소개
자바의 값의 종류(데이터의 타입)은 크게 "기본형" 과 "참조형"으로 나눌 수 있다.
기본형

참조형
참조형은 우리가 작성하는 "클래스" 타입으로, 참조 변수에 저장된다. 참조변수는 4byte 또는 8byte 의 데이터를 저장할 수 있는데, 참조형이 어느 정도의 메모리공간을 다룰 수 있는 지에 대해서 알아두면 좋다.

RAM 내부의 논리적 메모리공간은 각
1byte로 구성되며양수를 인덱스로 가진다.
참조변수는"메모리주소"를 저장하는 변수이므로, 참조변수의 크기가 4byte 라는 것은 양수로2^32.
즉, 약 40억가지의 값을 표현할 수 있는 것인데, 메모리주소로 보았을때에, 약 40억개의 인덱스, 40억 byte 의 메모리공간[4GB]분량의 메모리주소를 저장할 수 있게 된다
-> OS 와 JVM 의 사용 메모리를 제외한 자바 프로그램 사용메모리는 2G도 안된다.
최근에는 64bit(8byte) OS 나 64bit(8byte) JVM 을 사용하므로, 참조변수는 8byte 의 크기를 가지며, 표현할 수 있는 값의 범위는 2^64 이다.
그러므로 참조 변수가 다룰 수 있는 메모리공간은 160경 byte, 1600만 TB 만큼의 메모리공간이다. 하지만 실제로 사용할 수 있는 메모리공간은 TB 정도이다.
// Date 객체를 생성 후 객체의 주소(메모리주소)를 참조변수에 저장
// Date 객체가 100번지에 있다면, 참조변수에는 100이 저장된다.
Date today = new Date();boolean
Java 의 논리형은 boolean 타입 하나만 존재한다. boolean 형 변수에는 논리 타입 리터럴인 true, false 만 저장할 수 있다.
논리형의 사용처는 대답(yes/no)과 스위치(on/off)에 사용되며, 2가지 값을 표현하므로 1bit(2^1)으로 충분하지만 Java 의 데이터의 최소단위는 1byte 이므로, boolean 타입 변수는 1byte의 크기를 가지게 된다.
boolean 타입 변수의
기본 값(초기화하지 않을 때 할당하는 값)은false이다.
boolean power = true; // 스위치
boolean checked = false; // 동의여부(대답)char
Java 의 문자형은 char 타입 하나만 존재한다. char 타입 변수에는 '로 감싸진 하나의문자인 문자형 리터럴을 대입할 수 있다.
문자형리터럴은 "유니코드"로 변환되어 char 타입 변수에 저장되며,
유니코드는 문자마다 번호를 매겨놓은 것으로, 양수로 이루어진 십진 정수 체계도 존재한다.
컴퓨터는 숫자 밖에 모르기 때문에 문자리터럴은 유니코드로 변환되어 char 타입 변수에 저장된다.
그러므로, 정수 리터럴을 이용하여 유니코드를 char 타입 변수에 직접 대입하는 것도 가능하다.
(출력할 때 유니코드 디코딩 방식을 사용하므로)
char ch = 'A'; // A 의 유니코드는 65이므로, 정수리터럴 65가 변수에 저장된다.
ch = 65; // 문자형 리터럴은 유니코드로 저장되므로, 유니코드 값의 정수타입 리터럴로 대입할 수 있다.
특정 char 타입 변수에 저장된 값이나 문자리터럴의 유니코드를 알고 싶다면, 캐스팅하면 된다.
char ch = 'A';//문자형 리터럴 대입
int code = (int)ch; // 문자의 유니코드를 알기 위해서 정수타입으로 캐스팅 후 저장
System.out.printf("%c = %d(%#x) %n", ch,code,code); //A = 65(0x41)
char hch = '가';
System.out.printf("%c = %d(%#x)",hch,(int)hch, (int)hch); //가 = 44032(0xac00)특수문자 (이스케이프 문자)
일반적인 문자 이외에 "약속된 특수문자"를 문자 리터럴로 표현하려면 \ (백슬래시) 를 이용하여 "이스케이프"시키며 해당 특수문자들을 이스케이프 문자라고 부른다.

System.out.println('\''); // 문자 리터럴에 이스케이프 문자 \' 를 표기
System.out.println("abc\t123\b456"); // char sequence 에 이스케이프 문자 \t \b 표기
System.out.println('\n'); // 문자리터럴에 이스케이프 문자 개행을 출력
System.out.println("\"Hello\"");// char sequence 에 이스케이프 문자 \" 표기
System.out.println("c:\\"); // char sequence 에 이스케이프 문자 \\ 표기
/**
* '
* abc 12456
*
*
* "Hello"
* c:\ < 파일 경로 표현시 \\ 백슬래시 이스케이프 필요
*/char 타입 표현형식
char 타입의 크기는 2byte 로 16bit 이고, 표현할 수 있는 값의 수는 2^16 = 65536가지 이다. 문자형 리터럴은 변수에 저장될 때 유니코드로 저장되며 유니코드는 다시 이진수로 변환되어 저장된다.
즉 문자형 리터럴의 "저장형식"은 정수형 리터럴과 같다.
하지만 정수 타입 과 문자 타입에는 결정적인 차이점이 있는데, 이는 표현 범위가 다르다는 것이다.
"유니코드 체계에는 음수가 필요없다."
그러므로char타입의 표현 범위는 "양수"이며, 정수 타입의 표현범위는 "음수를 포함"하기 때문에 표현범위의 차이가 발생한다.
2의 보수법에서 표현하는 방식으로 고려해보면, char 타입은 "부호비트를 수를 표현하는데 사용한다"는 뜻이 된다. 즉, char 타입은 16bit 를 온전히 수를 표현하는데 사용한다.
같은 2byte 크기를 가진 정수타입인 short 과 비교해보면 범위의 차이를 알 수 있다.
- char [2byte] :
0~(2^16) -1> 0~65535 - short [2byte] :
(-2^16-1) ~ (2^16-1) -1> -32768~32767
-1은 0의 표현,제곱의 -1 은 부호비트때문에 식에 추가된다.
// 두 가지 타입의 변수에 저장된 값의 형식은 동일
// 0000000001000001
char ch = 'A';
short sh = 65;
//PrintStream#println() 함수는 인자의 타입에 따라 출력 값을 다르게 표시한다.
System.out.println(ch); // A
System.out.println(sh); // 65여기서 가장 중요한 점은
값만으로는 값의 의미를 정확히 해석할 수 없다.는 것이다. 65라는 정수형 리터럴을 보고 'A' 인지, 65 인지 double 타입의 65.0 인지(프로모션) 알 수 없다.
값과 타입이 정해져야 비로소 값의 의미를 정확히 해석할 수 있게 된다.
인코딩과 디코딩
char 항목에서 보았듯이 문자 리터럴은 변수에 저장될 때, 숫자로 변환되어 저장된다. 컴퓨터는 숫자 외에는 모르기 때문이다.
문자리터럴의 변환기준은 유니코드를 따르며, 인코딩과 디코딩으로 변환된다.
인코딩:특정 방법으로 코드화,암호화 하는 것
디코딩:특정 방법으로 코드화,암호화한 값을 다시 원래 상태로 되돌리는 것
- 'A' -> 65 : 유니코드 인코딩 [ A 라는 문자를 유니코드라는 방법을 이용해서 65 로 코드화 ]
- 65 -> 'A' : 유니코드 디코딩 [ 65 라는 값을 유니코드라는 방법을 이용해서 A 로 문자화 ]
이렇듯
인코딩과디코딩에는기준(방법)이 필요하다. 방법을 모르면 "인코딩과 디코딩을 할 수 없다."
만약 엉뚱한 기준(방법)을 가지고 이미 인코딩된 값을 디코딩하면, 엉뚱한 값이 도출된다.
보통, 값을 쓰기[저장]할 때 인코딩시키며, 값을 읽기[출력]할 때 디코딩시킨다.
ASCII
정보 교환을 미국 표준 코드로, 128개의 문자 집합을 제공하는 7bit 부호이다.
처음 32 개는 인쇄,전송 제어용으로 출력이 불가능하며, 마지막 문자인 DEL 을 제외한 33 번째 이후 문자는 출력가능하다.
0~9, A~Z, a~z 등의 문자가 "순차적"으로 배치되어 있어 프로그래밍에 이점이 있다.
확장 아스키, 한글
데이터의 기본단위는 1byte 인데, ASCII 는 7bit 이므로, 남은 1bit 로 추가 문자를 정의한 것이 확장 아스키이다.
2^8 = 255, 128 가지의 추가 문자를 가지고 있다.
ISO(국제 표준화기구) 에서 정의한 확장 아스키의 표준들이 존재하는데, 대표적인 것이 ISO-8859-1 이다. 서유럽 권에서 일반적으로 사용되는 문자들을 포함하고 있다.
한글의 표현방식은 조합형/완성형으로 나뉘는데, 조합형은 초중종성을 조합하는 방식이며, 완성형은 확장 아스키의 일부영역의 두 개의 문자코드를 조합하는 방식으로 한글을 표현한다. 조합형은 사용되지 않고 있으며, 완성형에 없는 8822글자를 추가한 "확장 완성형(CP949)"가 사용되는데, 한글 윈도우의 문자 인코딩이다.
CP 란 코드페이지의 약자로, 256개의 문자를 어떤 문자로 변환할 것인지 적어놓은 문자의 코드표 란 뜻이다.
유니코드
지역별로 구성된 CP 들이 필요한 시점에서, 인터넷이 발명되면서 다른 지역의 다른 언어를 사용하는 컴퓨터 사이의 문서교환이 필요해졌다.
전 세계의 모든 문자를 하나의 통일된 문자의 집합(character set)으로 표현하고자하는 노력의 결과가 "유니코드"이다.
유니코드는 총 21bit 로 되어있으며, 유니코드에 포함시키고자하는 문자들의 집합을 정의해 놓았는데 이 것을 유니코드 문자셋 또는 캐릭터 셋(character set) 이라고 한다.
유니코드의 "캐릭터 셋"에 코드 번호를 붙여놓는 방식이 유니코드 인코딩이다.
종류는 UTF-8, UTF-16, UTF-32 등이 있다.
Java 는 UTF-16 을 사용하며, 웹에서는 보통 UTF-8 을 사용한다.
- UTF-16 은 모든 글자를 2 byte 의
고정크기로 표현 - UTF-8 은 모든 글자를 1 ~ 4 byte 의
가변크기로 표현
UTF-16 은 주로 사용되는 숫자, 영어를 2byte로 표현하고 있기 때문에, 문서의 크기가 커질 수 있다.
UTF-8은 영어,숫자는 1byte 이며 한글은 3byte로 표현하기 때문에, 문서의 크기가 작지만 크기가 가변적이라 다루기가 어렵다.
웹 환경(인터넷)에서는 전송 속도가 중요하므로 "문서의 크기가 작을 수록 유리하다." 그러므로 웹 환경에서는 유니코드 인코딩을 UTF-8 인코딩 으로 작성하는 일이 많다.
정수형 리터럴을 문자 타입으로 바꾸기
- 유니코드 인코딩 방식에 따라
'0'~'9'는 순차적으로 나열되어있다.
그러므로,숫자 + '0'은'숫자'가 된다.
// '0' + 1 -> 유니코드 인코딩
System.out.println((int) '0'); // 48
// '0' + 1 -> 유니코드 인코딩 -> 49 -> 유니코드 디코딩 -> '1'
// '0' + 2 -> 유니코드 인코딩 -> 50 -> 유니코드 디코딩 -> '2'
// '0' + 3 -> 유니코드 인코딩 -> 51 -> 유니코드 디코딩 -> '3'
System.out.println((char) (3 + '0')); // '3'정수형
정수형은 4개의 자료형이 존재하며, 각 자료형은 저장할 수 있는 값의 크기와 범위가 다르다.

byte ~ long 까지 자료형마다 2배씩 크기와 범위가 증가한다. 정수형의 기본 자료형은
int이다.
정수형의 표현형식과 범위
정수형 리터럴을 정수형의 어느타입에 대입해도 컴퓨터 메모리에 저장되는 값은 2진수이다. 이는 진법도 마찬가지이다.
컴퓨터는 2의 보수법을 사용하므로,
"변환된 숫자 리터럴의 2진수 값의 가장 앞 bit" 는 언제나 "부호비트"이다. 그러므로 실제 수를 표현하는데 사용하는 비트는 n-1 개가 된다. 양수를 표현하는데 있어서는 0 이 필요하기 때문에, 양수표현 범위에서 -1을 한다.
int 자료형의 표현 범위 :
-2^32-1~(2^32-1) -1
정수형의 선택기준
byte 는 파일 같은 "이진데이터 처리"에 사용되며, short 는 C언어와의 호완성에 사용된다.
정수형의 기본 자료형은 int 이다.
특별한 경우가 아니라면, byte / short 보다는 int를 사용하는 것이 좋다.
byte 와 short 의 범위는 작기 때문에, 연산시오버플로우가 일어나서 쓰레기 값이 저장될 수 있기 때문이다.
JVM 내부의 "피연산자 스택(operand stack)"에는 피연산자를 4byte 단위의 스택에 저장하기 때문에, 4byte 보다 작은 자료형(byte, short)의 연산에는 값을 4byte로 변환하여 연산이 수행된다. 그러므로 int 타입의 자료형을 사용하는 것이 변환할 필요가 없는 더 효율적인 연산이 된다.
특별한 경우가 아니라면 모두
int타입을 기본 정수형으로 사용하되, int 타입이 표현할 수 있는 범위(-21억~21억)를 넘어서는 값은long타입을 사용하는 것이 좋다.byte / short 는 성능보다는
저장공간이 중요할 때 사용한다.
정수형의 오버플로우
4bit 의 메모리 공간에 1111이 저장되어 있을 경우, 1을 더하면 어떻게 되는지 상상해보자.
- 올림현상이 일어나 10000 이 되지만, 4bit가 표현할 수 있는 bit 수(단위)를 넘어섰기 때문에, 1은 삭제된다.
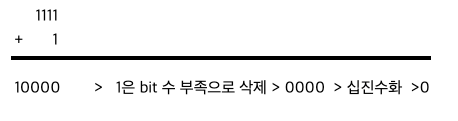
연산의 오버플로우는 에러가 발생하지 않는다.예상과 다른 값,
쓰레기 값이 도출된다.
연산과정에서 해당 타입이 표현할 수 있는 값의 범위를 넘어서는 것을오버플로우라고한다.
이번에는 4bit 의 메모리공간에 0000이 저장되어 있을 경우, 1을 빼면 어떻게 되는지 상상해보자.
- 0000 에서 1을 뺄 수 없기 때문에, "앞에 올림수가 있다고 가정하고 연산을 진행한다." 즉 다시 내림현상이 일어나 1111이 도출된다.
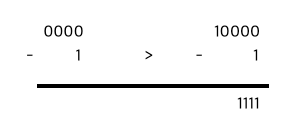
연산의 오버플로우가 발생하더라도, 연산결과는 해당 비트수가 표현할 수 있는 범위 안에 속해있다.
최대값 + 1:최소 값최소값 - 1:최대 값
부호가 있는 정수형이든, 부호가 없는 정수형이던 간에, 결과는 동일하다. 이는 char, short 타입의 오버플로우를 보면 알 수 있다.
public static void main(String[] args) {
short sMin = Short.MIN_VALUE;// 상수란, 값에 의미있는 이름을 지어주기 위해 사용하는 것이다.
short sMax = Short.MAX_VALUE;
char cMin = Character.MIN_VALUE;
char cMax = Character.MAX_VALUE;
// 오버플로우란, 연산과정에서 해당 타입이 표현할 수 있는 값을 넘어서는 것을 말한다.
/**
* int 타입 프로모션 때문에 연산 후 캐스팅진행
* 연산 후 캐스팅을 위해서 증감연산자를 변수이름 앞에 기술
*/
System.out.println((short)(sMin - 1)); // 32767
System.out.println((short)(sMax + 1)); // -32768
System.out.println((int) --cMin); // 65535
System.out.println((int) ++cMax); // 0
}실수형
실수형은 실수를 저장하기 위한 타입으로 float , double 두가지 타입이 존재한다. 실수 형에는 정밀도라는 것이 있는데, "온전히 표현할 수 있는 자릿수"를 의미한다.
실수 타입은 0에 최대한 가깝게 표현될 뿐, 완전하게 표현할 수는 없기 때문에, 양수와 음수 구간에 오차가 발생한다.
실수의 오버플로우 결과는 "infinity" 이며 양의 최소값 보다 더 0에 가까운 실수는 "0"이 된다.
https://www.secmem.org/blog/2020/05/15/float/
삼성소프트웨어멤버십 사이트
실수형은 같은 크기를 가진 정수형의 자료형보다 표현할 수 있는 값의 범위가 넓다. 이는 실수형이 값을 저장할 때 부동소수점수으로 저장하기 때문이다.

지수 : 2^n이다. 단위를 표현하며, 해당 수를 10진수로 표현하면 약10^n이 된다.
가수 : 실제 값을 의미하며 주어진 bit 만큼의 단위 수를 표현할 수 있다. 가수가 표현할 수 있는 단위가 정밀도가 된다.
부동소수점수 사용으로 같은 메모리크기로 정수형보다 더 많은 값을 표현할수 있으며, 이와 동시에 오차가 발생한다.
실수 타입의 정밀도를 결정하는 것은 가수에 주어진 bit가 표현할 수 있는 수의 단위 이다.
#해당 리터럴들은 모두 오차 없이 표현이 가능하다.
1234.567 = 1.234567 * 10^3
0.0001234567 = 1.234567 * 10^-5
1234567000 = 1.234567 * 10^9double 타입을 선언하는 이유는 대부분 "정밀도"가 되는 경우가 많다.
더 넓은 범위와 높은 정밀도 :
double
연산속도와 메모리 절약 :float
public static void main(String[] args) {
float f = 9.12345678901234567890f;
float f2 = 1.2345678901234567890f;
double d = 9.12345678901234567890;
System.out.printf("f : %f%n",f); //9.123457 %f 지시자는 소수점 6자리까지만 출력한다.
System.out.printf("f : %24.20f%n",f); // 9.12345695.. 앞의 7자리까지 일치
System.out.printf("f : %24.20f%n",f2); // 1.23456788.. 앞의 7자리까지 일치
System.out.printf("f : %24.20f%n",d); // 9.123456789012346.. 앞의 15자리까지 일치
}산술연산에러
0으로 나눌 수는 없으므로, 정수형 리터럴을 0 으로 나누면 산술연산 예외가 발생한다.
하지만, 실수형 리터럴 0.0으로 나누면 Infinity라는 값이 도출된다.
예외가 발생하지 않으므로, 연산 시 주의하는 것이 좋다.
public static void main(String[] args) {
double zero = 0; // 0.0
int zeroInt = 0;
System.out.println(15/zeroInt);
System.out.println(15%zeroInt);
//Exception in thread "main" java.lang.ArithmeticException: / by zero
System.out.println(15/zero); // Infinity
System.out.println(15%zero); // NaN ( Not a Number )
System.out.println(zero/zeroInt); // 0.0/0.0 > NaN
}