본 논문은 사람 이미지에서의 포즈를 바꿀 때, 포즈들 사이에서 misalignment 문제를 해결하는 방법에 대해서 다룹니다.
논문
https://ieeexplore.ieee.org/document/8578457
Github
https://github.com/AliaksandrSiarohin/pose-gan
1. Introduction
이 논문은 관절이 있는 인체와 같이 시점의 변화나 변형 가능한 움직임으로 인해 전경 물체가 변화하는 이미지를 생성하는 문제를 다룹니다. 목표는 주어진 이미지에서 특정 사람의 모습과 다른 이미지에서 같은 사람의 포즈라는 두 가지 다른 변수를 조건으로 인간 이미지를 생성하는 것입니다. 그러나 일반적인 GAN (Generative Adversarial Network) 또는 VAE (Variational Autoencoder)는 관절형 객체 생성 문제를 다루지 않습니다. Conditional GAN(CGAN)은 일부 조건화 변수에 따라 모양이 달라지는 이미지를 합성 할 수 있습니다. 그러나 이러한 방법은 condition image와 target image 사이의 큰 공간 변형을 처리 할 때 문제가 있습니다. condition image와 target image는 아래 그림과 같이 서로 대략적으로 정렬돼있어야 하며, 동일한 기본 구조를 나타내야 합니다. 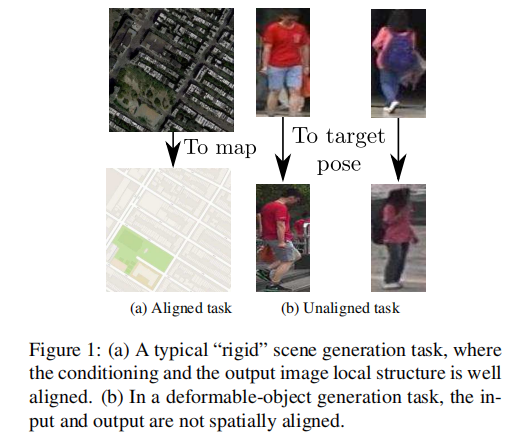
이러한 가정은 target image의 전경 물체(person)가 condition image사이의 큰 공간 변형(포즈 차이가 심함)을 겪을 때 위반됩니다. 또한 L1이나 L2 loss, perceptual loss는 공간 오정렬(spatial misalignment)은 고려하지 않습니다.
따라서 이 논문에서는 이러한 오정렬 문제를 처리하고 특정 포즈 차이의 로컬 정보를 "shuttle"하기 위해 "deformable(변형 가능한) skip connection"을 제안합니다. 또한 conditional GAN 방식에서 일반적으로 사용되는 일반적인 pixel-to-pixel loss (L1 또는 L2 loss)을 대체하기 위해 "Nearest Neighbor Loss"를 제안합니다.
2. Related Works
(생략)
3. The Proposed Method

xa : Condition Image
xb : Target Image
P(xa) : Condition Pose (OpenPose 사용, 관절 18개)
P(xb) : Target Pose (OpenPose 사용, 관절 18개)
Ha : Heatmaps of each joint point in condition image
Hb : Heatmaps of each joint point in target image
H(P)는 아래의 수식을 통해 각 관절에 대한 blurry한 heatmap을 가지게 됨(σ = 6pixels)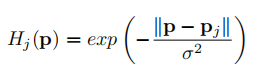
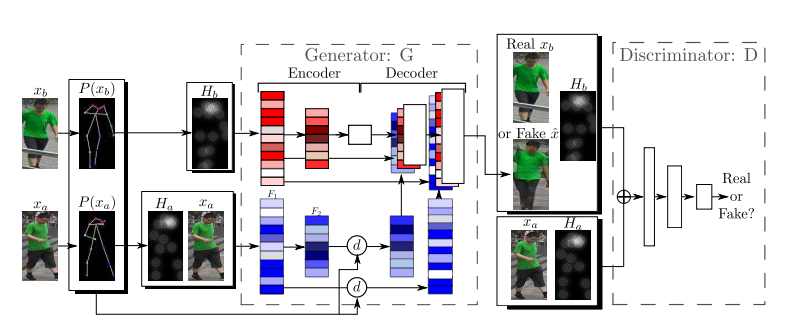
Generator G의 입력 값은 노이즈 벡터 z (그림에서는 z가 안나와있어서 어디다가 노이즈를 적용 하는건지....)와 Xa, Ha, Hb입니다. Xa 및 Ha의 관절 위치는 공간적으로 정렬되지만, Hb와는 다릅니다. 따라서 Hb는 다른 입력 텐서와 concat되지 않고 Hb와 (Xa,Ha)를 독립적으로 처리합니다.
구체적으로, xa와 Ha는 첫번째 Convolution stream을 사용하여 연결되고 처리되는 반면, Hb는 두 번째 Convolution stream에 의해 처리되며 두 개의 인코더는 가중치를 공유하지 않습니다. 첫 번째 스트림의 feature map에서는 deformable skip connections에 의해 수행된 포즈 기반의 공간 변형이 수행되고, 디코더에서 두 번째 스트림의 feature map과 합쳐지게 됩니다. Discriminator D는 4개의 텐서를 입력으로 취합니다 : (xa, Ha, y, Hb) 이 4개의 텐서는 연결되어 D에 입력으로 제공됩니다.
Deformable skip connections의 목표는 G의 인코더에서 디코더 부분으로 로컬 정보를 이동시키는 것입니다. 전송될 로컬 정보는 텐서 F에 포함되며, 텐서 F는 인코더의 컨볼루션 레이어의 feature map을 나타냅니다. 이를 위해 P(xa) 와 P(xb)의 관절들을 사용하고 local affine transformation 계산하여 전체적인 변형을 각 관절들 수준으로 분해합니다.
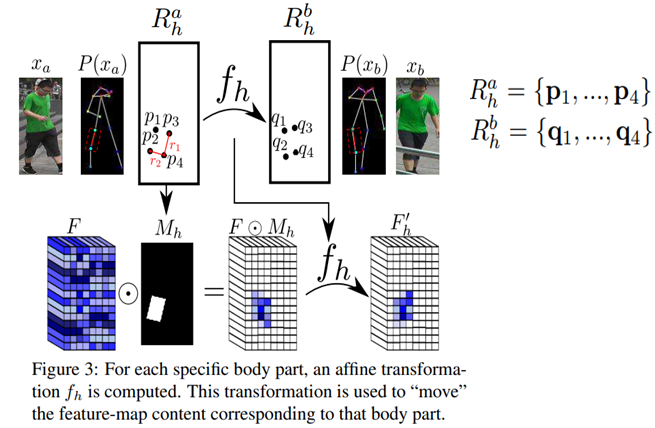
P(xa)의 관절을 잡아서 대략적인 직사각형 영역을 그립니다. 여기서 팔, 다리는 2개의 포인트를 감싸는 영역, 머리는 해당 포인트들을 감싸는 영역, 몸통은 배경 픽셀에 대한 텍스처 정보를 셔틀하기 위해 전체 이미지를 포함하는 영역, 총 10개의 영역을 사용합니다. Rah = {p1, ..., p4}는 xa에서 h(총 10개)번째 몸체 영역을 정의하는 4개의 직사각형 모서리를 가지는 set입니다. Rah를 사용하여 Rah 내부에 있는 점 p를 제외한 모든 곳이 0인 이진 마스크 Mh(p)를 계산할 수 있습니다. 또한 Rbh = {q1, ..., q4}는 xb의 해당 직사각형 영역입니다. Rah의 점을 Rbh의 해당 점과 일치시키면 신체 부위별 아핀 변환의 매개 변수를 계산할 수 있습니다.
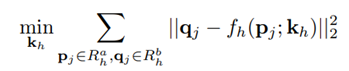 위의 식으로 Least Square Error를 사용하여 affine transformation fh(·; kh)의 6개 파라미터 kh를 계산합디다. 파라미터 kh는 xa 및 xb의 원래 이미지 해상도를 사용하여 계산된 다음, 각 feature map F의 특정 해상도에 맞게 조정됩니다.
위의 식으로 Least Square Error를 사용하여 affine transformation fh(·; kh)의 6개 파라미터 kh를 계산합디다. 파라미터 kh는 xa 및 xb의 원래 이미지 해상도를 사용하여 계산된 다음, 각 feature map F의 특정 해상도에 맞게 조정됩니다.
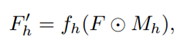
계산된 파라미터를 사용하여 feature map과 mask를 point-wise multiplication(곱)해서 해당 영역의 feature map만 추출합니다. 그리고, 위에서 적용한 affine transformation을 사용해서 원하는 포즈로의 feature map을 변경합니다. 마지막으로 변경된 feature map들을 병합합니다.
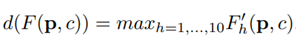
또한, 위의 식과 같은 두 몸체 영역이 부분적으로 서로 겹칠 때 최대 활성화 값을 선택하여 최종 변형된 텐서 d(F)를 얻는다는 것입니다!
요약하자면, 인코더의 feature가 skip connection을 진행할 때 위의 식들을 적용하여 feature (channel)를 변형시키고 디코더의 값들을 target image의 디코더 feature와 concat한다는 것입니다.
Loss Function
L1과 L2 loss의 문제는 흐릿한 이미지가 생성된다는 것입니다. 본 논문에서는 그 이유가 생성된 이미지와 타겟 이미지 사이의 작은 공간적 오정렬을 견디지 못하기 때문이라고 합니다. 사람이 볼 때는 별로 중요하지 않다고 볼 수 있지만, L1 및 L2 loss는 부정확한 픽셀 수준에서의 정렬이 불이익을 준다고 합니다. 이 문제를 완화하기 위해 이 모델에서는 "Nearest Neighbor Loss"를 제안했습니다.
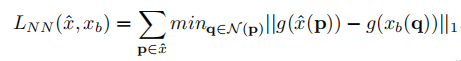
g(x^(p))는 컨벌루션 필터를 사용하여 얻은 이미지 x의 관절 포인트 p주변 패치(5x5)의 벡터 표현이며, 계산을 위해 VGG-19의 컨벌루션 맵에서 계산된 (g())을 사용하여 x^ 및 xb의 패치를 비교합니다(VGG-19의 conv1_1과 conv1_2사용). Generator와 Discriminator는 Nearest Neighbor Loss과 conditional GAN의 Loss를 조합하여 학습됩니다.
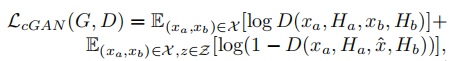
최종 Loss Function은 다음과 같습니다.
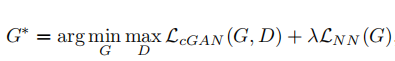
4. Experiments
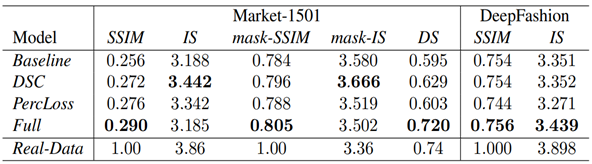
dataset : Market-1501, DeepFashion
아래 표를 보면 기존 방법보다 개선효과가 있다는 것을 알 수 있습니다.

또한, Deformable한 방법과 Nearest Neighbor Loss를 같이 썼을 때 효과가 좋다는 것을 볼 수 있습니다.

5. Conclusion
본 논문에서는 외모와 포즈를 조건으로 한 사람의 이미지 생성을 위한 GAN 기반 접근법을 제시하였다. "Deformmable skip connection"과 "Nearest Neighbor Loss"라는 두 가지 새로운 방법을 제시했습니다. 새로운 점은 변형 가능한 객체를 처리할 때 U-Net 기반의 Generator에 일반적인 문제를 해결하는데 사용되고, 생성된 이미지와 실제 실제 이미지 사이 misalignment(오정렬)를 완화했다는 것입니다.
후기
일단, 신체의 정렬 문제를 해결했다는 점에서 참신했습니다. 하지만 관절 포인트를 이용하여 rectangle 영역을 만들 때 너무 대략적인 느낌이 있었고 변형하는 과정도 깔끔하게 다가오는거 같지는 않습니다....
