DB index? (mysql, postgresql 의 index table 는 b-tree )
- ==데이터베이스에서 인덱스를 사용하는 이유는 검색성능을 향상시키기 위함입니다. 또한 데이터를 정렬합니다. 조인성ㄴ으을 개선할 수 있습니다. 일반적인 경우의 단점으로는 인덱스를 구성하는 비용 즉, 추가, 수정, 삭제 연산시에 인덱스를 형성하기 위한 추가적인 연산 및 약 10% 추가공간 차지 등 수행됩니다. 따라서, 인덱스를 생성할 때에는 트레이드 오프 관계에 놓여있는 요소들을 종합적으로 고려하여 생성해야합니다. b-tree or b+tree구조 입니다. 클러스터드 인덱스, 논클러스터드 인덱스(unique, 정렬안되어있으나 더 많은 공간요구)
- 빠르게 조회하기 위해 사용. (JPA는 엔티티의 @table에 @index로 셋팅)
- 테이블의 컬럼 사본을 정렬해둔 것이 INDEX, (데이터 1억개 전제, index 없으면 모든 데이터 전부조회)
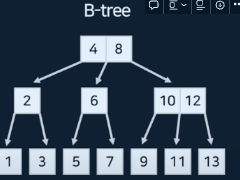
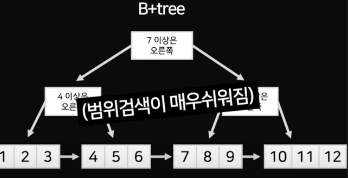
- DB는 데이터를 B-TREE 모형 배치.(2번 질문으로 찾을 수 있는데이터가 BST 보다 많음), 실제로 DB는 데이터를 B+tree 사용 경우 많음, 범위 검색도 쉬워짐. 실제 데이터 배치 안바꿔도됌.
- 인덱스 재구성의 오버헤드==단점은 하드용량 차지, 기존 데이터 추가 삭제 시 인덱스 컬럼도 재정렬해야되서 시간 추가,primary key는 clustered index로 써 정렬되어 있음 이미.
- 클러스터드 인덱스는 정렬된 상태로 저장되는 인덱스, 논 클러스터 인덱스는 정렬안된채로 저장 인덱스 (unique 컬럼 옵션), 논 클러스터 인덱스는 키밸류로 값 찾아오는데, 정렬되지 않은 id는 어떤 주소를 참조하고, 그 주소에 값이 있음. 더 많은 디스크 공간 요구
카디널리티 ( == 어떤 값을 인덱스로 삼을지 == 높은 카디널러티 == 낮은 중복데이터)
- 카디널리티(Cardinality)는 인덱스 대상되는 컬럼입니다. 높을 수록 중복성이 낮아서 권장됍니다. 중복데이터(성별-남,여) 많을 수록 카디널리티는 낮아집니다. 하지만 email 같이 중복성이 낮아도 비교 효율이 무척 떨어지는 컬럼이 있음을 유의해야 합니다, email의 경우 클러스터드인덱스보다, unique 같은 논 클러스터 인덱스 주는게 낫습니다.
- 데이터에 접근하는 시간복잡도가 O(1)인 hash table 이 더 효율적일 것 같은데, B-tree 사용이유.
- hash table 을 사용하게 된다면 등호(=) 연산이 아닌 부등호 연산의 경우에 문제가 발생한다. 동등 연산(=)에 특화된 `hashtable`은 데이터베이스의 자료구조로 적합하지 않다.