Text Generation Metric(자연어 생성 평가 지표)
자연어 생성(Text Generation) 모델의 성능을 평가하는 방법은 여러가지이다. Human Evaluation은 종종 최선의 지표이지만, 상당히 비싸고 시간이 많이 소요된다. 따라서 자동 평가방법(Automatic Evaluation Metrics)을 많이 사용한다.
초창기에는 문장 간의 표면적 유사도를 측정하는 평가방법을 사용했다.
자연어 생성(Text Generation) 모델의 성능을 평가하기 위한 지표 1. ROUGE(Recall-Orient Understudy for Gisting Evaluation) - 표면적 유사도 측정
예를 들어,
Predicted sentence: the cat was found under the bed
True sentence(정답): the cat was under the bed
일 때,
Recall은 True sentence을 구성하는 단어 중 몇 개의 단어가 Predicted sentence에 있는지를 보는 점수이다.
예시에서의 Recall은 6/6 = 1이다.
Precision은 Predicted sentence을 구성하는 단어 중 몇 개의 단어가 True sentence에 있는지를 보는 점수이다.
예시에서의 Precision은 6/7 = 0.86이다.
만약 시스템 요약본 2: the tiny little cat was found under the big funny bed가 추가로 있다면, Precision은 6/11 = 0.55이다. 따라서 간결한 요약을 생성하는 것이 목표라면, Precision보다 Recall만 사용해도 무방하다.
(ROUGE 자료 참고: https://huffon.github.io/2019/12/07/rouge/)
자연어 생성(Text Generation) 모델의 성능을 평가하기 위한 지표 2. BLEU(Bilingual Evaluation Understudy) Score - 표면적 유사도 측정
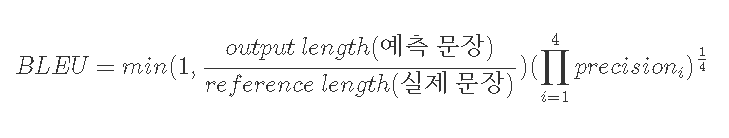
예를 들어,
Predicted sentence: 빛이 쐬는 노인은 완벽한 어두운 곳에서 잠든 사람과 비교할 때 강박증이 심해질 기회가 훨씬 높았다.
True sentence: 빛이 쐬는 사람은 완벽한 어둠에서 잠든 사람과 비교할 때 우울증이 심해질 가능성이 훨씬 높았다.
일때,
Precision은 n-gram을 통해 순서쌍들이 얼마나 겹치는지를 측정한다.

예를 들어,
Predicted sentence: 빛이 쐬는 노인은 완벽한 어두운 곳에서 잠듬
True sentence: 빛이 쐬는 사람은 완벽한 어둠에서 잠든 사람과 비교할 때 우울증이 심해질 가능성이 훨씬 높았다.
Brevity Penalty는 문장길이에 대한 과적합을 보정한다.

최종적인 BLEU score은

(BLEU 자료 참고: https://donghwa-kim.github.io/BLEU.html)
그러나 비슷한 의미의 단어들로 구성되어 문장 간의 유사도가 높더라도, ROUGE나 BLEU 성능은 낮을 수 밖에 없다. 따라서 (주로 신경망에 기반한) "학습"을 통한 평가지표가 발달하였다.
자연어 생성(Text Generation) 모델의 성능을 평가하기 위한 지표 3. 완전히 학습된 평가지표(BEER, RUSE, ESIM) - 의미적 유사도 측정
- 일반적으로 end-to-end 방식으로 학습된다.
- 유창성, 충실함, 문법, 스타일 등 task-specific한 속성들을 가지도록 튜닝할 수 있다.
자연어 생성(Text Generation) 모델의 성능을 평가하기 위한 지표 4. Hybrid 평가지표(YiSi, BERTscore) - 의미적 유사도 측정
- 학습된 요소(contextual embedding)을 수동으로 만든 논리와 결합한다.
- 강건성을 확보할 수 있다.
- 학습 데이터가 적거나 없는 상황에서 좋은 결과를 얻을 수 있다.
자연어 생성(Text Generation) 모델의 성능을 평가하기 위한 지표 5. BLEURT - BERT에 기반한 평가지표
BLEURT는 아래의 3단계를 거친다.
- BERT 모델의 기본 사전학습
- 합성 데이터에 대한 사전학습
- task-specific rating에 대한 미세조정
합성 데이터에 대한 사전학습을 하기 위해 3가지 방법을 사용해 sentence pairs 데이터셋을 만든다.
- Mask-filing with BERT
- Backtranslation
e.g. 영어(정답) -> 프랑스어 -> 영어(후보) - Dropping words
e.g. 임의의 빈칸 생성
BERT의 CLS 토큰에 선형 레이어를 추가하여 L2 loss를 쓰는 회귀를 진행하거나,
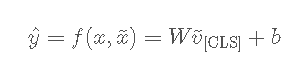
multi-class cross-entroy loss를 쓰는 분류를 진행한다.

(논문 URL: https://arxiv.org/abs/2004.04696)
(BLEURT 자료 참고:
https://greeksharifa.github.io/machine_learning/2021/01/13/BLEURT-Learning-Robust-Metrics-for-Text-Generation/)
