Citus DB 연구
Citus DB?
Citus DB는 PostgreSQL(Postgres Extension)을 확장하여 대규모 데이터를 처리할 수 있는 분산 데이터베이스로 만들기 위한 오픈 소스 확장 기능입니다. Citus는 PostgreSQL의 샤딩, 분산 SQL 엔진, 분산 테이블 및 참조 테이블 기능을 사용하여 대규모 데이터베이스를 수평적으로 확장하고, 코디네이터 노드와 워커 노드 구조를 사용하여 쿼리를 병렬로 처리합니다. 이 방식은 큰 데이터 세트에 대해 높은 성능을 제공하며, 일반적으로 100GB 이상의 데이터에 대해 효과적으로 작동합니다.
코디네이터 및 워커 노드?
애플리케이션에서 코디네이터 노드로 쿼리를 보내고, 코디네이터 노드는 해당 쿼리를 워커 노드에게 전달하여 결과를 집계합니다.
코디네이터 노드는 메타데이터 테이블을 참고하여 수행할 작업을 결정합니다. 이러한 테이블은 워커 노드의 DNS 이름 및 상태와 노드 간 데이터 분산을 추적합니다.
또한, 분산 테이블의 각 쿼리에 대해 단일 작업자 노드로 라우팅하거나, 필요한 데이터가 단일 노드에 있는지 여러 노드에 있는지에 따라 여러 곳에서 병렬 처리합니다.
1. 분산 테이블
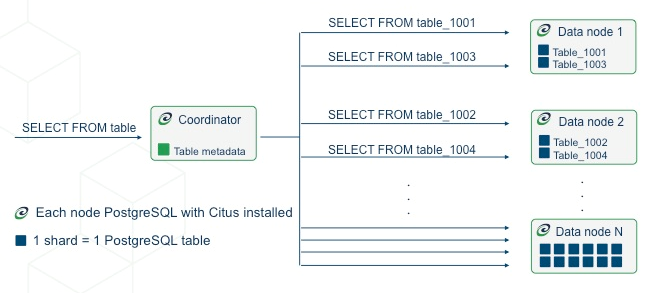
분산 테이블은 Citus 성능의 핵심입니다. 테이블을 분산하지 못하면 해당 테이블이 코디네이터 노드에 그대로 남아 있으므로 시스템 간 병렬 처리를 활용할 수 없습니다.
그림은 분산 테이블인 'table'에 대한 SELECT 문 실행의 예시입니다. 애플리케이션으로부터 코디네이터 노드에 'table'에 대한 SELECT문 요청이 들어왔을 때,
Table metadata를 참조하여 각 워커노드에 분산 저장된 테이블에 대한 메타정보를 얻어 병렬 처리를 하는 예시입니다.
Citus는 전체 클러스터에 걸쳐 SQL문 뿐만 아니라 DDL문도 실행할 수 있으므로, 분산 테이블의 스키마를 워커 노드의 모든 테이블 샤드에 대하여 계단식으로 변경이 가능합니다.
2. 분산 컬럼
분산 컬럼은 분산 테이블 생성 시 데이터를 각 워커노드에 어떻게 나누어 저장할지 결정하는 중요한 요소이므로 분산 컬럼을 반드시 지정해야합니다.
분산 컬럼의 선정은 쿼리 성능과 SQL 호환성에 중요한 영향을 미칩니다. 만일 분산 컬럼이 부적절하게 선정되었다면, 불필요한 성능저하와 일부 SQL 쿼리가 작동되지 않을 수 있습니다.
3. 참조 테이블
참조 테이블은 모든 정보가 단일 샤드로서 집중되어 저장되어 복제되는 형태로 모든 워커 노드에 복제되는 분산 테이블의 한 종류입니다.
그러므로 워커 노드에서의 모든 쿼리는 자신이 가진 참조 테이블 복제본을 직접 접근할 수 있으므로 다른 노드로부터의 요청에 따른 네트워크 오버헤드 없이 작업을 수행할 수 있습니다. 참조 테이블은 row 단위로 샤드를 구분할 필요가 없기 때문에 분산 컬럼은 필요하지 않습니다.
참조 테이블은 주로 크기가 작고, 모든 워커 노드에서 실행될 필요가 있는 공통 데이터에서 활용합니다.
예를 들어, 큰 사이즈의 분산 테이블과 join이 필요한 작은 테이블이나, 여러 열에 걸쳐 고유한 제약 조건이 필요한 작은 테이블 등이 있습니다.
4. 로컬 테이블
Citus에서 코디네이터 노드는 스탠다드 PostgreSQL과 Citus Cluster를 모두 사용할 수 있습니다.
그러므로, 분산 테이블을 생성하지 않으면 일반 테이블과 동일하게 사용이 가능합니다. 이는 애플리케이션 유저나 로그인, 인증 정보와 같은 작은 관리용 테이블로 적합합니다.
4-1. 샤드
SELECT * from pg_dist_shard;
logicalrelid | shardid | shardstorage | shardminvalue | shardmaxvalue
---------------+---------+--------------+---------------+---------------
github_events | 102026 | t | 268435456 | 402653183
github_events | 102027 | t | 402653184 | 536870911
github_events | 102028 | t | 536870912 | 671088639
github_events | 102029 | t | 671088640 | 805306367
(4 rows)
워커 노드 내의 더 작은 테이블에 있는 분산 테이블 row의 하위 집합을 포함하는 단위입니다.
샤드에 대한 정보는 코디네이터 노드의 메타데이터 테이블인 pg_dist_shard에 저장되어 있습니다.
예를 들어, 코디네이터 노드가 특정 row를 가지고 있는 샤드를 확인하려는 경우 해당 행의 github_events 분산 컬럼 값을 해시하고, 해시된 값이 포함된 샤드의 범위를 확인합니다.
SELECT
shardid,
node.nodename,
node.nodeport
FROM pg_dist_placement placement
JOIN pg_dist_node node
ON placement.groupid = node.groupid
AND node.noderole = 'primary'::noderole
WHERE shardid = 102027;
┌─────────┬───────────┬──────────┐
│ shardid │ nodename │ nodeport │
├─────────┼───────────┼──────────┤
│ 102027 │ localhost │ 5433 │
└─────────┴───────────┴──────────┘
만약 해당 row가 shardid가 102027과 연결이 되어있다고 가정한다면, github_events_102027은 워커노드 중 하나에서 호출된 테이블의 행을 읽거나 쓰는 것을 의미합니다.
이러한 과정은 전적으로 메타데이터 테이블에 의해 결정되며, 특정 샤드가 어떤 워커노드와 매핑되는지 알 수 있습니다.
샤드는 데이터 손실을 방지하기 위해 각 워커 노드간의 복제가 이뤄질 수도 있습니다. Citus에서는 2가지 복제 옵션을 제공합니다.
첫 번째로 Citus 복제는 추가로 백업용 샤드를 미리 배치하고, 그 중 하나를 업데이트하는 모든 쿼리를 실행합니다.
두 번째 스트리밍 복제는 PostgreSQL의 스트리밍 복제를 활용하여 각 노드의 전체 데이터베이스를 Follower 데이터베이스에 복제합니다.
이는 Citus의 메타데이터를 테이블의 개입이 필요하지 않아 더욱 투명하고 효율적입니다.
5. Co-location
샤드와 해당 복제본은 원하는 대로 노드에 배치할 수 있으므로 관련 테이블의 관련 행을 포함하는 샤드를 동일한 노드에 함께 배치하는 것이 좋습니다.
이런 식으로 그들 사이의 조인 쿼리는 네트워크를 통해 많은 정보를 주고 받는 것을 피할 수 있고, 단일 Citus 노드 내에서 수행될 수 있게 합니다.
Co-location은 데이터를 전술적으로 나누는 방식으로, 관련 정보를 동일한 시스템에 유지하여 효율적인 관계형 작업을 가능하게 하지만 전체 데이터 세트에 대한 수평 확장성을 활용합니다.
데이터의 Co-location의 원칙은 데이터베이스의 모든 테이블에 공통 배포 열이 있고 동일한 방식으로 컴퓨터 간에 분할되어 배포 열 값이 동일한 행이 다른 테이블에서도 항상 동일한 노드에에 있다는 것입니다.
예를 들어, SaaS 환경에서의 웹 분석의 상황 중 tenant 6에의 '/blog'로 시작하는 모든 페이지에 대한 지난 주 방문 횟수를 구한다고 가정하겠습니다.
CREATE TABLE event (
tenant_id int,
event_id bigint,
page_id int,
payload jsonb,
primary key (tenant_id, event_id)
);
CREATE TABLE page (
tenant_id int,
page_id int,
path text,
primary key (tenant_id, page_id)
);
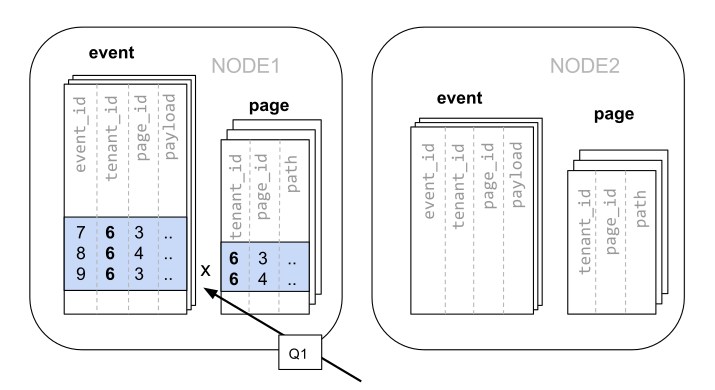
5-1. Co-location 미적용 시
-- 각 테이블의 id인 event_id와 page_id를 분산 컬럼으로 설정하여 분산 테이블을 생성
SELECT create_distributed_table('page', 'page_id');
SELECT create_distributed_table('event', 'event_id');
-- 단일 PostgreSQL 노드에서 하는 것처럼 단순히 조인을 수행할 수 없으므로 다음과 같이 두 가지 쿼리를 수행해야 합니다.
-- page 테이블의 모든 샤드(Q1)
SELECT page_id FROM page WHERE path LIKE '/blog%' AND tenant_id = 6;
-- event 테이블의 모든 샤드(Q2)
SELECT page_id, count() AS count
FROM event
WHERE page_id IN (/…page IDs from first query…*/)
AND tenant_id = 6
AND (payload->>'time')::date >= now() - interval '1 week'
GROUP BY page_id ORDER BY count DESC LIMIT 10;
-- 이후 Q1과 Q2의 결과를 join 해야하므로 큰 오버헤드가 발생합니다.
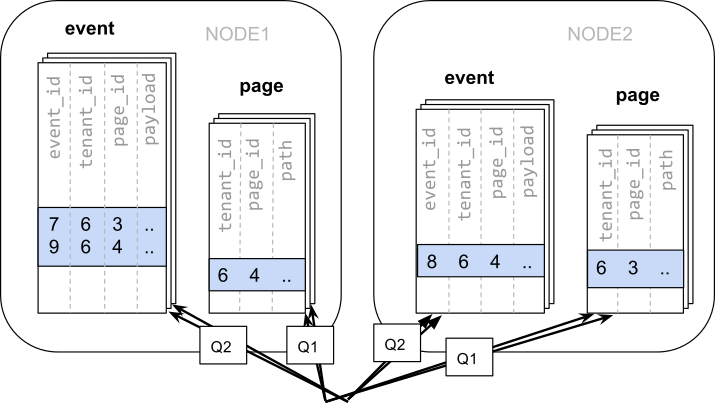
5-2. Co-location 사용 시
-- 두 테이블의 공통 id 컬럼인 tenant_id를 분산 컬럼으로 지정하고, 분산 테이블 생성 시 page 테이블을 event 테이블과 동일한 방식으로 배포
SELECT create_distributed_table('event', 'tenant_id');
SELECT create_distributed_table('page', 'tenant_id', colocate_with => 'event');
-- 이 경우 tenant_id를 기준으로 동일한 값을 가진 row는 동일한 워커 노드에 위치하므로 단일 PostgrSQL와 동일하게 모든 SQL문이 정상으로 작동합니다.
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
-- 예시에서는 tenant_id=6 필터가 있기 때문에 하나의 노드만 쿼리하지만 Co-location 사용 시 SQL 제한이 있는 경우
위와 같이 Co-location의 사용은 다음과 같은 Citus의 제약을 해결합니다.
같은 위치에 있는 단일 샤드 세트에 대한 쿼리에 대한 전체 SQL 지원
같은 위치에 있는 단일 샤드 세트에 대한 수정을 위한 다중 문 트랜잭션 지원
INSERT..SELECT를 통한 집계
외래 키
분산 외부 조인
푸시다운 CTE(PostgreSQL >=12 필요)
6. 쿼리 실행
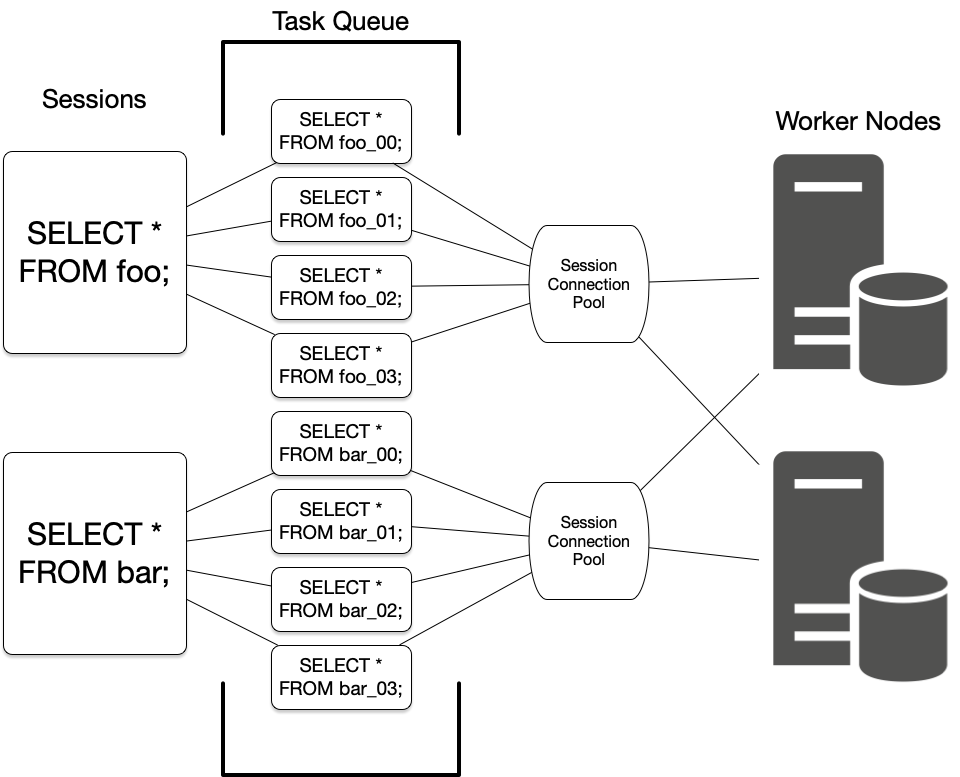
다중 샤드 쿼리를 실행할 때 Citus는 병렬 처리의 이점과 데이터베이스 연결의 오버헤드(네트워크 대기 시간 및 워커 노드 리소스 사용량)의 균형을 맞춰야 합니다.
데이터베이스 워크로드에서 최상의 결과를 위해 Citus의 쿼리 실행을 구성하려면 Citus가 코디네이터 노드와 워커 노드 간의 데이터베이스 연결을 관리하고 보존하는 방법을 이해해야 합니다.
Citus는 들어오는 각 다중 샤드 쿼리 세션을 태스크라고 하는 샤드별 쿼리로 변환합니다. 태스크를 큐에 넣고 관련 워커 노드에 연결할 수 있게 되면 작업을 실행합니다.
1) citus.max_adaptive_executor_pool_size
코디네이터 노드는 각 세션에 대한 커넥션 풀을 가집니다. 각 쿼리는 워커 노드당 태스크에 대해 최대 동시에 몇 개의 연결이 가능한지 결정합니다.
이 설정은 우선 순위 관리를 위해 세션 수준에서 구성할 수 있습니다.
2) citus.executor_slow_start_interval
다중 분할 쿼리에서 작업에 대한 연결 시도 간의 지연을 지정합니다.
새로운 연결을 병렬로 설정하는 것보다 동일한 연결을 통해 짧은 작업을 순차적으로 실행하는 것이 더 빠를 수 있습니다.
반면에, 장기 실행 작업은 보다 즉각적인 병렬 처리의 이점을 얻습니다.
3) citus.max_cached_conns_per_worker
연결을 사용하여 작업이 완료되면 세션 풀은 나중을 위해 연결을 유지합니다. 연결을 캐싱하면 조정자와 작업자 간의 연결 재설정 오버헤드를 피할 수 있습니다.
그러나 각 풀은 작업자의 유휴 연결 리소스 사용을 제한하기 위해 한 번에 열린 유휴 연결 이상을 보유하지 않습니다.
4) citus.max_shared_pool_size
모든 작업 간의 작업자당 총 연결 수를 제한하여 안전 장치 역할을 합니다.
7. 클러스터 관리
1) 하드웨어 사이즈 선택
예를 들어, 코디네이터 노드의 경우 컴퓨팅 리소스를 8 Core로 정했다면, 메모리는 8 4 = 32GB로 구성합니다.
워커 노드의 경우 컴퓨팅 리소스를 8 Core로 정했다면, 8 8 = 64GB로 구성합니다.
2) 클러스터 사이즈 선택
Citus는 각 쿼리 수행 시 샤드 단위로 워커 노드에 대한 연결을 생성하는데, 이 연결 수는 제한이 있으므로 무작정 샤드의 수를 늘리는 것은 적절하지 않습니다.
(최대 동시 연결 수 * 샤드 수)를 초과하지 않도록 하는 것이 중요합니다.
일반적으로 다루는 데이터의 워크로드가 100 GB 미만인 경우는 샤드의 수를 32로 설정하고, 그 이상으로 넘는 경우 최대 128로 설정합니다.
8. CITUS VS Postgresql 문법 비교
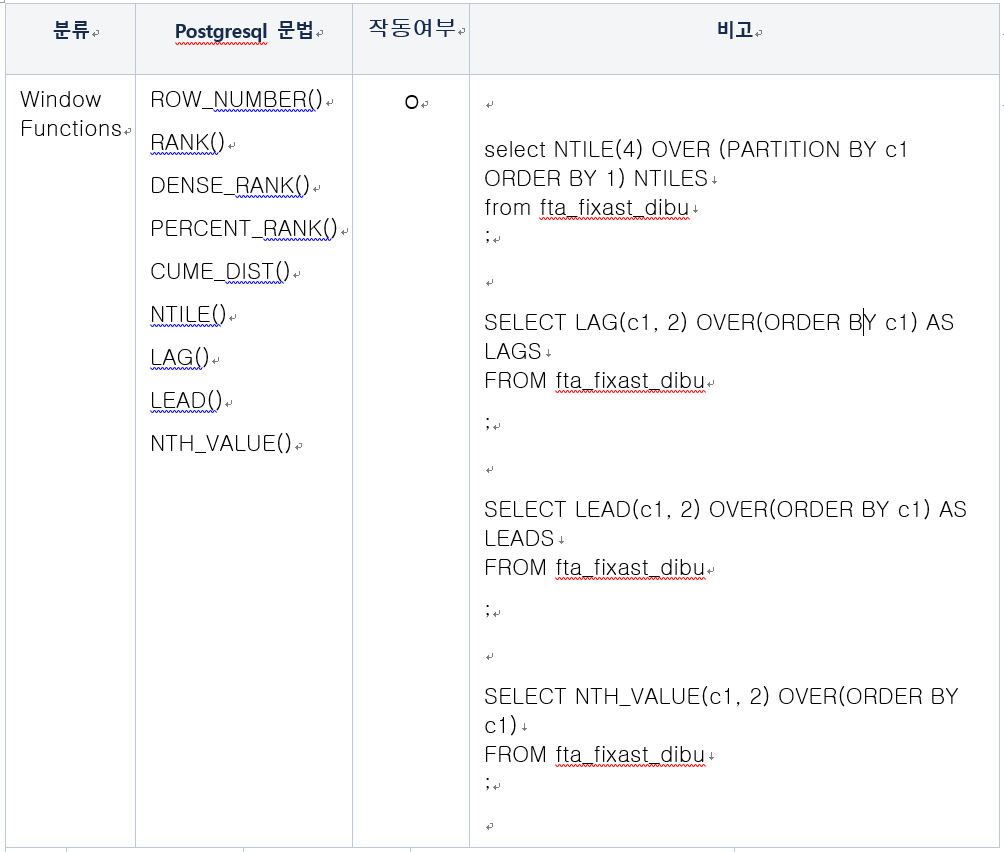
8-1. 테스트 준비
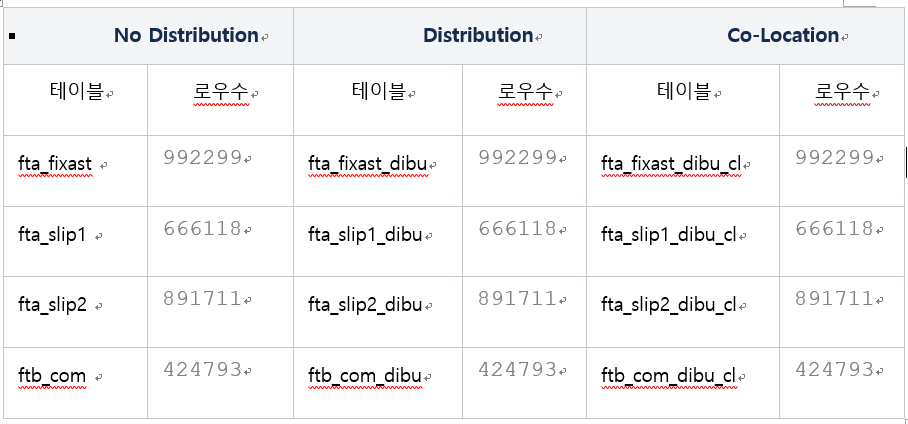
1) 테스트용 테이블
1-2) 제약조건 및 인덱스 생성
ALTER TABLE fta_fixast ADD PRIMARY KEY (c1,c2,c3);
ALTER TABLE fta_slip1 ADD PRIMARY KEY (c1,c2,c3);
ALTER TABLE fta_slip2 ADD PRIMARY KEY (c1,c2,c3);
ALTER TABLE ftb_com ADD PRIMARY KEY (ccode);
1-3) Distribution 설정
- ERROR: cannot create constraint without a name on a distributed table
- PK 제약조건 필요하면, Distribution 설정 전에 작업 해야함
SELECT create_distributed_table('fta_fixast_dibu', 'c1');
SELECT create_distributed_table('fta_slip1_dibu', 'c1');
SELECT create_distributed_table('fta_slip2_dibu', 'c1');
SELECT create_distributed_table('ftb_com_dibu', 'ccode');
1-4) Co-location 및 Distribution 설정
- ERROR: table "fta_slip1_dibu_cl" is already distributed
→ Co-location 설정시 이미 Distribution 테이블 설정 단계에서 동시에 진행
-- fta_slip1_dibu_cl 테이블 부터 Distrubution 테이블 설정
SELECT create_distributed_table('fta_slip1_dibu_cl', 'c1');
-- fta_slip2_dibu_cl 테이블은 'c1' 컬럼 기준으로 fta_slip1_dibu_cl 테이블과 Co-location 설정
SELECT create_distributed_table('fta_slip2_dibu_cl', 'c1', colocate_with => 'fta_slip1_dibu_cl');
-- fta_fixast_dibu_cl 테이블도 'c1' 컬럼 기준으로 fta_slip1_dibu_cl 테이블과 Co-location 설정
SELECT create_distributed_table('fta_fixast_dibu_cl', 'c1', colocate_with => 'fta_slip1_dibu_cl');
-- ftb_com_dibu_cl 테이블도 'c1' 컬럼 기준으로 fta_fixast_dibu_cl 테이블과 Co-location 설정
SELECT create_distributed_table('ftb_com_dibu_cl', 'c1', colocate_with => 'fta_fixast_dibu_cl');
1-5) 샤드 상태 및 분산테이블 확인
explain verbose
select * from fta_fixast_dibu
where c1='biz202112290022194'
;
explain verbose
select * from fta_fixast_dibu
where c1='biz202009290023509'
;
**2) 비교 쿼리 및 테스트 결과
2-1) 성능 측정, SQL 사용 가능 유무
