😃[2주차 - Day5]😃

통계적 추론, 표본 조사
표본 조사는 반드시 오차가 발생합니다.
표본조사를 할 때 표본과 모집단과의 관계를 이해해야 합니다.
표본 추출 방법은 단순랜덤추출법, 난수표 사용, 랜덤넘버 생성기 사용을 하는 방법이 있습니다.
[random.randint(1,10) for _ in range(10)]표본분포
표본조사를 통해 파악하고자 하는 정보는 모수입니다.
모수의 종류는 모평균, 모분산, 모비율 등이 있습니다.
모수를 추정하기 위해 표본을 선택하여서 표본평균이나 표본분산등을 계산합니다.
표본의 평균은 표본의 선택에 따라 달라지기 때문에, 표본평균은 확률변수입니다. 또한 표본평균이 가질 수 있는 값도 하나의 확률분포를 가집니다. 이 통계량의 확률분포를 표본분포라고 합니다.
표본평균은 모평균을 알아내는데 쓰이는 통계량입니다.
import numpy as np
import matplotlib as plt
xbars = [np.mean(np.random.normal(size=10)) for i in range(10000)]
print("mean %f, var %f" %(np.mean(xbars), np.var(xbars)))
h = plt.pyplot.hist(xbars, range=(5,15), bins=30)중심극한정리
모집단에서 추출된 표본의 측정값입니다.
대부분의 표본조사에서 추론할때 사용할 수 있습니다.
import numpy as np
import matplotlib as plt
n = 3
xbars = [np.mean(np.random.rand(n) * 10) for i in range(10000)]
print("mean %f, var %f" %(np.mean(xbars), np.var(xbars)))
h = plt.pyplot.hist(xbars, range=(0,10), bins=100)추정
모평균의 추정
점추정
import numpy as np
samples = [9,4,0,8,1,3,7,8,4,2]
np.mean(samples)구간추정
모평균 u의 100(1-a)% 신뢰구간입니다.
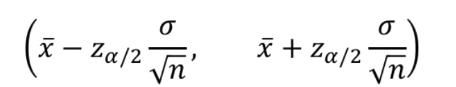
위 수식은 정규분포가 아니거나 표준편차가 알려져 있지 않은 경우, 사용할 수 없습니다.
표본의 크기가 클 때, 중심극한 정리를 사용하여 계산합니다. 이 경우, 시그마 대신 표본표준편차를 사용합니다.
import numpy as np
w = [10.7, 11.7, 9.8, 11.4, 10.8, 9.9, 10.1, 8.8, 12.2]
xbar = np.mean(w)
sd = np.std(w, ddof=1)
print("평균 : %.2f, 표준편차: %.2f" %(xbar, sd))
import scipy.stats
alpha = 0.5
zalpha = scipy.stats.norm.ppf(1-alpha/2)
print("zalpha: ", zalpha)모비율의 추정
점추정
확룔 변수 x가 n개의 표본에서 특정 속성을 갖는 표본의 개수를 말합니다.

표본을 뽑을 때마다, 조금씩 phat값이 달라질 겁니다.

구간추정
n이 충분히 클 때, 확률변수 X의 표준화입니다.
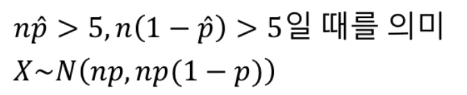
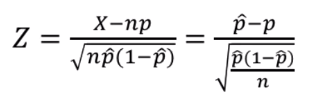
위와 같은 수식으로 추정을 할 수 있는데, 이는 근사적으로 표준정규분포 N(0,1)를 따릅니다.
이를 이용해서 신뢰구간을 만들어 낼 수 있습니다.
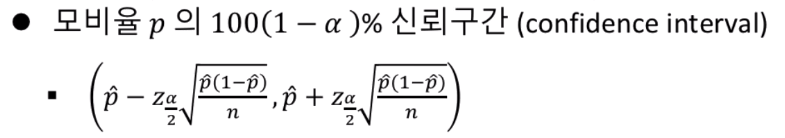
점추정 예시와 같은 문제입니다.

위 문제는 아래와 같이 풀 수 있습니다.
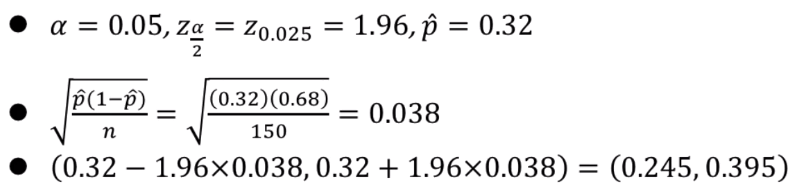
이를 코드로 옮겨보면,
import numpy as np
x = 48
n = 150
pha = x/n
alpha = 0.05
zalpha = scipy.stats.norm.ppf(1-alpha/2)
sd = np.sqrt(phat*(1-phat)/n)
print(phat, zalpha, sd)
ci = [phat - zalpha*sd, phat + zlapha*sd]
print(ci)검정
통계적 가설검정

이러한 주장을 검증하는 것이 가설 검정입니다.
귀무가설을 기각하기 위해서는 Xbar가 큰 값이 나와야합니다. 귀무가설이 참이라는 가정 하에서, 무언가를 계산했을 때 그 확률이 아주 낮은 값이 나온다면 귀무가설이 참이 아니라고 판단합니다.
이 기준을 잡기위해 유의수준 alpha를 도입합니다.
이것을 표준정규확률변수로 변환하는 것을 검정통계량이라고 합니다.

모평균의 검정
대립가설
문제에서 검정하고자 하는 것이 무엇인지 파악이 필요합니다. 대립가설 H1 채택을 위한 통계적 증거를 확보하는 것이 필요합니다. 증거가 없으면 귀무가설 H0를 채택합니다. 예시를 들어보면 다음과 같습니다.

랜덤하게 선택하다보면, 우연히 큰게 좀 많이 골라질 수도 있습니다. 이것이 귀무가설이 틀린 것인지, 우연에 의한 것인지 구분해야합니다.

이런 식으로 위와 같은 문제도 검정을 해볼 수 있습니다.
검정통계량

기각역
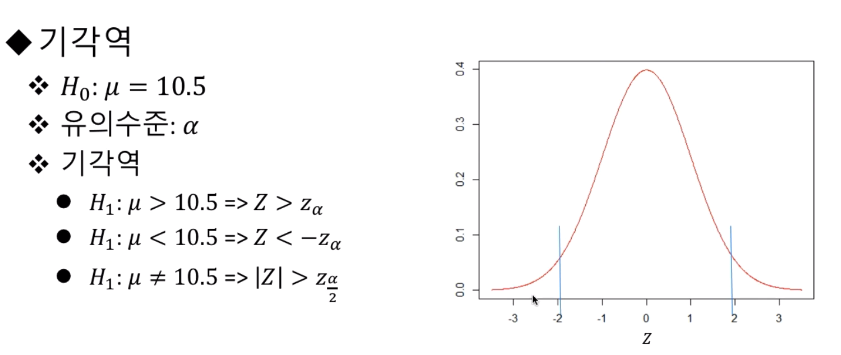
예시 검정


위와 같은 결과로, 이 농장의 홍보는 맞는 것으로 판단할 수 있습니다.
