1. 문자열 검색
String Searching
어떤 문자열 안에 다른 문자열이 포함되어 있는지 검사하고,
만약 포함되어 있다면 어디에 위치하는지 찾아내는 것
STRING⇒IN⇒true
QUEEN⇒IN⇒false
용어
- 텍스트 ( text ) : 검색되는 쪽의 문자열
- 패턴 ( pattern ) : 찾아내는 문자열
※ A를 텍스트, B를 패턴이라고 가정하면, A에서 B를 찾아내는 알고리즘
2. 브루트 포스법
Brute Force Method
- 문자열 검색 알고리즘 중에서 가장 기초적이고 단순
- 선형 검색을 단순하게 확장한 알고리즘 ⇒ 단순법
※ 클릭 시 출처로 이동

const bruteForce = (text: string, pattern: string): number => {
const totalCount = text.length - pattern.length + 1;
let matchLength = 0;
for (let i = 0; i < totalCount; i++) {
for (let j = 0; j < pattern.length; j++) {
if (text[i + j] === pattern[j]) matchLength++;
}
if (matchLength === pattern.length) return i;
matchLength = 0;
}
return -1;
};
console.log("result :", bruteForce("tomcat", "cat")); // result : 3
console.log("result :", bruteForce("tomato", "cat")); // result : -1이미 검사한 위치를 기억하지 못하므로 브루트 포스법은 효율이 좋지 않다.
3. KMP 법
KMP
- 검사했던 결과를 버리지 않고 효율적으로 활용하는 알고리즘
- 텍스트와 패턴 안에서 겹치는 문자열을 찾아내 검사를 다시 시작할 위치를 구함
- 몇 번째 문자부터 다시 검색할지 값을 표로 만들어서 문제 해결
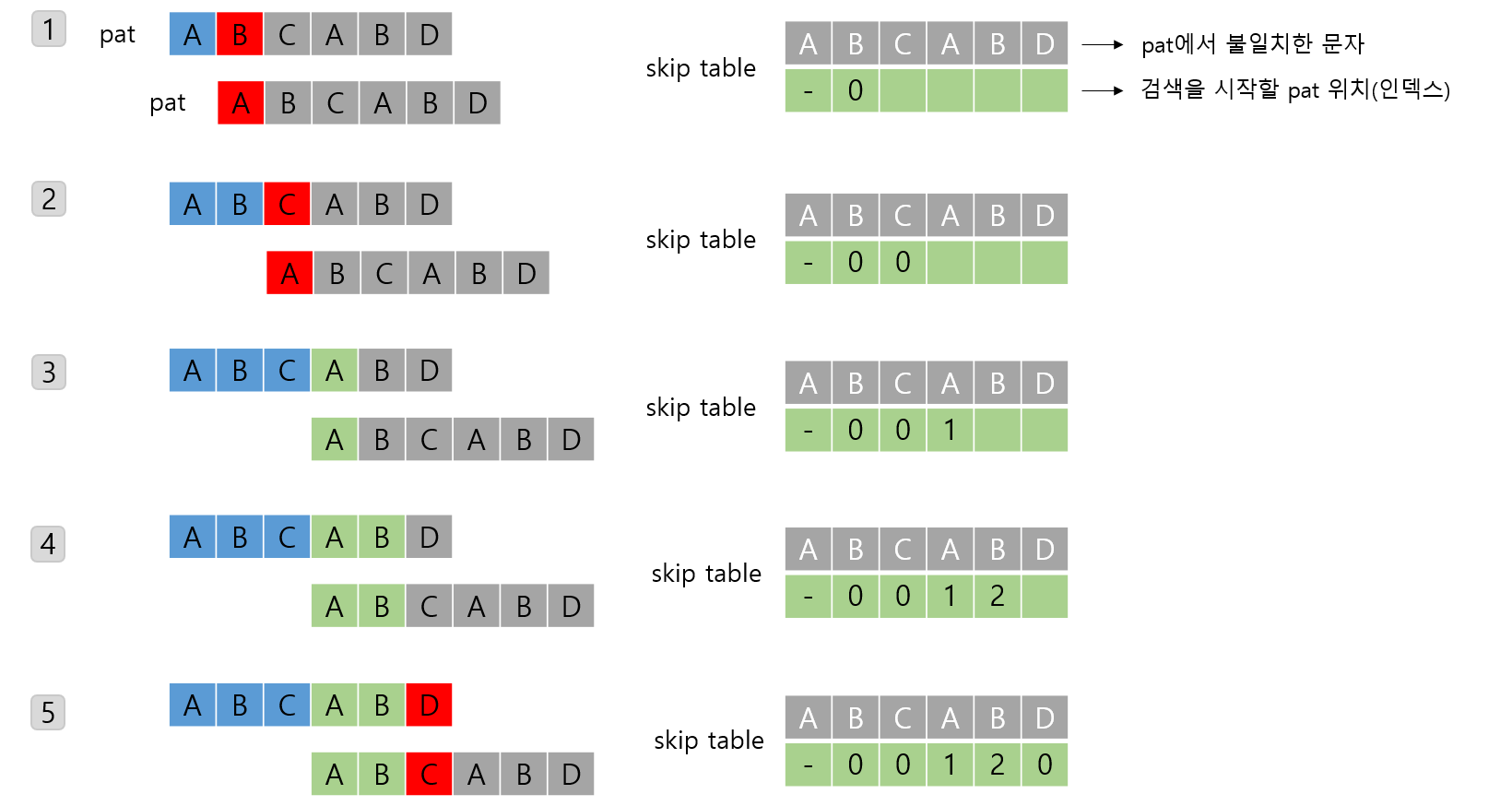
표 만들기
- 패턴에서 겹치는 문자열 찾기
- 첫 문자가 일치하지 않으면 패턴을 오른쪽으로 1칸 밀어 첫 문자부터 검사
- 패턴끼리 서로 겹치도록 맞추고 검사를 시작할 곳을 계산
건너뛰기 표 ( Skip Table )
※ 클릭 시 출처로 이동
const kmpMatch = (text: string, pattern: string):number => {
let TEXT_IDX = 1;
let PATTERN_IDX = 0;
const skip = new Array(pattern.length);
skip[TEXT_IDX] = 0;
while (TEXT_IDX != pattern.length) {
if (pattern[TEXT_IDX] === pattern[PATTERN_IDX]) {
TEXT_IDX++;
PATTERN_IDX++;
skip[TEXT_IDX] = PATTERN_IDX;
} else if (PATTERN_IDX === 0) {
TEXT_IDX++;
skip[TEXT_IDX] = PATTERN_IDX;
} else {
PATTERN_IDX = skip[PATTERN_IDX];
}
}
TEXT_IDX = 0;
PATTERN_IDX = 0;
while (TEXT_IDX !== text.length && PATTERN_IDX !== pattern.length) {
if (text[TEXT_IDX] === pattern[PATTERN_IDX]) {
TEXT_IDX++;
PATTERN_IDX++;
} else if (PATTERN_IDX === 0) {
TEXT_IDX++;
} else {
PATTERN_IDX = skip[PATTERN_IDX];
}
}
return PATTERN_IDX === pattern.length ? TEXT_IDX - PATTERN_IDX : -1;
};
console.log("result :", kmpMatch("tomcat", "cat"));
console.log("result :", kmpMatch("tomato", "cat"));4. 보이어 무어법
Boyer-Moor Method
- KMP법보다 더 효율적
- 실제 문자열 검색에서 널리 사용하는 알고리즘
- 패턴의 끝 문자에서 시작하여 앞쪽을 향해 검사를 수행
- 일치하지 않는 문자를 발견하면 미리 준비한 표를 바탕으로 패턴이 이동하는 값 결정
표 만들기
CASE 1
패턴에 포함되지 않는 문자를 만난 경우
패턴에 포함되지 않는 문자 ⇒ 패턴 이동량이 곧 n
CASE 2
패턴에 포함되는 문자를 만난 경우
마지막에 나오는 위치의 인덱스가 k이면 이동량은 n - k - 1
같은 문자가 패턴 안에 중복해서 존재하지 않으면 패턴의 맨 끝 문자의 이동량은 n
텍스트 : 'ABCXDEZCABACABAC'
패턴 : 'ABAC'
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
const boyerMoor = (text: string, pattern: string): number => {
const skip = new Array(256).fill(pattern.length);
for (let i = 0; i < pattern.length; i++) {
const UNICODE_IDX = pattern.charCodeAt(i);
skip[UNICODE_IDX] = pattern.length - i - 1;
}
let TEXT_IDX = pattern.length - 1;
while (TEXT_IDX < text.length) {
let PATTERN_IDX = pattern.length - 1;
while (text[TEXT_IDX] === pattern[PATTERN_IDX]) {
if (PATTERN_IDX === 0) return TEXT_IDX;
TEXT_IDX--;
PATTERN_IDX--;
}
const UNICODE_IDX = text.charCodeAt(TEXT_IDX);
if (skip[UNICODE_IDX] > pattern.length) TEXT_IDX += skip[UNICODE_IDX];
else TEXT_IDX += pattern.length - PATTERN_IDX;
}
return -1;
};
console.log("result :", boyerMoor("tomcat", "cat")); // result : 3
console.log("result :", boyerMoor("tomato", "cat")); // result : -1
console.log("result :", boyerMoor("ABABCDEFGHA", "ABC")); // result : 25. 시간 복잡도
브루트 포스법
- O(mn)
- 일부러 꾸며 낸 패턴이 아니라면 O(n)
KMP법
- 최악의 경우에도 O(n)
- 처리하기 복잡하고 패턴 안에 반복이 없으면 효율이 좋지 않음
- 파일을 차례로 읽어 들이면서 검색할 때 사용하기 좋음
보이어 무어법
- 최악의 경우에도 O(n)
- 평균 O(n/m)
- 배열 2개로 알고리즘을 구현하면 배열을 만드는 데 복잡한 처리 과정이 필요해져 효율성이 떨어짐

안녕하세요 : ) 천천히라도 꾸준히 성장하고 싶은 개발자 DOHEE 입니다! ( 프로필 이미지 출처 : https://unsplash.com/photos/_FoHMYYlatI )