모델은 주로 Encoder와 Decoder 두 계열로 구분됩니다. Encoder 계열 모델, 예를 들어 BERT 같은 모델의 추론 과정은 직관적이고 이해하기 쉽습니다. 주어진 입력 시퀀스는 여러 레이어들을 거치며, 각 토큰 간의 Attention 연산이 수행됩니다. 이 과정을 마치면 마지막 레이어의 형태에 맞는 출력이 도출됩니다.
반면, 생성형 LLM인 Decoder 계열의 생성 과정은 처음 접할 때 직관적으로 이해하기가 어렵습니다. 대다수의 사용자들이 Hugging Face의 Transformers 라이브러리에서 제공하는 model.generate() 메서드를 이용해 추론하는데, 이 메서드 내부에서 정확히 어떠한 과정으로 텍스트가 생성되는지에 대한 깊은 이해 없이 사용하는 경우가 많습니다. 저 역시 처음에는 LLM 모델을 사용할 때 단순히 generate 메소드를 사용하여 결과를 얻었습니다.
이후 Transformer의 구조와 작동 원리를 깊게 공부함으로써, 내부 추론 과정에 대한 명확한 이해를 할 수 있었습니다. 아래에서는 GPT등의 decoder모델의 inference 과정을 설명하겠습니다.
기본적인 Transformer의 tokenize, embedding, attention 등의 구조는 알고 있다는 가정하에 설명하겠습니다.
LLM Inference 과정
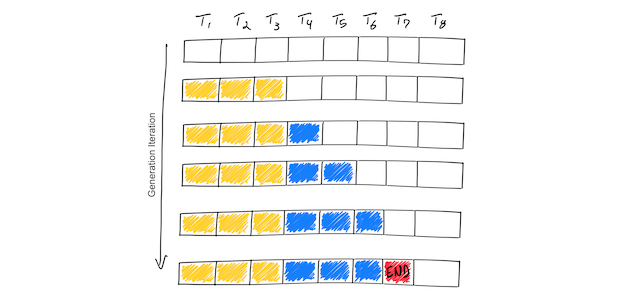
- Tokenization
입력 텍스트를 모델이 이해할 수 있는 토큰(단어 또는 부분 단어)으로 분리합니다.
예시 : "안녕하세요" → ["안녕", "하", "세요"]
- Prefix 연산
입력 토큰들(Prefix)에 대한 초기 임베딩 및 어테션 연산을 수행하여 문맥을 이해합니다.
예시 : 이미지에서 노란 부분
- key, value caching
효율적인 연산을 위해 이전 스텝에서 연산된 key와 value 값을 GPU memory에 cache합니다. 이를 통해 auto-regressive 연산 시 중복 계산을 줄일 수 있습니다.
-
토큰 하나에 대해 logit 연산
현재 문맥을 바탕(저장되어진 k, v)으로 다음 토큰이 무엇일지 예측하기 위해 확률값을 계산합니다.
예시 : [1, seq_len, vocab_size] 이와 같은 확률값들이 나오면 마지막 seq 위치의 확률값를 이용합니다. -
Decoding 전략 적용 후 토큰 생성
계산된 logit 값들 중에서 하나의 토큰을 선택하는 방법을 결정합니다. 이때, 여러 전략(greedy, num_beams, top_p 등)이 사용될 수 있습니다.
예시 : 이미지의 파란색 하나가 하나의 토큰
- 종료 조건 체크
미리 지정한 최대 생성길이에 도달하거나 eos(end of sentence)토큰이 생성되면 생성이 종료됩니다.
- auto-regressive 과정
종료 조건에 해당하지 않을 경우, 새로 생성된 토큰의 key, value값을 caching한 후, 4번으로 돌아가 생성과정을 반복합니다.+
generate 함수 직접 구현
위의 과정의 이해를 위하여 간단한 top k를 적용한 LLM 생성 함수를 만들어 보았습니다.
# 모델 불러오기
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_path = "beomi/kykim-gpt3-kor-small_based_on_gpt2"
model = AutoModelForCausalLM.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
model.eval()
print('load complete')# 생성 전략 함수, 생성 과정 함수
import random
def decoding_logits(logits, top_k):
logits = logits[:, -1, :]
# 상위 k개
top_k_logits, top_k_indices = torch.topk(logits, top_k, dim=-1)
probabilities = torch.nn.functional.softmax(top_k_logits, dim=-1)
# 확률 분포에 따라 토큰 선택
chosen_index = torch.multinomial(probabilities, 1).item()
return top_k_indices[0, chosen_index].item()
def stream_gpt(input_ids, past_key_values, max_new_tokens):
for _ in range(max_new_tokens):
model_output = model(input_ids=input_ids, past_key_values=past_key_values)
logits = model_output['logits']
past_key_values = model_output['past_key_values'] # 해당 input에 대한 k, v값
new_token_id = decoding_logits(logits, 10)
input_ids = torch.tensor([[new_token_id]]) # p_k_v를 주므로 새로 생성된 token만 input으로 넣어주면 됨
new_word = tokenizer.batch_decode([new_token_id], skip_special_tokens=True, clean_up_tokenization_spaces=True)[0]
print(new_word, end='')# 실제 사용 예시
import torch
prompt = "안녕하세요? 제가"
input_ids = tokenizer(prompt, return_tensors='pt').input_ids
past_key_values = None
with torch.no_grad():
stream_gpt(input_ids, past_key_values, 128)예시를 위해 한국어로 학습된 허깅페이스의 gpt모델을 사용하였습니다. decoding_logits는 logit 중에 어떻게 다음 단어를 고를지 정하는 전략입니다. stream_gpt는 input에 대하여 생성되는 단어들을 하나씩 출력하는 함수입니다.
위의 예시를 설명드리면 stream_gpt에서 max_new_tokens를 for문에 적용하여 최대 생성 길이를 제한해주었습니다. 이후 모델에 input_ids, past_key_values를 입력받아 model_output을 생성합니다. 여기에서 해당 input에 대한 logit과 key_value값을 얻습니다. decoding_logits 함수를 통하여 logit에서 원하는 토큰의 index를 찾습니다. index를 새로운 input_ids로 만들어주고 tokenizer를 통하여 단어를 구하여 출력합니다. decoding 전략으로는 top_k=10을 주었습니다.
주요 생성 전략
-
Temperature: 각 토큰의 확률 분포를 조절하는데 사용됩니다.
- Temperature > 1: 확률 분포가 완만해져 다양한 토큰이 선택될 확률이 높아집니다.
- Temperature < 1: 확률 분포가 뾰족해져 (sharper) 가장 확률이 높은 토큰이 주로 선택됩니다.
- Temperature = 1: 원본 확률 분포를 그대로 사용합니다.
-
Greedy Decoding: 각 스텝에서 가장 확률이 높은 토큰만 선택합니다.
-
Beam Search: n개의 경로의 후보를 유지하며 생성을 진행합니다. 각 step에서 확률의 곱이 가장 큰 n개의 경로만 남깁니다.
-
Multinomial (Top-k or Top-p) Sampling:
- Top-k Sampling: 확률이 가장 높은 상위 k개의 토큰 중 하나를 선택합니다.
- Top-p (nucleus) Sampling: 확률이 가장 높은 토큰부터 차례대로 추가하여 누적 확률이 p를 초과할 때까지의 토큰 중 하나를 선택합니다.
-
No Bad Words: 지정된 단어나 표현이 생성되지 않도록 설정합니다.
-
Repetition Penalty: 같은 토큰이 반복적으로 생성될 때 페널티를 부과하여 그 토큰이 나올 확률을 감소시킵니다.
-
Length Penalty: 문장의 길이에 대한 페널티를 부과하여 너무 짧거나 긴 문장의 생성을 조절할 수 있습니다.
-
Minimum/Maximum Length: 생성되는 문장의 최소 및 최대 길이를 지정합니다.
-
Prefix Forcing: 문장의 시작 부분이나 중간에 특정 토큰이나 표현이 포함되도록 강제합니다.
-
Attention Masking: Attention 메커니즘의 일부분을 비활성화하여 특정 부분에만 집중하도록 합니다.

BERT는 PLM으로 구분해서 부르는게 나을까요? 애매하네요... Large의 기준은 무엇일지...