
Faster RCNN
- Pre-trained CNN을 통과함
- region proposal, boundary box 등등 실행
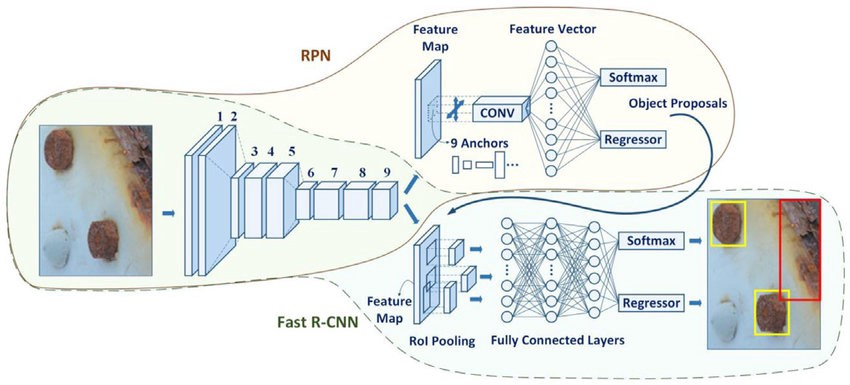
region proposal에 피쳐 맵이 들어간 뒤
pooling layer를 지나치며 224 -> 112 -> 56 -> 28 -> 14 -> 7으로 7 by 7의 형태로 바뀜
region proposal에는 3 by 3 convolution을 수행함
1x1 convolution을 통해 필터가 슬라이딩을 하며 모든 점을 돌면 하나의 맵이 나오게 된다.
3x3 conv 이후에 2k, 4k 1x1 conv를 통해 2개의 map, 4개의 map이 생성된다.
2k 에서는 object의 boolean을 판별할 수 있다.
4k 에서는 중심점이 어디인지에 대한 정보를 주고, 중심점으로 부터의 width, height의 정보를 준다.
IOU measure
측정도구 - Intersectin over Union
(예측값과 참값의)
IOU = 교집합 / 합집합
IOU값이 클수록 DETECT가 잘 된다
Boundary Box Regressor
오브젝트의 바운더리 박스의 좌표를 찾는 일
임시로 지정한 바운더리 박스가 오브젝트의 실제 바운더리 박스와 많이 다르면 어려워진다.
Anchor Box
정해진 크기와 비율을 가진 미리 정의된 후보 box
11, 22, 24, 84등 여러개의 사이즈를 가진 후보들을 만든다.
IoU < 0.6 => ‘non- object’ Anchor box
IoU > 0.6 => ‘object’ Anchor box
Background Anchor Box, Object Anchor Box인 9개의 정해진 크기와 비율을 가진 미리 정의된 후보 anchor box들이 한줄로 합쳐진다. 이것을 정답박스라고 한다.
Non-Max Suppression
앵커 박스들을 가능성에 의거해 지워가는 과정
region proposal 단계에서 Non-max supperssion을 사용해서 후보군을 추린다.
ROI Pooling
깊이는 똑같지만 각 맵에 대해서 각 세로에 대해 7 by 7으로 맞춰줌
Bilinear interpolation, Max Pooling
Yolo Model
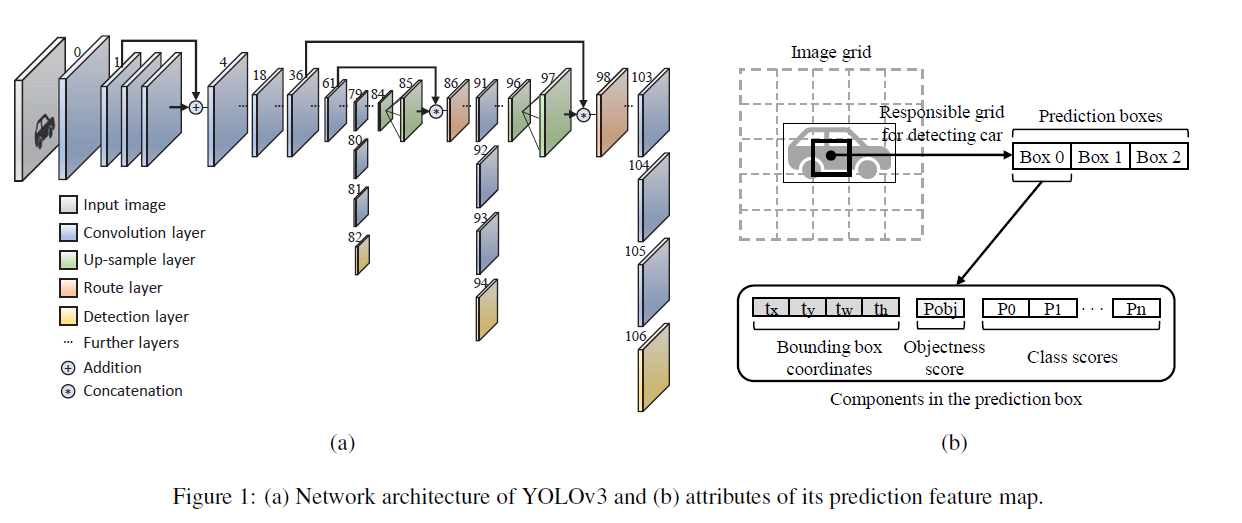
YOLO에서는 Ground truth box의 중심점을 포함하고 있는 부분이 있다.
Ground truth box의 중심점을 포함하고 있는 셀은 Positive, 나머지는 Negative가 됨.
Positive인 셀에 대해서만 Anchor Box들과 Ground Truth box를 비교해서
Positive인 셀이 가진 세로, 가로 앵커박스 중 IoU가 큰 것을 계산해서 선택함
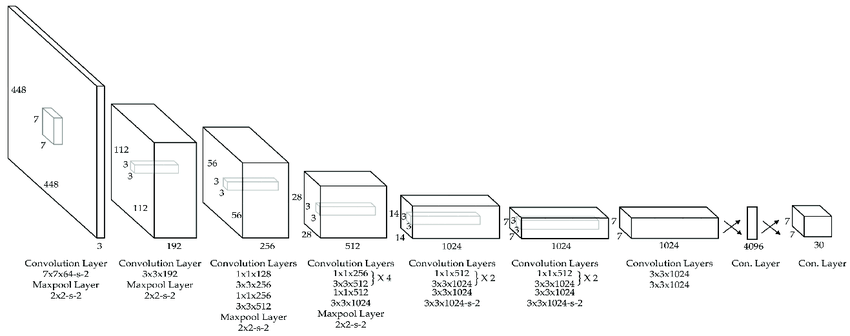
YOLO v3
v3 모델로 발전하면서, Pre-trained Network로 Darknet-53 모델을 사용하고 Anchor Box를 9개 가지며, K-means로 Anchor Box 크기를 결정하는 등의 변화가 생김
SSD(Single Shot Detector)
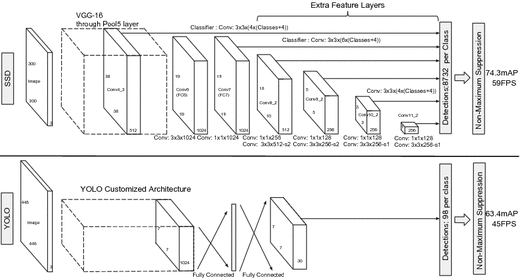
컨볼루션을 여러번 거치며 피쳐맵 사이즈가 조금씩 줄어들고 앵커박스를 추출함
NMS(non-maximum suppression)과정을 거치면서 겹치는 앵커박스를 탈락시킨다
Semantic Segmentation
자율주행 시 정교하게 위치와 크기를 detect하고, 인물사진을 처리하며 x-ray 흑백 의료영상에서 장기 위치 세그멘테이션을 할 수 있다.
픽셀 단위로 오브젝트를 구분하는 방식

한번씩 풀링을 해서 영상을 줄여가며 컨볼루션을 수행하다가 마지막에 크게 만들어서 다시 원래 영상 사이즈와 같아지게 한다 (Bilinear Interpolation, 2D Bilinear Interpolation)
PSPNet, UNet, Standard U-Net, tight frame U-Net 등의 방법들이 있다.
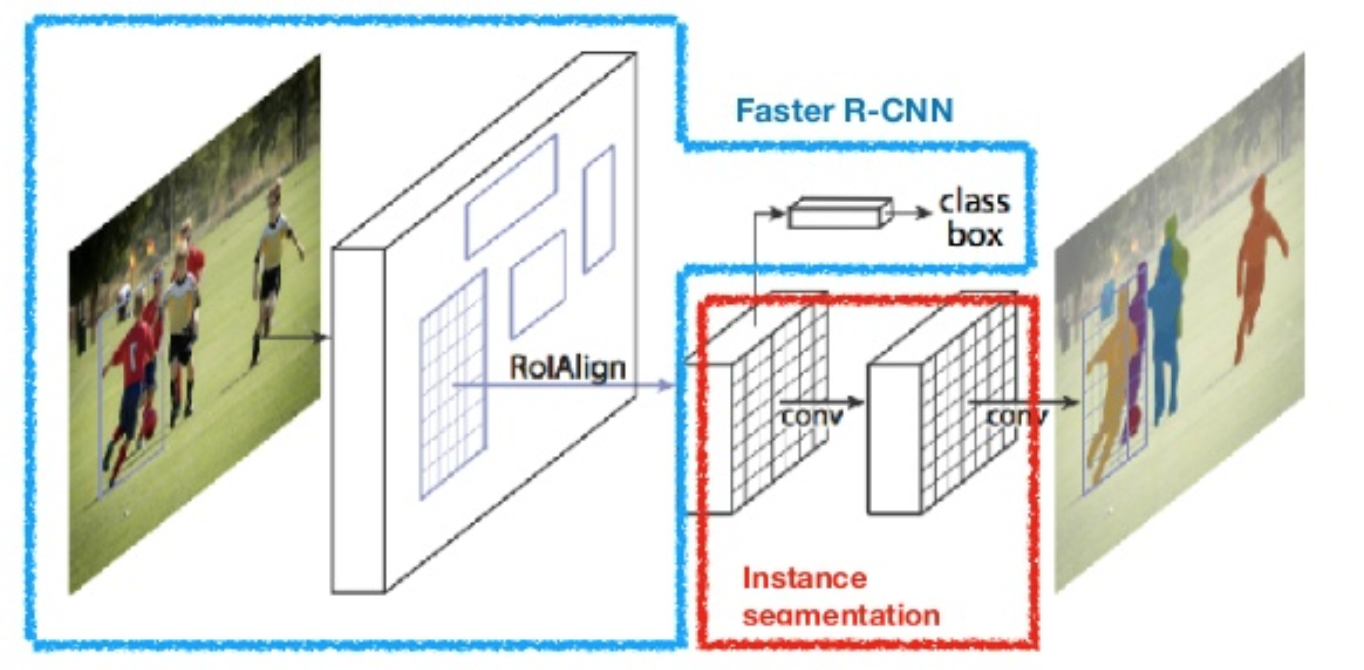
Mask-RCNN
Faster RCNN(Object Detection)과 FCN(Semantic Segmentation)을 합친것이 Mask-RCNN이다.
GAN(Generative Adversarial Network)
초기의 GAN은 Generator(생성자)와 Discriminator(판별자)가 서로 경쟁을 하며 발전하는 방식
GAN은 노이즈로부터 어떠한 새로운 내용을 만들어내는 함수와 같다
가우시안 노이즈가 인풋으로 주어지면 generative network를 통과해서 사람 얼굴을 만들어서 출력한다
PatchGAN, Pix2Pix, Conditional GAN, Stack GAN, Progressive GAN 등이 존재한다
