[CS] DATABASE
1.[DB] DATABASE

== 데이터베이스는 데이터의 독립성, 무결성, 보안성, 일관성, 중복최소를 위해 사용됍니다. 그 전에 파일 시스템을 이용하여 데이터 관리하는 방식을 개선하기 위해 사용 됍니다.데이터의 독립성물리적 독립성 : 데이터베이스 사이즈를 늘리거나 성능 향상을 위해 데이터 파일을
2.[DB] DBMS, 질의처리기, 옵티마이저, DB 저장공간
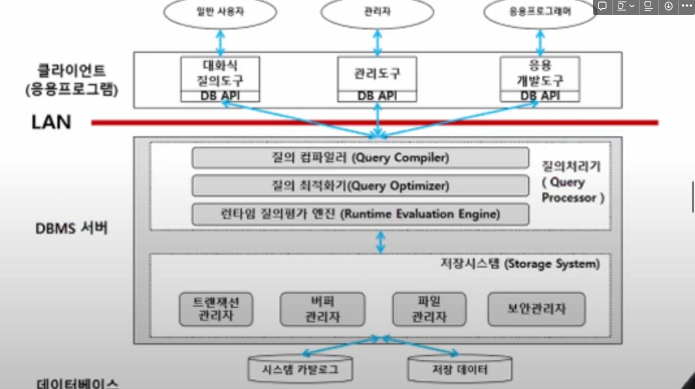
== DBMS는 데이터 베이스 내 데이터에 접근하도록 도와주는 시스템입니다. 사용자 인터페이스, 쿼리처리기, 데이터베이스 엔진, 데이터 저장소 등으로 구성. . (mysql, oracle, postgreSQL)
3.[DB] JDBC vs ODBC
==JDBC(Java Database Connectivity)와 ODBC(Open Database Connectivity)은 데이터베이스에 접근하기 위한 API(Application Programming Interface)입니다. JDBC는 자바 언어를 사용하여
4.[DB] DDL, DML, DCL
== DDL, DML, DCL은 데이터베이스 관리 시스템(DBMS)에서 사용되는 데이터 조작 언어의 세 가지 범주를 나타냅니다. DDL (Data Definition Language)의 약자로 디비 구조 정의 및 관리합니다. CREATE TABLE, ALTER TABL
5.[DB] 시퀀스, 트리거
==시퀀스는 일련의 숫자 값을 자동으로 생성하는 객체입니다. 주로 고유한 식별자(ID) 값을 생성하기 위해 사용됩니다. 시퀀스는 증가하는 숫자 값을 반환하며, 일반적으로 정수 형태의 값을 생성합니다. 시퀀스는 주로 기본 키(PK) 값을 자동으로 생성하는 데 사용되어 테
6.[DB] 무결성, 정규화, 반정규화, ANOMALY
==무결성은 데이터베이스에서 데이터의 낮은중복성을 보장하는 것을 의미합니다. 데이터베이스의 무결성은 데이터의 불변성과 제약 조건의 준수를 보장하여 데이터의 신뢰성을 유지합니다. 개체무결성, 참조무결성, 도메인무결성, 무결성 제약조건 등이 있습니다.개체 무결성(Enti
7.[DB] MYSQL, POSTGRESQL 특징
==MySQL은 높은 성능과 확장성에 중점을 둔 경량 데이터베이스이며, PostgreSQL은 더 많은 고급 기능과 객체-관계형 모델링을 지원하는 데이터베이스입니다. 선택은 사용자의 요구사항과 프로젝트의 특성에 따라 달라질 수 있습니다.
8.[DB] NOSQL (NOT ONLY SQL) , REDIS, 엘라스틱 서치, CAP 이론
==NOSQL은 not only SQL의 약자로 sql 을 보완한다는 의미를 가집니다. 스키마가 없어서 데이터 저장에 유연합니다. 조회 및 삽입 속도가 빠릅니다. 대량 분산 데이터 저장에 특화되어 있습니다. 레디스와 몽고 디비가 있습니다. 스타트업에 적합합니다.정형화
9.[DB] 파티셔닝, 샤딩
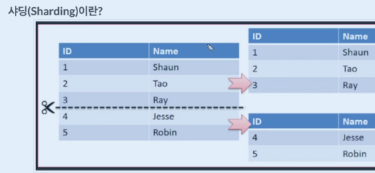
== 테이블을 컬럼단위로 나누는 기법입니다. 버티칼 파티셔닝이라고 합니다. 장점은 업데이트나 인서트 같은 작업이 분산되어서 성능 향상됩니다. 단점은 테이블간 join 비용 증가하게되고, index를 별도로 파티셔닝 할수없다는 단점을 가지고 있습니다.데이터를 컬럼단위로
10.[DB] JOIN , HAVING
==JOIN은 관계형 데이터베이스에서 두 개 이상의 테이블을 연결하여 하나의 결과 집합을 생성하는 기능입니다. A,B테이블 있다는 전제에서, A테이블 기준 레프트 조인은 오직 A테이블기준 B데이터의 교집합 데이터를 반환하기도 반환하지 않기도 합니다. A테이블 기준 라이
11.[DB] MYSQL 백업 & 복원
- mysql 백업 및 복원
12.[DB] SQL CACHE, NO_CACHE
• SQL_CACHE는 실행 결과를 캐시에 저장하도록 지정하는 명령입니다. 주로 데이터가 자주 변경되지 않거나, 데이터의 일관성보다 쿼리의 실행 속도가 우선인 경우에 사용될 수 있습니다. 예시: SELECT SQL_CACHE column1, column2 FROM ta
13.[DB] DB 리소스 소비 개선 방법
== 데이터베이스 성능 이슈는 “I/O를 어떻게 줄일 수 있는지”와 밀접 관련있습니다. 반정규화, 쿼리튜닝(join), 인덱스 최적화(자주 검색되면서 높은 카디널리티), 쿼리 매개변수조정, 커넥션관리, 정기적 백업 및 유지보수를통한 데이터 무결성 및 불필요공간 제거.반
14.[DB] INDEX, 카디널리티, B-TREE
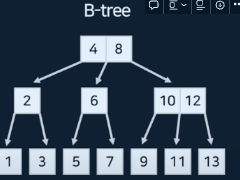
==데이터베이스에서 인덱스를 사용하는 이유는 검색성능을 향상시키기 위함입니다. 또한 데이터를 정렬합니다. 조인성ㄴ으을 개선할 수 있습니다. 일반적인 경우의 단점으로는 인덱스를 구성하는 비용 즉, 추가, 수정, 삭제 연산시에 인덱스를 형성하기 위한 추가적인 연산 및 약
15.[DB] PRIMARY INDEX, SECONDARY INDEX, COMPOSITE INDEX
== Primary index는 데이터베이스에서 기본 키(primary key)에 대한 인덱스입니다.Secondary index는 테이블의 기본 키 이외의 다른 열 또는 필드에 대한 인덱스입니다.==Composite index(복합 인덱스)는 데이터베이스에서 두 개 이
16.[DB] TRANSACTION ACID

== 데이터베이스의 정확성과 일관성을 위해서 트랜잭션은 4가지 특징을 만족해야 됍니다. 원자성은 한 트랜잭션 내 실행한 작업은 모두 성공하거나 실패해야되는 겁니다. 일관성은 자료형이 바뀌지 않는 등 일관성있는 데이터베이스 상태를 유지 시키는 것입니다. 격리성은 동시에
17.[DB] TRANSCATION PROPAGATION, ISOLATION, 선언적 트랜잭션
==스프링에서 트랜잭션은 인터페이스로 구현체만들어서 쓸수있지만, 주로사용한것은 AOP를 이용한 선언적 트랜잭션 곧, @transactional 을 주로 사용합니다. 분산 디비 시스템 사용시 주로 프로파게이션 사용하고, 또한 여러 트랜잭션 간 읽기 기능 제한하는 고립 옵
18.[DB] TRANSCATION 상태
== 트랜잭션 상태는 활동, 부분완료(작업 후 커밋 전), 완료(커밋 후 성공 종료), 실패(롤백 실행 상태), 철회(롤백 된 상태) 단계가 있습니다활동(Active): 트랜잭션이 시작되고, 데이터베이스 작업을 수행 중인 상태입니다. 데이터베이스의 변경 작업이 진행되고
19.[DB] 클러스터링과 리플리케이션
== 둘다 DB 생존성을 강화하는 방식입니다. 클러스터링은 DB 서버만 여러개 만들어서 작동시키고, 리플리케이션은 DB서버와 DB스토리지까지 복제하는 방식입니다.==클러스터링은 DB서버를 여러개 만들어서 DB 생존성을 강화하는 방식 입니다. active-active 는
20.[DB] SQL 인젝션
==sql 인젝션 방식은 로그인할때 등 인풋창에 “DELETE \* FROM USER WHERE IE = “1”;” 등과 같은 SQL 문을 사용하는 것입니다.
21.[DB] PERSISTANCE LAYER
==Persistence Layer(영속성 계층)은 소프트웨어 아키텍처에서 데이터를 영구적으로 저장하고 검색하는 기능을 담당하는 계층입니다. 영속성 계층은 데이터베이스나 파일 시스템과 같은 영구 저장소에 대한 접근을 관리하고, 데이터의 생성, 읽기, 업데이트, 삭제 (