해당 글은 vLLM 논문과 소개 페이지를 읽고 요약 정리한 글입니다.
중요 내용
Paged Attention을 이용하여 LLM serving에서 sota system(FT, Orca)들과 비교하였을 때, 같은 수준의 latency를 유지하면서 througput을 2-4X 향상 시킨 vLLM을 소개한다.
LLM inference의 특징
LLM모델이 매우 커짐에 따라 serving비용이 매우 증가하고 있다. throughput을 증가시켜 cost/request를 줄일 수 있다. 그렇지만 LLM의 serving에 있어서 가장 중요하게 여겨야 할 것은 한번에 하나의 token밖에 생성하지 못하므로 iterative한 것이다.
LLM이 커짐에 따라 parameter도 많아져 비싸진 token 생성 과정을 생성이 끝날때 까지 반복해서 하나의 token밖에 생성하지 못한다. 따라서 이러한 생성 과정은 GPU의 연산 능력을 제대로 활용하지 못하고 throughput을 저하시키는 memory-bound과정이다.
많은 request를 하나의 batch로 묶어서 throughput을 향상시킬 수 있으며, 이를 위해서는 GPU memory를 효율적으로 관리해야 한다.

위의 그림은 13B의 파라미터를 가진 모델의 inference를 위해 A100(40GB)을 사용할 때, 할당되는 GPU memory의 비율을 나타낸 것이다. Parameter는 inferece하는 동안 static하게 남아있는 부분이므로 어떻게 하지 못한다.(fp16 등을 사용하더라도 크기는 줄지만 크기 자체는 고정)그러므로 KV Cache부분은 request에 따라 dynamic하게 활용되므로 이 부분을 잘 활용하여야 한다.
기존 KV cache 방법과 문제점
하지만 기존에 사용되던 LLM serving system들은 이 부분이 효율적이지 못하다. 왜냐하면 기존의 방식들은 request에 대한 KV cache를 물리적으로 연속된 하나의 memory 공간에 저장하기 때문이다. 게다가 memory의 공간을 대부분 생성가능한 최대 길이로 할당한다. KV cache는 모델이 생성하는 새로운 토큰에 따라 매우 길어질 수도 있고 매우 짧아질 수도 있기에 예측불가능하여 미리 최대 길이로 할당하는 것이다.
문제점 1 : internal, external memory fragmentation

예측 불가능하기 때문에 사전에 물리적으로 인접한 최대 길이(e.g., 2048 tokens)의 공간을 할당한다. 여기서 발생하는 fragmentation은 1) reserved, 2) internal fragmentation, 3) external fragmentaion으로 나뉜다.
-
internal fragmentation
최대 길이에 도달하기 전에 생성이 완료되어, k,v cache가 이루어지지 않은 공간
(2048이 할당되었지만 10만 사용되면
2038은 사용되지 않음) -
external fragmentaion
각 request 마다 사전에 할당된 공간의 크기가 다르기 때문에 생기는 할당 공간 끼리의 비어있는 공간
-
reserved
실제로 생성에 사용되는 공간
실제로 사용되는 공간이지만 왜 비효율적이라고 하냐?
만약 생성될 길이가 1000이라고 한다면 첫번째 iteration에서는 1개의 공간만 필요하고 999개는 사용되지 않고 있으므로 비효율적임
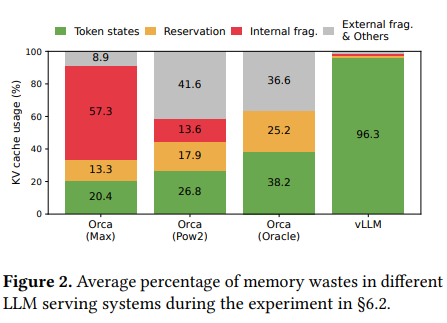
그림 2는 현재 사용되는 시스템에서 GPU memory가 어떻게 사용되고 있는 지를 보여주는데 20.4% - 38.2%밖에 사용하고 있지 않는 것을 알 수 있다.
문제점 2 : memory를 공유할 수 있는 기회를 활용할 수 없다.
decoding 방법 중에는 하나의 request에 대하여 다수의 ouput을 생성하는 방법들(parallel sampling, beam search)이 있고, 실제로 이러한 방법을 많이 이용한다. 이러한 생성 방식 중에는 KV cache를 어느 정도 공유할 수 있는 경우가 많을 텐데(prompt, 일부 생성 token 등), 현재 시스템에서는 KV cache가 분리된 연속된 공간에 존재하기 때문에, KV cache의 공유가 불가능하다.
Paged Attention
위와 같은 기존 방식의 두 가지 한계를 해결하기 위해 고안한 attention 방식이다. 기존의 operating system에서 memory fragmentation and sharing: virtual memory with paging 방식에서 영감을 받아서 만든 방식이다.
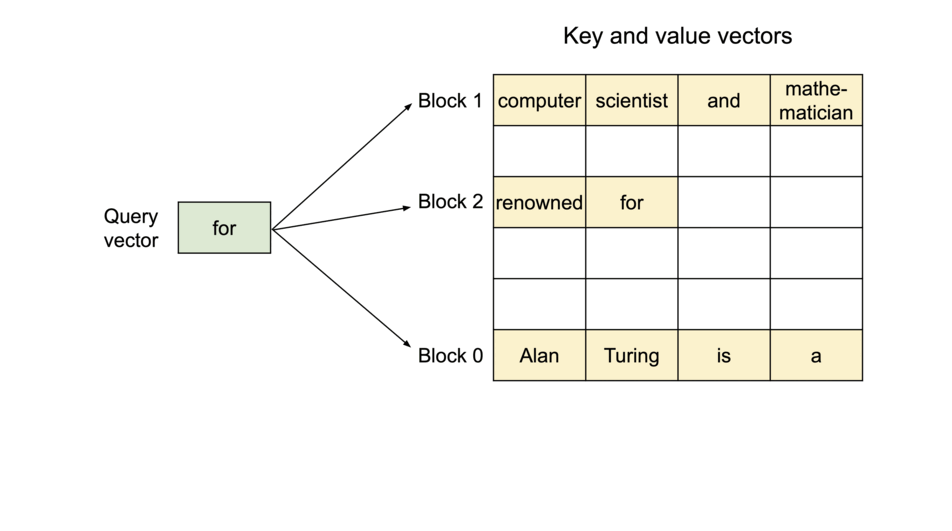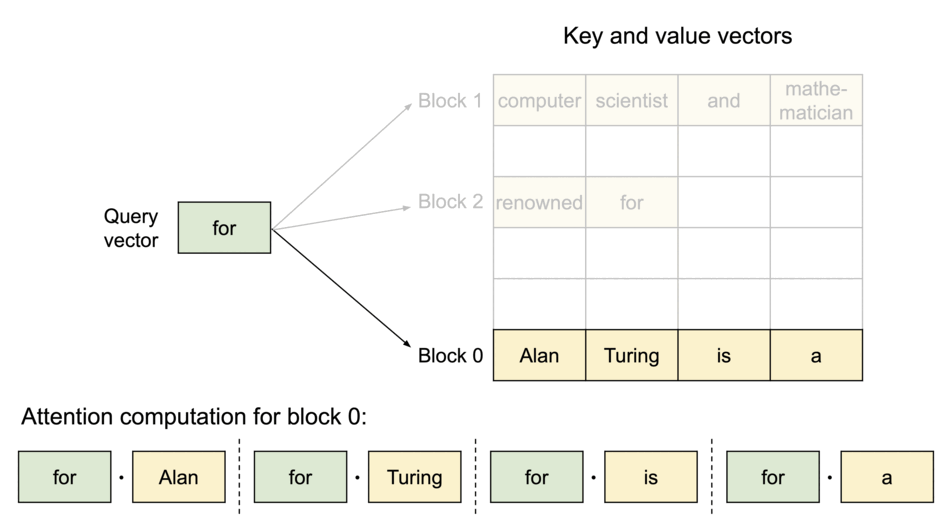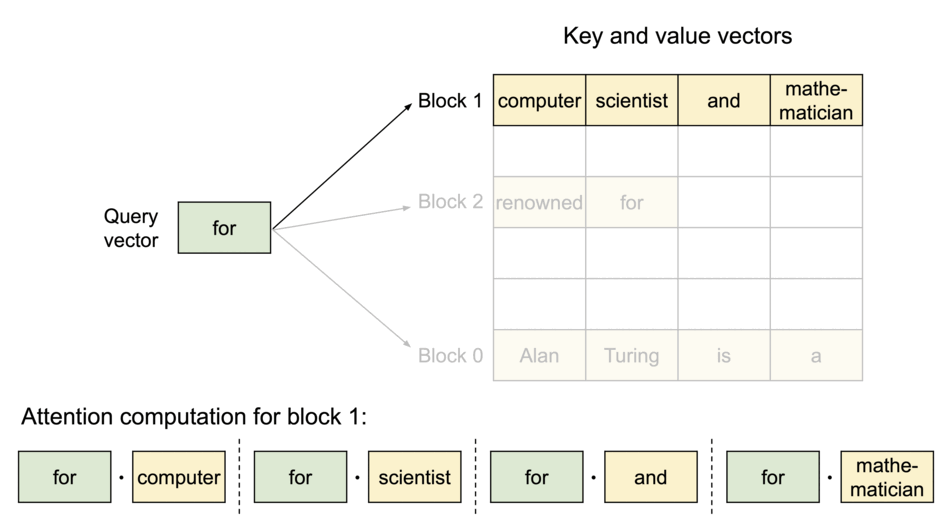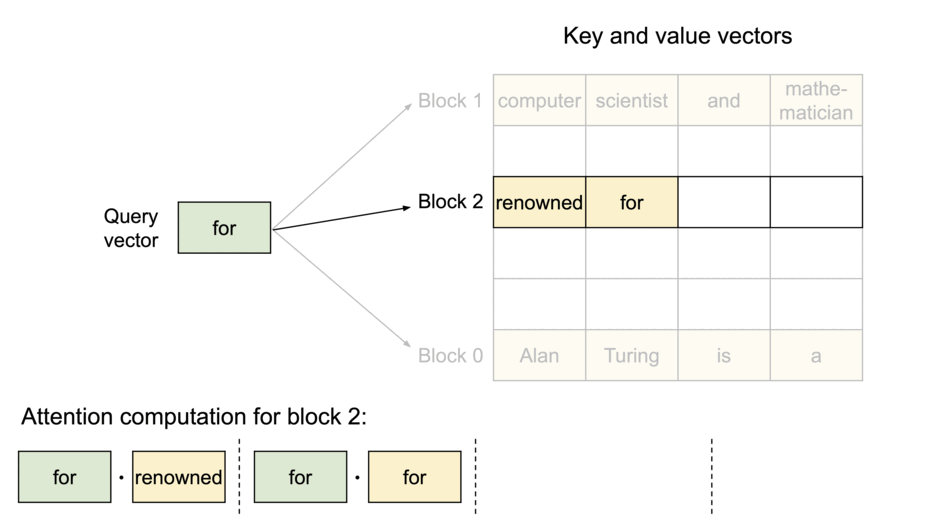
- KV cache를 여러
Phycial KV block으로 분산 - 각
Phycial KV block은 일정 개수의 토큰의 key, value 저장 (일정 개수는 조절 가능 - 추후 설명) Phycial KV block은 물리적으로 인접할 필요가 없음Phycial KV block들이 어디에 위치하는지 블록의 순서(주소)와 블록에 몇 개의 값이 저장되어 있는지 기록한Block Table존재
위와 같은 방식을 활용하여 필요할 때만 dynamic하게 memory를 할당하여 쓰므로 interenal fragmentaion, reserved의 낭비를 줄일 수 있고, 모든 블록이 같은 크기를 가져서 external fragmentaion도 줄일 수 있다. 또 block단위로 저장되기 때문에 메모리를 공유하는 것도 가능하다.
그래서 vLLM은
- PagedAttention 기반의 high-throughput distributed LLM 서빙 엔진
- PagedAttention을 통해 KV cache 메모리의 낭비가 0에 가까움
- PagedAttentions과 같이 디자인된, block-level memory management와 preemptive request scheduling을 사용
- GPT, OPT, LLaMA와 같은 널리 사용되는 LLM을 지원
- 하나의 GPU에 담을 수 없는 크기도 지원
- 정확도의 손해 없이 sota system 보다 2-4X의 serving throughput 달성
- 특히 모델이 클수록, seq length가 길수록, decoding방법이 복잡할 수록 좋은 성능 향상

정말 좋은 글인데 왜 하트가 1개인지 모르겠네요..(제가 누름).. 좋은 글 감사합니다!!!