배운 것
자연어 데이터 전처리 종류 및 과정
PII가 무엇이며 PII Filtering 과정
Qulity Filtering 과정
Pipeline Parallelization
배치 사이즈가 작으면 overfitting 발생하지 않음??
few-shot prompting based evaluation
KOBEST benchmark dataset이란?
GPT-NeoX란?
1.프로젝트 배경 및 목적
mBERT, BLOOM, XGLM 등의 다양한 multilingual model이 있는데도 왜 새로운 multilingual model을 만들고자 하는가?
→ 비 영어권 언어에서 영어에 비해 좋지 못한 performance를 보이기 때문에
비 영어권 언어 퍼포먼스가 좋은 multilingual model만들자
2.데이터셋
2.1.데이터 수집
TUNiB에서 curated 된 한국어 데이터 863GB ( 전 처리 전 1.2TB )
Polyglot-Ko 학습을 위해 수집 되었으므로 공개 하지 않음
2.2.데이터 분석
학습 과정
- 너무 짧거나 긴 문장
- 반복되는 단어나 문자
- 중복 데이터
Inference 과정
- personally identifiable information ( PII )
각 과정에서 위와 같은 문제가 risk 를 야기할 수 있으므로 데이터 분석을 실시
위와 같은 risk를 줄이는 관점에서 데이터를 분석해 본 결과 데이터는 4가지의 유형으로 분류
- 학습 가능한 데이터
- 뉴스, 위키피디아 : 충분히 긴 text를 가진 정보들
- contextual information 을 하면 학습 가능한 데이터
- 블로그, 일부 뉴스 : 잘못 스크랩된 많은 짧은 문장으로 구성
- hate speech가 포함되어 학습 불가능한 데이터
- 일부 커뮤니티 데이터
- NLP task data
- text classification, entity recognition 과 같은 NLP task 데이터 : 학습에는 사용할 수 있으나 evalutate 할 때 제외 해야 함
데이터를 학습 시키기 전에 진행되어야 할 퀄리티 문제가 존재
학습 과정에서 문제를 야기할 수 있으므로 전처리 수행
- Empty text : 빈 문장
- Unnecessary space : 불필요한 띄워쓰기
- De-identification : 개인 정보 데이터
- Uncleaned HTML tags : HTML 태그가 지워지지 않음
- Deduplication : 정확하게 일치하는 중복 데이터 instance
- Broken code : HML or Markdown 의 일부만 존재
- Short text : 너무 짧은 문장
- Repeated character : 데이터 instance에서 중복되는 문자
→ plyglot 은 한국어 문장 생성에 목적을 두므로 html과 같은 코드들은 가능한 모두 제거
전처리 되어야 할 또 다른 중요한 문제는 데이터의 길이
→ 문장이 길 수록 많은 정보가 모델에 학습됨
데이터의 길이 분포를 보기 위하여 50datasets를 모아 샘플하여 길이 분포를 box plot 으로 시각화하여 봄
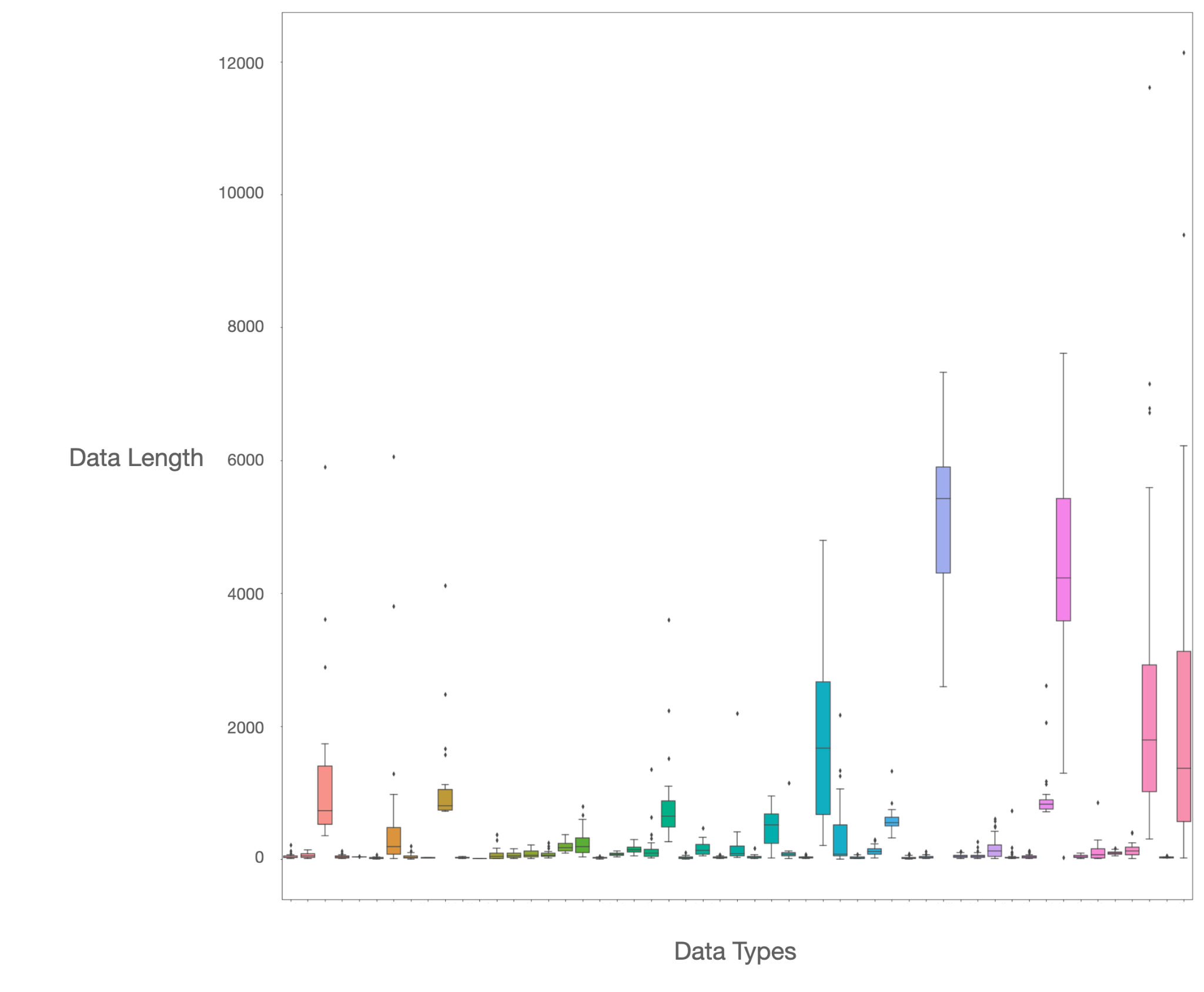
위의 데이터 길이 분포를 보면 대부분의 데이터셋이 짧은 문장들을 포함하고, 소수만이 긴 문장들을 포함
긴 문장들을 포함한 데이터는 대부분 news article, blog데이터
이러한 결과를 바탕으로 문장 길이에 따른 필터 상태를 설립 → new 나 blog 정보의 contextual information이 모델 학습 과정에서 가장 많이 학습됨
2.3.데이터 전처리
위의 데이터 분석 결과로 데이터 전처리 수행
-
PII Filtering
PII 누수로 인한 손해를 최소화하기 위하여 masking 실시
일부 데이터는 harmful 하더라도 model이 다양한 task를 수행하는데 도움을 줄 수 있으므로 매우 중요한 개인정보의 최소한(bare minimum of critical personal information)만 masking
- Phone Number(전화번호) : 유, 무선 전화번호는
<|tel|> - Resident Registration Number(주소) :
<|rrn|> - Bank Account Number(계좌번호) :
<|acc|>→ 12개 은행에 대해 실시
- Phone Number(전화번호) : 유, 무선 전화번호는
-
Quality Filtering
Gopher 에 명시된 데이터 전처리 filtering logic 사용 → 위의 언급된 문제점 해결할 수 있을 것이라고 판단
- document length filter : 특정 길이가 충족되지 않으면 filtering
- mean length word filter : 문장의 평균 단어 길이가 비정상적으로 길면 filtering
- symbol to word ratio filter : 문장에서 단어보다 특정 symbol이 너무 많으면 filtering → HTML tag 제거에 유용
- bullet and ellipsis filter : bullet(문서나 글에서 항목을 나타내는 점이나 기호), ellipsis(문장의 생략 기호 … ) filtering
- alphabetic word ratio filter : 해당 언어의 문자보다 다른 언어의 문자 비율이 많으면 filtering
3.Training procedure and Models
EleutherAI의 [GPT-NeoX]https://github.com/EleutherAI/gpt-neox) 베이스 코드 사용
256 A100s(8*32 nodes) 사용
3.1.Polyglot-Ko-1.3B
| Hyperparameter | Value |
|---|---|
| n_parameters | 1,331,810,304 |
| n_layers | 24 |
| d_{model | 2,048 |
| d_ff | 8,192 |
| n_heads | 16 |
| d_head | 128 |
| n_ctx | 2,048 |
| n_vocab | 30,003 / 30,080 |
| Positional Encoding | Rotary Position Embedding (RoPE) |
| RoPE Dimensions | 64 |
pipeline paralleism 미사용
batch size : 1024
train, validation data loss이 overfitting 발생(약 100000step)하여 학습 중단
Inference에서도 급격한 성능 저하를 보였으므로 overfitting이전의 checkpoint들 에서 평가과 검증을 통해 모델 선정
3.2.Polyglot-Ko-3.8B
| Hyperparameter | Value |
|---|---|
| n_parameters | 3,809,974,272 |
| n_layers | 32 |
| d_{model | 3,072 |
| d_ff | 12,288 |
| n_heads | 24 |
| d_head | 128 |
| n_ctx | 2,048 |
| n_vocab | 30,003 / 30,080 |
| Positional Encoding | Rotary Position Embedding (RoPE) |
| RoPE Dimensions | 64 |
Pipeline parallelization 사용
batch size : 1024
1.3B와 마찬가지로 약 100000step에서 overfitting 발생
3.3.Polyglot-Ko-5.8B
| Hyperparameter | Value |
|---|---|
| n_parameters | 5,885,059,072 |
| n_layers | 28 |
| d_{model | 4,096 |
| d_ff | 16,384 |
| n_heads | 16 |
| d_head | 256 |
| n_ctx | 2,048 |
| n_vocab | 30,003 / 30,080 |
| Positional Encoding | Rotary Position Embedding (RoPE) |
| RoPE Dimensions | 64 |
pipeline parallelization 사용
batch size : 256
배치 사이즈가 작아서 320000step까지 overfitting 발생하지 않고 학습 완료
step이 진행될 수록 모델 performance 향상
4.Performance Evaluation
KOBEST benchmark dataset 을 사용하여 few-shot prompting based evaluation 수행
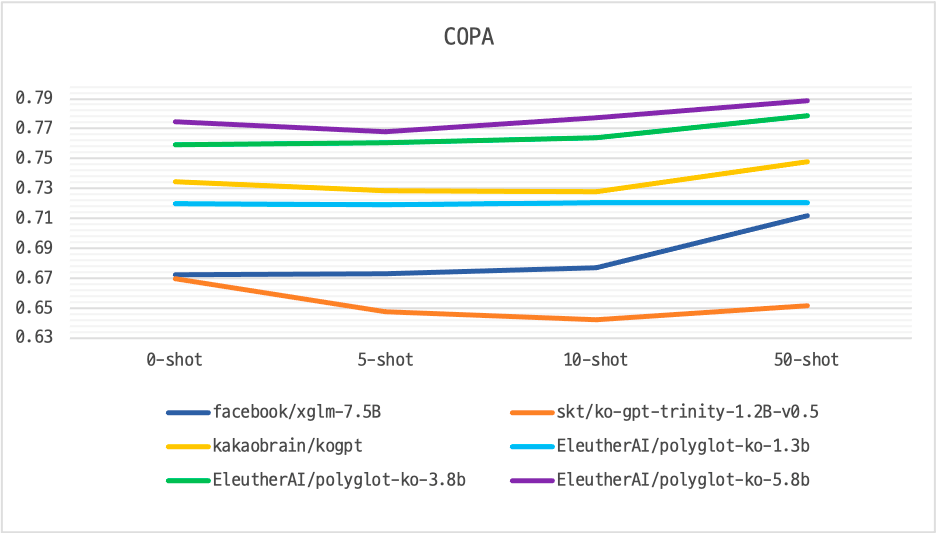
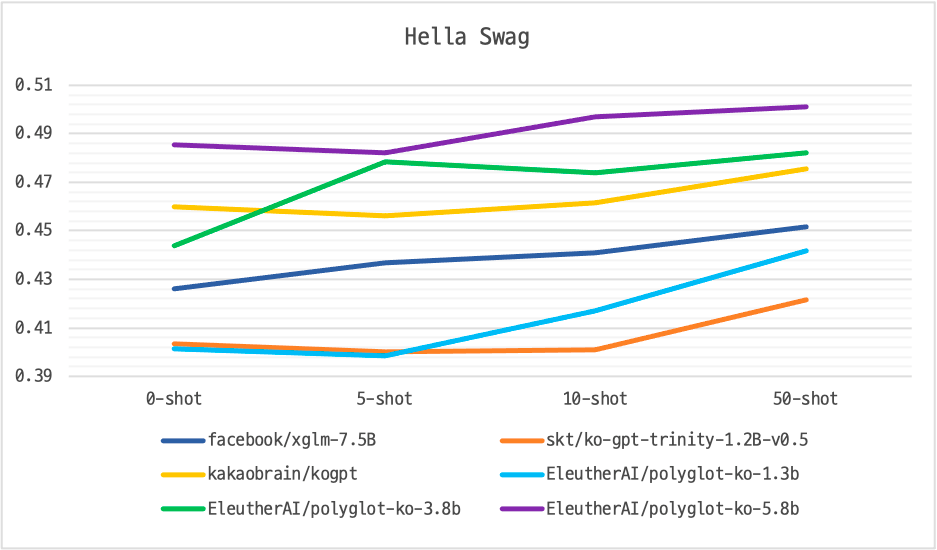
Parameter 수와 few-shot 수가 늘어남에 따라 Polyglot-Ko의 성능이 항상
다른 한국어 LLM에 비해 좋은 성능 보임
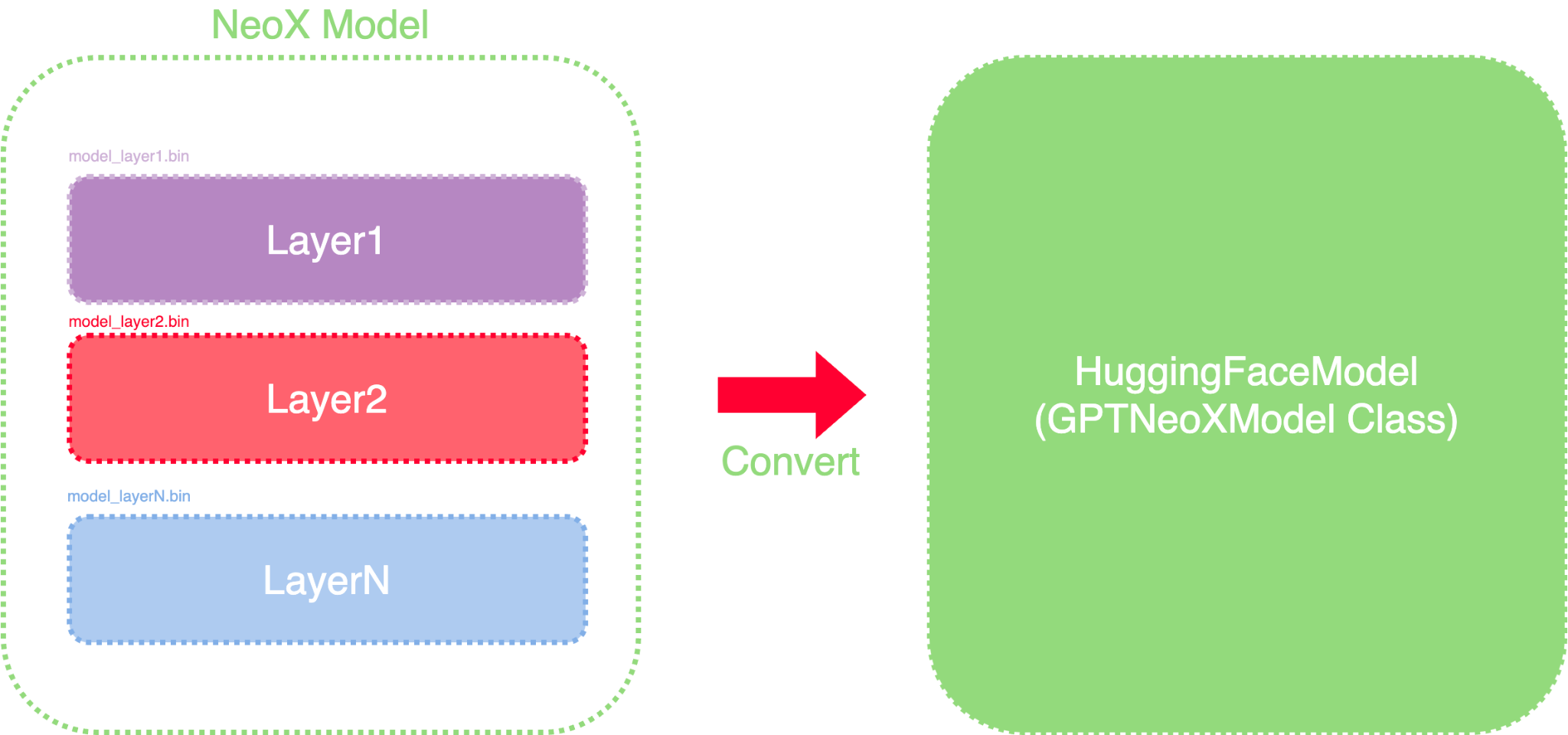
5.Checkpoints Merging and Model Upload
학습된 모델을 huggingface에 업로드 하고자 함
GPT-NeoX의 체크포인트들을 하나의 checkpoint로 합치고 Hugging Face Transformers 형식으로 바꿔야 함
이를 위한 script를 만들고 아래 과정 수행
- Creater config file : GPT-NeoX를 Hugging Face Transformers에서 바로 사용할 수 없음. 모델 관련 parameter 를 config.json에 넣음. 훈련 과정에 사용한 훈련 파라미터들은 포함하지 않음.
- Merge models by layers : 나뉘어진 checkpoints를 merge한다. 하나의 층에서 각 gpu에 따라 정렬된 tensors가 master process(gpu0)에서 merge되어 하나의 checkpoint가 된다.(e.g model_layer_1.bin)
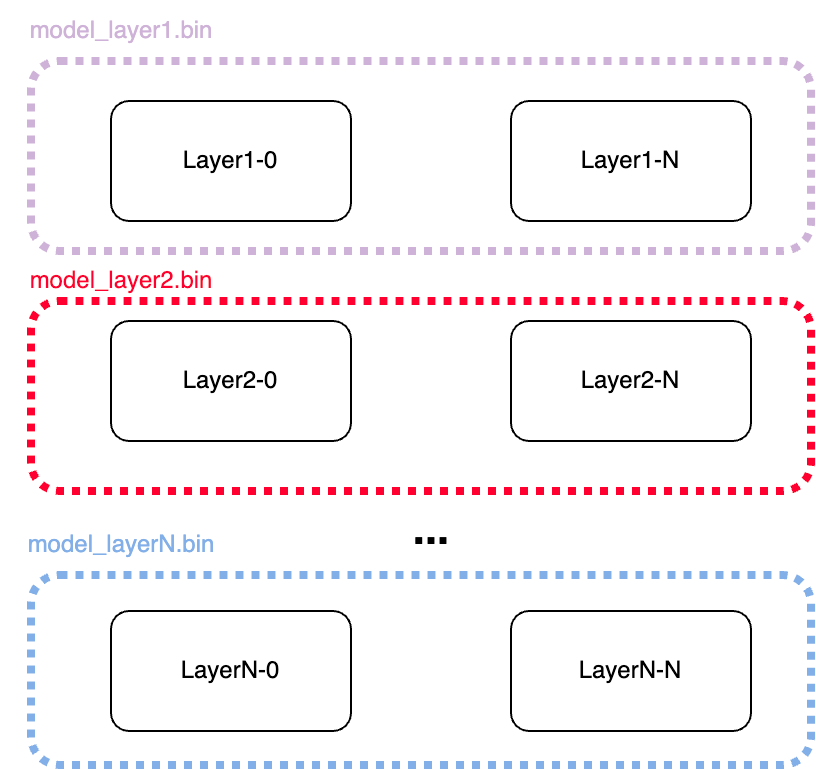
- Merging and converting model checkpoint : 각 층에서 한 개의 파일로 저장된 chekpoints를 Hugging Face Transformers 의 key를 사용하여 state dict 로 저장한다.

소중한 정보 잘 봤습니다!