
문제
[문제]
0으로 시작하지 않는 정수 N이 주어진다. 이때, M을 정수 N의 자릿수라고 했을 때, 다음과 같은 연산을 K번 수행한다.
1 ≤ i < j ≤ M인 i와 j를 고른다.
그 다음, i번 위치의 숫자와 j번 위치의 숫자를 바꾼다. 이때, 바꾼 수가 0으로 시작하면 안 된다.
위의 연산을 K번 했을 때, 나올 수 있는 수의 최댓값을 구하는 프로그램을 작성하시오.
[입력]
첫째 줄에 정수 N과 K가 주어진다.
N은 1,000,000보다 작거나 같은 자연수이고, K는 10보다 작거나 같은 자연수이다.
[출력]
첫째 줄에 문제에 주어진 연산을 K번 했을 때, 만들 수 있는 가장 큰 수를 출력한다.
만약 연산을 K번 할 수 없으면 -1을 출력한다.아이디어
정수 N의 자릿수들을 활용해 K번의 교환 연산으로 최대 정수를 만들어가는 과정이다.
-
N을 이루는 정수들을 리스트로 변환한다.
n = 132->n = [1, 3, 2]
-
N으로 만들 수 있는 최대 정수
max_n은 N을 내림차순 정렬한 결과값max_n = [3, 2, 1]
-
K번의 교환 연산으로 ⭐️
max_n에 가까워지게 만든다.
❌ 아이디어 1 (틀렸습니다)
k_result[i] = i번 교환 연산 했을 때 만들 수 있는 최대값을 저장한다.
◼️ k_result[i]의 값을 구하는 방법
-
k_result[i-1]==max_n인 경우-
만들 수 있는 최대값에 도달했으므로, 현재 값을 유지할 수 있다면 유지하는 것이 좋다.
-
연속되는 숫자가 있는 경우, 현재 값을 계속 유지하면 된다.
- 예를 들어,
330의 첫번째 수와 두번째 수를 교환한 결과는330이다. 연속되는 숫자가 있다면 교환 연산을 해도 이전 값을 그대로 유지할 수 있다.
- 예를 들어,
-
연속되는 숫자가 없다면, 가장 끝에 있는 두 수(가장 값이 작은 두 수)를 교환한다.
- 예를 들어,
4321의 마지막 두 수를 교환한 결과는4312이다. 교환 연산을 해야하는 상황에서 가장 큰 수를 만드는 최선의 방법이다.
- 예를 들어,
-
-
k_result[i-1]!=max_n인 경우- 가독성을 위해
prev = k_result[i-1]라고 하자. max_n과prev을 비교한다. 가장 처음으로 일치하지 않는 값이max_n[j]와prev[j]라고 할 때prev에서max_n[j]가 등장하는 인덱스를 찾는다. 같은 값이 여러개라면, 가장 끝에 있는 인덱스index를 찾는다.- 이후,
k_result[i]에prev의j번째 문자와index번째 문자를 교환 연산한 값을 저장한다.
- 가독성을 위해
-
k_result[i]에 저장되는 값의 첫번째 숫자가 0인 경우 -1을 리턴하도록 한다.
◼️ 아이디어 1 풀이법 예시
-
N = 436659, K = 2


-
N = 404, K = 3

◼️ 아이디어 1 반례
위 두 예시만 보면, 문제가 없는 풀이방법처럼 보이지만 반례가 존재한다.
-
N = 381993, K = 3
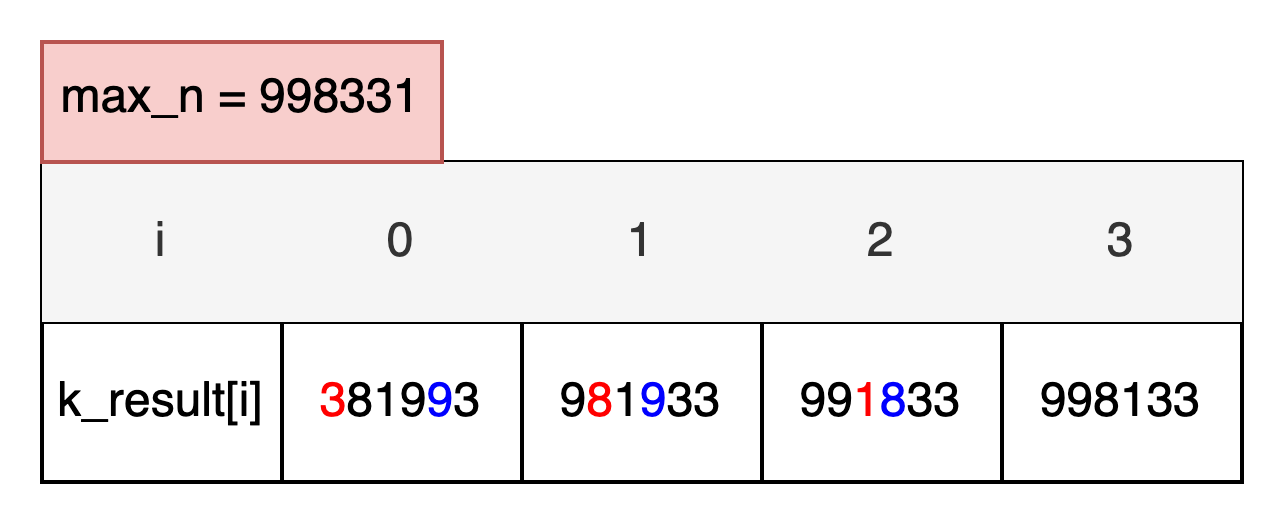
지금까지 설명한 풀이방법으로 풀어내면, 3번의 교환 연산 후 얻을 수 있는 최대값은 998133이라는 결과가 나온다.
하지만, 실제로 3번의 교환 연산 후 얻을 수 있는 최대값은 998313이 나와야 한다.
-
prev[j]!=max_n[j]인 경우prev에서max_n[j]가 등장하는 인덱스를 찾을 때, 같은 값이 여러개라면 가장 끝에 있는 인덱스index를 찾아 두 수를 교환연산해주는 것이 최종적으로 최대값을 만들 수 있는 방법이라고 생각했다.
그러나, 실제로는 그렇지 않았다. -
가장 끝에 있는
index를 찾아 교환연산 하는 것이 현재는 최대값을 만들 수 있는 방법일지 몰라도 K번째까지 연산을 수행했을 때 그 결과가 최대인지는 모른다는 얘기이다. -
prev에서max_n[j]가 여러번 등장한다면, 각각의 경우에 교환연산을 수행해주고 결과를 비교해야 한다. -> 아이디어 2로 발전
⭕️ 아이디어 2
k_result[i] = i번 교환 연산을 했을 때, max_n과 가까워지게 만들 수 있는 값을 저장한다.
- 여기서 가까워진다는 의미는
max_n의j번째 자리수와k_result[i]의j번째 자리수를 같게 만든다는 의미이다. - 이는 꼭 i번째 교환 연산이 만들어 내는 최대값(아이디어 1)이 아닐 수도 있다.
k_result[i]를 구하는 방법에서 아이디어 1과 과 큰 차이가 나게 달라지는 부분은
max_n과prev비교 시 가장 처음으로 일치하지 않는 값이max_n[j]와prev[j]라고 할 때- 아이디어 1에서는
prev에서max_n[j]가 등장하는 가장 끝에 있는 인덱스를 찾아 교환 연산을 해주었으나, - 아이디어 2에서는
prev에서max_n[j]가 등장하는 모든 인덱스들에 대해 분기하여 교환 연산을 수행해준다는 부분이다.
◼️ k_result[i]의 값을 구하는 방법
(아이디어 1과 달라진 부분은 🔔 아이콘으로 표시)
-
k_result[i-1]==max_n인 경우- 만들 수 있는 최대값에 도달했으므로, 현재 값을 유지할 수 있다면 유지하는 것이 좋다.
- 연속되는 숫자가 있는 경우, 현재 값을 계속 유지하면 된다.
- 연속되는 숫자가 없다면, 가장 끝에 있는 두 수(가장 값이 작은 두 수)를 교환한다.
-
k_result[i-1]!=max_n인 경우- 가독성을 위해
prev = k_result[i-1]라고 하자. max_n과prev을 비교한다. 가장 처음으로 일치하지 않는 값이max_n[j]와prev[j]라고 할 때prev에서max_n[j]가 등장하는 인덱스를 찾는다. 같은 값이 여러개라면, 각각의 인덱스(index)에 대해 분기한다. 🔔- 각각의
index에 대해 분기하여k_result[i]에prev의j번째 문자와index번째 문자를 교환 연산한 값을 저장한다. 🔔
- 가독성을 위해
-
k_result[i]에 저장되는 값의 첫번째 숫자가 0인 경우 -1을 리턴하도록 한다.
◼️ 아이디어 2 풀이법 예시
- N = 381993, K = 3
🟦 분기점 1
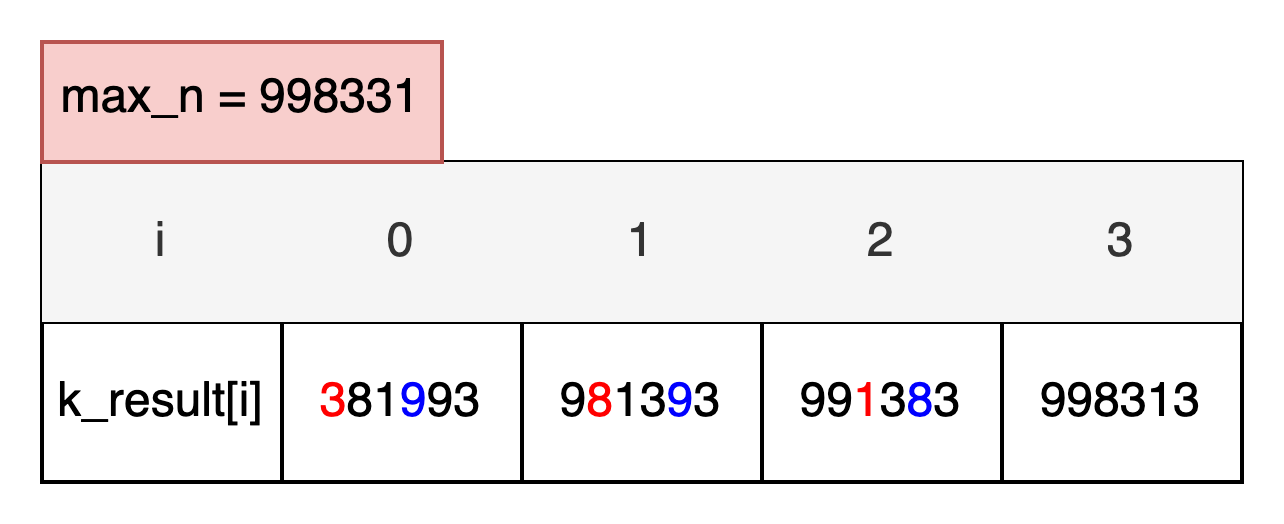 k_result[1]의 값을 저장할 때, 0번째 인덱스와 ↔️ 3번째 인덱스에 위치해있는 9와 교환 연산을 수행했다.
k_result[1]의 값을 저장할 때, 0번째 인덱스와 ↔️ 3번째 인덱스에 위치해있는 9와 교환 연산을 수행했다.
🟦 분기점 2
k_result[1]의 값을 저장할 때, 0번째 인덱스와 ↔️ 4번째 인덱스에 위치해있는 9와 교환 연산을 수행했다.
🟦 결과
각 분기점의 k_result[k]의 결과를 비교하여 가장 큰 값인 998313이 정답이 된다.
제출 코드
import sys
input = sys.stdin.readline
def solve(n, m, k):
# 한자리수이면 연산을 수행할 수 없다.
if m == 1:
return -1
# n으로 만들 수 있는 최대 정수
max_n = sorted(n, reverse=True)
# 최대 정수에서, 숫자가 연속되는 부분이 있다면
# k번째 연산에 도달하기 전 max_n을 만들 수 있는 경우 그 다음 연산들은 모두 max_n의 결과를 낼 수 있다.
has_continuous_number = False
for i in range(m-1):
if max_n[i] == max_n[i+1]:
has_continuous_number = True
break
# k_result[i] = 연산을 i번 했을 때 만들어지는 최대 정수(리스트로 저장)
k_result = [[] for _ in range(k+1)]
k_result[0] = n
return dfs(k_result, 1, max_n, has_continuous_number)
def get_index_list(target_list, target_num):
ret = []
for i in range(len(target_list)):
if target_list[i] == target_num:
ret.append(i)
return ret
def dfs(k_result, i, max_n, has_continuous_number):
prev = k_result[i-1] # 이전 연산에서 만들어진 최대 정수
ret = 0
# 0이 앞자리에 오는지 확인한다.
if prev[0] == 0:
return -1
if i == k+1:
return int(''.join(list(map(str, k_result[k]))))
if prev == max_n:
if has_continuous_number:
k_result[i] = prev
else:
# 끝의 두 수를 swap
new_n = prev[:]
new_n[m-1], new_n[m-2] = new_n[m-2], new_n[m-1]
k_result[i] = new_n
return dfs(k_result, i+1, max_n, has_continuous_number)
# max_n에 가깝게 만들어가는 과정
swapped = False
for j in range(m):
if swapped:
break
if max_n[j] != prev[j]:
# max_n[j]가 prev에서 몇번째 인덱스에 위치하는지 찾는다.
index_list = get_index_list(prev, max_n[j])
# 분기처리
for index in index_list:
# prev의 j와 index를 swap한다.
new_n = prev[:]
new_n[j], new_n[index] = new_n[index], new_n[j]
k_result[i] = new_n
ret = max(ret, dfs(k_result, i+1, max_n, has_continuous_number))
swapped = True
return ret
# main
n, k = input().split()
# k = 연산 횟수
k = int(k)
# n = 입력받은 정수를 리스트로 변환
n = list(map(int, n))
# m = 자릿수
m = len(n)
print(solve(n, m, k))➕ 또다른 풀이법 (BFS)
다른 사람들은 어떻게 풀었을까 검색하던 중, BFS 풀이법을 발견해서 이 또한 정리해둔다.
visited에 (만들어지는 값, 교환 연산 횟수)를 저장하여 같은 값을 같은 연산 횟수로 만드는 케이스를 배제한다.
나는 만들 수 있는 최대 정수인 max_n과 비교해가면서 교환 연산을 진행했는데, 이 풀이법은 현재 정수에 대해 이중 for문을 돌며 visited 배열에 저장되지 않은 교환 연산이 이루어질 경우 이를 수행한다.
훨씬 깔끔하게 코드가 작성된다는 점이 좋았다.
이 풀이법도 결국 최종적으로 k번의 연산을 수행했을 때 최대값이 무엇인지 알기 위해서는 k번 이전 연산의 모든 경우를 확인해야 한다는 아이디어를 담고 있다.
단, 이때 중복되는 경우에 대한 연산을 줄이기 위해 visited를 활용하고 있다.
import sys
input = sys.stdin.readline
from collections import deque
def solve_bfs(n, m, k):
# visited에 (만들어진 수, 교환연산 횟수)를 저장한다.
visited = set()
visited.add((n, 0))
q = deque([(n, 0)])
answer = 0
while q:
n, cnt = q.popleft()
if cnt == k:
answer = max(answer, n)
continue
n_list = list(str(n))
for i in range(m-1):
for j in range(i+1, m):
if i == 0 and n_list[j] == '0':
continue
# 교환 연산으로 new_n을 만들어주는 과정
n_list[i], n_list[j] = n_list[j], n_list[i]
new_n = int(''.join(n_list))
if (new_n, cnt + 1) not in visited:
q.append((new_n, cnt + 1))
visited.add((new_n, cnt + 1))
# 교환 연산 원복
n_list[i], n_list[j] = n_list[j], n_list[i]
return answer if answer else -1
# main
n, k = input().split()
m = len(n)
n = int(n)
k = int(k)
print(solve_bfs(n, m, k))참고 사이트
