Poly-encoders 논문 리뷰
프로젝트를 진행하며 사용하였던 Poly-encoders: architectures and pre-training strategies for fast and accurate multi-sentence scoring 논문 리뷰
Introduction
- 목적
- context가 들어 갔을 때에 다양한 candidate labels과 multi-sentence scoring을 하는 pair-wise comparison task에 관한 개선
- 관련 성능 척도
- 예측 퀄리티
- 예측 속도 : candidate가 많으면 속도가 느려지기 때문에 고려
- 사전 모델들
- Cross-Encoder
- 높은 정확도 : 주어진 input에 대해서 모든 candidate labels와 full(cross) self-attention
- 느린 속도 : 각각의 input-candidate label쌍에 대해 모두 계산해야 하기때문
- Bi-Encoder
- 낮은 정확도 : self-attention을 input과 candidate labels에 대하여 각각 수행하고 마지막에 최종 결과물들을 합치는 방식을 사용하기 때문에 Cross-encoder에 비해 상대적으로 낮은 정확도
- 빠른 속도 : encoded 된 candidates를 미리 저장해두고 재사용할 수 있기때문에
- Cross-Encoder
- Poly-Encoder
- Bi-Encoder보다 정확도 성능이 좋으며 Cross-Encoder보다 훨씬 빠른 모델 제안
Tasks
Sentence selection in dialogue
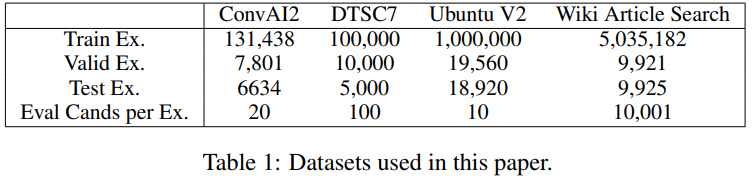
- ConvAI2 dataset
- 양 발화자 간의 대화를 포함한 Persona-Chat dataset에 기반
- 각 발화자는 따라해야하는 캐릭터를 나타내는 몇 문장의 persona를 가지고 있고 나머지를 알아내야 함
- 성능평가에서 모델은 정답과 다른 정답들중에 랜덤으로 골라진 19개의 선택지로 이루어진 총 20개의 선택지들 중 가장 알맞는 답을 골라야함
- 최고의 성능을 낸 pre-trained transformer를 사용한 경쟁자는 80.7%의 accuracy를 가지고 있음
- DSTC7 challenge (Track 1) dataset
- Ubuntu chat logs에서 추출한 대화들로 이루어짐
- 이전 최고 성능을 낸 경쟁자는 64.5% R@1의 성능
- Ubuntu V2 corpus
- DSTC7과 유사하지만 훨씬 큰 corpus
Article search in IR(Information Retrieval)
- Wikipedia Article Search dataset
- article에서 추출된 하나의 문장이 주어졌을 때, 해당 문장이 어느 article에서 나온 것인지 찾는 task
- retrieval metrics를 사용해 10,000개의ㅡ 다른 article에 대하여 실제 article의 순위를 통해 검증
Methods
Transformers
- 논문의 Bi-Encoder, Cross-Encoder, Poly-Encoder 모두 12 layers, 12 attention head, hidden size 768을 가진 pre-trained BERT-base모델 사용
- BERT-base와 같은 구조인 transformer를 from scratch로 두 개 더 학습
- Wikipedia and the Toronto Books Corpus를 사용하여 150 million [INPUT, LABEL]를 학습
- BERT와 유사하게 세팅하여 학습 했을 때 비슷한 성능을 보이는지 확인하기 위하여 학습
- online platform Reddit data를 사용하여 174 million [INPUT, LABEL]를 학습
- dialogue에 더 적합한 데이터셋
- 우리의 목적과 더 비슷한 데이터로 pre-training시키면 성능이 더 좋은지 확인하기 위하여 학습
- Wikipedia and the Toronto Books Corpus를 사용하여 150 million [INPUT, LABEL]를 학습
Pre-training strategies
Train Input 형식
[S][IN-PUT,LABEL][S]형식
- Reddit dataset
- input : context
- label : next utterence
- Wikipedia and Toronto Books
- input : on sentence
- label : next sentence
input = token embedding + position(sequence) embedding + segment embedding
Pretraining Procedure
- Wikipedia and Toronto Books
- BERT를 학습 시킨 방법과 동일한 방법인 next sentence prediction으로 학습
- Rediit
- utterence가 여러개의 sentence로 이루어질 수 있다는 점에서 앞선 학습 방법과 살짝 다른 next-utterence prediction task사용
학습 시 50%는 실제 sentence/utterence를 사용하였고 나머지 50%는 dataset내에서 random하게 선택된 sentence/utterence를 사용하였다.
- Adam
- lr : 2e-4 , beta1 : 0.9, beta2 : 0.98, no L2 weight decay, linear learning rate warmup, inverse square root decay of learning rate
- Drop out
- 모든 층에서 0.1
- Batch
- 유사한 길이의 [INPUT, LABEL]로 이루어진 32000 tokens batch
- 학습 환경
- 32GPUs for 14days
Fine-tuning
pre-trained transformer모델을 사용하여 Bi-Encoder, Cross-Encoder, Poly-Encoder에 대하여 fine-tuning 수행
Models
Bi-Encoder
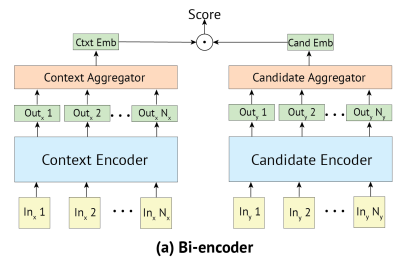

- input context 와 candidate가 각각 encoding된 결과물들을 최종적으로 score계산
- 동일한 구조를 가진 encoder를 context와 candidate에 대하여 각각 따로 구성하여 학습
- T(x)=h1, …, hn는 transformer의 결과물이며 red는 이 sequence of vector를 하나의 vector로 줄이는 함수
- 다양한 방법중 red로 sequence의 첫번째를 택하는 것을 사용
- 가장 좋은 결과를 가져왔기 때문
- context 와 candidate의 score는 s(ctxt, candi)=yctxt.ycandi로 나타냄
- score의 cross-entropy loss를 최소화 하도록 구성
- ycandi들 중 ycand1 하나만 실제 정답이고 나머지는 batch내에서 random하게 주어진 값
- batch에서 계산된 값들을 다시 사용하여 빠른 학습시간 보장
- 큰 batch size 사용 가능
- candidate embedding을 미리 구한 뒤 저장한 값을 사용할 수 있기 때문에 inference time이 빠름
Cross-Encoder
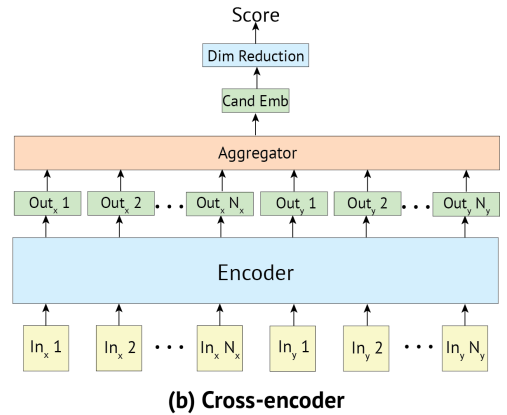
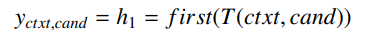
- input context 와 candidate 를 concat하여 하나의 input으로 만들어 transformer에 입력
- 하나의 transformer사용하며 Bi-Encoder와 마찬가지로 transformer output의 첫번째 h1을 사용
- context와 candidate간에 풍부한 interaction으로 인해 풍부한 extractioon mechanism을 가짐
- 이로 인해 candidate-sensitive input representation이 생성
- vector를 scalar인 점수로 바꾸기 위하여 s(ctxt, candi) = yctxt,candi W가 사용됨
- W는 linear layer
- Bi-Encoder와 유사하게 score의 cross-entropy loss를 최소화하도록 구성되었으며, candi들은 하나만 정답이고 나머지는 training set에서 추출된 값들임
- candidate embedding을 재사용할 수 없으므로 메모리가 부족하여 Bi-Encoder에 비하여 작은 Batch size를 사용해야함
- 모든 candidate 가 context와 concat되어 계산되어야 하므로 inference time이 느리며 이로인해 candidate를 많이 두지 못함
Poly-Encoder

-
Bi-Encoder의 장점인 candidate embedding을 미리 계산하여 사용할 수 있으며, context와 candidate간의 final attention mechanism을 추가함으로써 richer interaction을 가능하게 한 모델
-
Bi-Encoder와 마찬가지로 동일한 구조를 가진 encoder를 context와 candidate에 대하여 각각 따로 구성하여 학습
-
attention mechanism
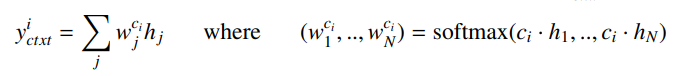
- Bi-Encoder처럼 context encoder에서 나온 첫번째 결과만 사용하는 것이 아니라 모든 vector에 대해서 self-attention을 수행하여 m(Hyper parameter → inference time에 영향 끼침)개의 embedding vecotr만들어냄
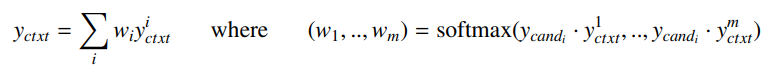
- 이후 생성된 m개의 yctxi들과 candidate emb간의 attention을 통하여 ctx emb 생성Experiments
4가지 task에 대하여 모델 구조와 학습 전략에 따라 다양한 실험 수행
평가지표
- R@k/C
- 검색 결과 중 실제 관련된 항목을 찾아내는 능력
- 테스트 예제마다 C개의 candidate가 있을 때, 상위 k개의 추천 중 관련된 항목을 몇개 찾았는지- Mean Reciprocal Rank(MRR)
- 추천 항목의 순위 고려하여 rank에 사용되는 지표
- 테스트마다 관련 항목 순위의 역수를 계산하여 평균
- Mean Reciprocal Rank(MRR)
Bi-Encoder and Cross-Encoder

- Bi-Encoder는 pre computed cand embedding을 사용할 수 있어서 batch size를 크게 조절할 수 있었는데 ConvAI2 데이터셋에 대하여 batch size를 크게해서 negatives를 늘릴수록 성능이 올라가는 것을 확인
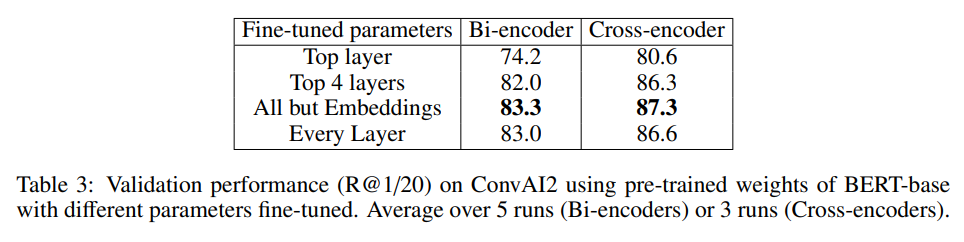
- ConvAI2데이터에 대하여 층들을 다양하게 바꿔가며 학습했을 때, embedding layer를 제외한 레이어들을 학습시키는 것이 가장 좋은 결과를 보임
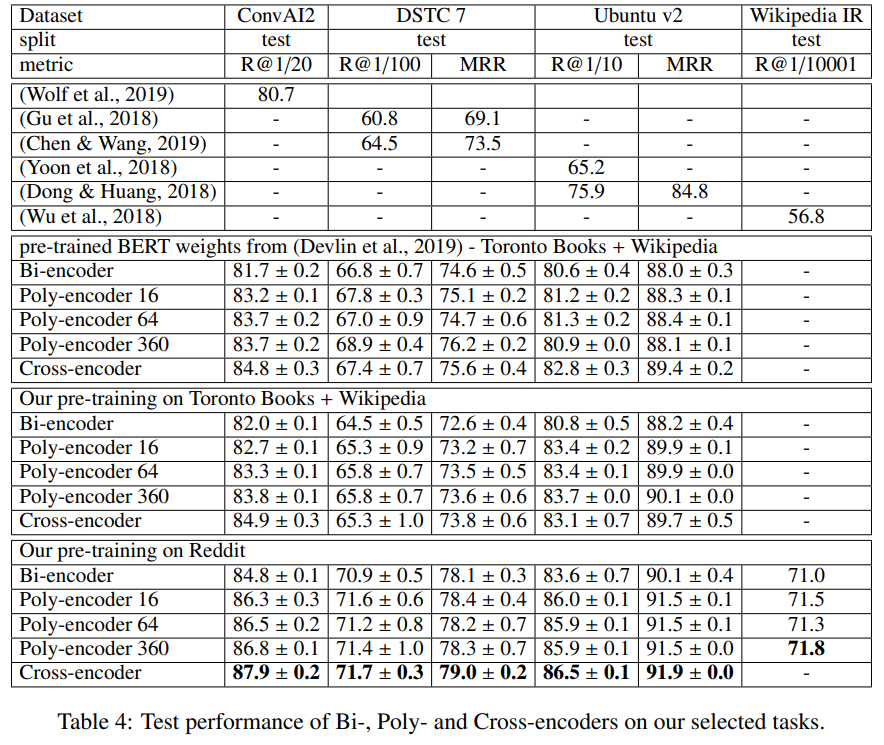
- 또한 앞선 3개의 데이터 셋에 대하여 사전 Bert모델보다 논문에서 학습시킨 모델들이 더 좋은 성능을 보임
- Wikipedia IR은 테스트 결과를 보증하지 못하며 evaluate가 느려서 포함하지 않음
Poly-Encoder
- Bi-Encoder와 같은 batch size, optimizer사용하여 실험
- 하이퍼 파라미터인 m도 조절해가며 성능을 측정해 보앗는데 Table 4에서 m이 커질수록 성능이 좋아지는 것을 확인
Domain-specific Pre-training
- 논문이 Toronto Books + Wikipedia에 대하여 학습시킨 모델은 원본 BERT와 매우 흡사한 결과
- 그러나 Reddit 데이터셋에 대하여 학습 시킨 모델은 원본 BERT보다 좋은 결과
- downstream task에 알맞는 pre-training task를 가진 모델, 데이터셋을 선택하는 것이 최종 모델 성능에 결과를 끼침을 알 수 있음
Inference Time
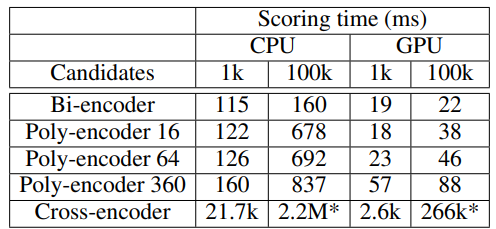
- candidate가 1k로 적을 때는 Poly-Encoder와 Bi-Encoder의 inference time의 차가 적었지만 100k로 늘어나자 간격이 늘어났음에도 두 모델은 실제 사용 가능한 시간임
- Cross-Encoder는 real-time이 불가능한 수준
- Training time도 Poly-Encoder가 Cross-Encoder에 비해 약 3-4배 빠름
Conclusion
- candidate selection task에서 유용한 새로운 구조와 pre-training 전략을 소개하는것을 목표로 하였음
- Poly-Encoder (구조)
- Bi-Encoder의 장점인 cand emb을 사전 계산하여 사용하는 것을 가져와 inferece 속도 올려서 real-time 사용 가능하게 함
- Cross-Encoder의 장점인 context와 candidate의 attention을 적용한 mechanism을 구성하여 정확도를 올림
- Training architecture (학습 전략)
- downstream task 더 가깝거나 유사한 pre-training 전략을 사용하는 것이 더 좋은 성능을 가져옴
- ex) 하고자 하는 task와 유사한 데이터셋 사용, 유사하게 학습된 pre-trained model 사용
