
Pod를 실행하는 과정에서 생긴 문제를 정리해보려 한다.
실행 환경
- Mac OS 버전 11.1
- Virtualbox - Red Hat(64-bit)
문제 정의
kubectl run으로 컨테이너를 실행할 새로운 파드를 생성하기 위해 kubectl run nginx --image=nginx 명령어를 사용하였다. 그리고 kubectl get pods 를 통해 pod의 상태를 확인해보았다.

위와 같이 STATUS가 Pending 상태로 한동안 지속되었다.
Pod의 생명 주기
- Pending : 쿠버네티스 시스템에 파드를 생성하는 중. 컨테이너 이미지를 다운로드한 후 전체 컨테이너를 실행하는 도중이므로 파드 안의 전체 컨테이너가 실행될 때까지 시간이 걸린다.
- Running : 파드 안 모든 컨테이너가 실행 중인 상태. 1개 이상의 컨테이너가 실행 중이거나 시작 또는 재시작 상태일 수 있다.
- Succeeded : 파드 안 모든 컨테이너가 정상 실행 종료된 상태로 재시작되지 않는다.
- Failed : 파드 안 모든 컨테이너 중 정상적으로 실행 종료되지 않은 커네이너가 있는 상태
- Unknown : 파드의 상태를 확인할 수 없는 상태. 보통 파드가 있는 노드와 통신할 수 없을 때이다.
10분이 지나도 20분이 지나도 계속 Pending 상태로 지속되어 무슨 문제가 있다고 판단하였다.
문제 분석
Pending 상태의 파드에 대해 상세하게 보기 위해 kubectl describe pod [pod name] 명령어를 사용하여 분석하였다.

Events에서 문제의 원인을 찾을 수 있었다.
n node(s) had taints that the pod didn't tolerate.
여기서 taint와 tolerate라는 용어가 등장하는데 간단히 정리하면 아래와 같다.
쿠버네티스 클러스터의 특정 노드에는 테인트(taint)를 설정할 수 있다. 테인트를 설정한 노드에는 파드들을 스케줄링하지 않는다. 만약 테인트를 설정한 노드에 파드들을 스케줄링하려면 톨러레이션(toleration)을 설정해야 한다. 그러면 테인트는 톨러레이션에서 설정한 특정 파드들만 실행하고 다른 파드는 실행하지 못하게 된다.
문제 원인 추론
테인트에 대해 확인하기 위해 master node의 정보를 살펴보았다.
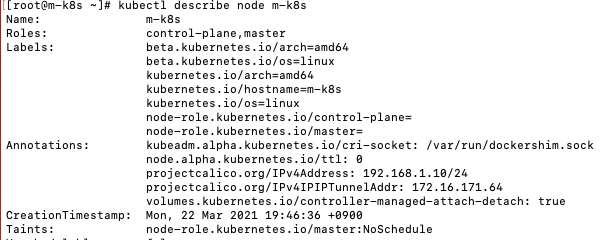
Taints 의 설정이 NoSchedule로 설정되어 있는것을 볼 수 있다. 여기서 만약 톨러레이션이 설정되어 있다면 파드를 스케줄링 할 수 있었을 것이다.
- NoSchedule : 톨러레이션 설정이 없으면 파드를 스케줄링하지 않는다. 기존에 실해되던 파드에는 적용되지 않는다.
- PreferNoSchedule : 톨러레이션 설정이 없으면 파드를 스케줄링하지 않는다.하지만 클러스터 안의 자원이 부족하면 테인트를 설정한 노드에서도 파드를 스케줄링할 수 있다.
- NoExecute : 톨러레이션 설정이 없으면 새로운 파드를 스케줄링하지 않으며, 기존 파드도 테인트 설정을 무시할 수 있는 톨러레이션 설정이 없으면 종료한다.
하지만 톨러레이션은 설정이 제대로 되어 있었다.
다시 파드의 정보를 살펴보면서 문제점을 발견할 수 있었다.
위에 출력한 pod의 정보에서 tolerations를 다시 한번 본다.

node.kubernetes.io/not-ready 와 node.kubernetes.io/unreachable가 톨러레이션에 추가된 것을 볼 수 있다.
node.kubernetes.io/not-ready: 노드가 준비되지 않았다. 이는 NodeCondition Ready 가 "False"로 됨에 해당한다.node.kubernetes.io/unreachable: 노드가 노드 컨트롤러에서 도달할 수 없다. 이는 NodeCondition Ready 가 "Unknown"로 됨에 해당한다.
쿠버네티스는 사용자나 컨트롤러에서 명시적으로 설정하지 않았다면, 자동으로
node.kubernetes.io/not-ready와node.kubernetes.io/unreachable에 대해tolerationSeconds=300으로 톨러레이션을 추가한다.
그리고 자동으로 추가된 이 톨러레이션은 이러한 문제 중 하나가 감지되면 5분 동안 파드가 노드에 바인딩된 상태를 유지한다.
이는 워커 노드와의 통신이 불가능하거나 에러가 발생했기 때문이다. 그래서 워커 노드를 살펴보니 워커 노드가 실행되고 있지 않았다. (허무,,,)
워커 노드를 실행하지 않았기 때문에 문제가 발생한 것이다.
문제 해결 방안
문제를 해결하기 위해 설치 중이던 파드를 삭제하고 워커 노드를 실행시킨 후 다시 파드를 생성하니 아니 문제가 발생하지 않았다.
앞으로는 시작하기에 앞서 모든 노드의 상태를 확인한 후에 진행해야겠다.
참고 자료
https://kubernetes.io/ko/docs/concepts/scheduling-eviction/taint-and-toleration/
https://waspro.tistory.com/563
https://m.blog.naver.com/alice_k106/221511412970
쿠버네티스 입문 : 90가지 예제로 배우는 컨테이너 관리 자동화 표준
