[논문리뷰] (Graphormer) Do Transformers Really Perform Bad for Graph Representation? (2021)
Application of GNN
최근 컴퓨터비전, 자연어처리 그리고 오디오 도메인에서까지 공통적으로 사용되는 인공신경망 구조가 있습니다. 2017년, Attention is all you need 라는 논문에서 발표한 트랜스포머 (transformer) 라는 구조입니다. 트랜스포머는 sequential data를 입력으로 받기 때문에, 자연어 및 오디오 데이터에 적용 가능하고, 이미지 또한 이미지 패치 (patch)들의 순차열로 표현하게 되면 트랜스포머를 적용할 수 있습니다.
최근에는 그래프 데이터에 트랜스포머 구조를 적용하는 방법론에 대한 연구가 활발히 이루어지고 있습니다. 사실 트랜스포머는 일반화된 그래프 인공신경망이라고 할 수 있습니다. 트랜스포머의 multihead attention layer가 하는 역할은, 입력으로 받은 순차열을 구성하는 원소들 간의 연관 정도 (attention weight)를 계산하여 특정 원소의 hidden state를 업데이트 하는 것입니다. 마찬가지로, aggregation-update 메커니즘의 그래프 인공신경망도 연결된 노드들 간의 관계를 바탕으로 특정 노드의 hidden state를 업데이트 합니다.
한 가지 다른 점이 있다면, 트랜스포머는 순차열의 모든 원소들 간의 연결을 가정한다는 것이고 (순차열의 원소가 개라면, 개의 연결 관계를 가정), 그래프 인공신경망은 그래프 상에서 연결된 노드들 끼리의 연결만을 가정한다는 것입니다.
오늘 소개할 논문은 Graphormer라는 graph transformer 모델을 제안한 논문으로, 처음으로 트랜스포머 구조가 그래프 형태의 데이터를 "매우 잘" 처리할 수 있음을 보여 주었습니다.
1. Introduction
기존의 트랜스포머가 그래프 형태의 데이터를 잘 처리하지 못하는 이유는 크게 두 가지가 있습니다.
-
트랜스포머는 그래프의 structural information을 반영하지 못합니다. 그래프는 순차열 데이터와는 달리, 그래프 안에 연결 관계(edge)가 존재합니다. 단순히 노드의 feature들을 순차열로 만들어 트랜스포머에 넣어 주게 되면, 트랜스포머는 이러한 연결 관계를 포착할 수 없겠죠.
-
트랜스포머를 구성하는 self-attention은 노드 feature의 의미적 유사도 (semantic similarity)를 바탕으로 attention weight를 산출하게 되는데, 이 때 각 노드의 중요도는 반영되지 않습니다. 이 또한, 트랜스포머가 그래프의 위상 구조를 포착할 수 없다는 점과 연결됩니다.
따라서, 본 논문에서는 그래프의 structural information을 트랜스포머에 주입하는 방법론 (Graphormer)을 제안합니다.
2. Methodology
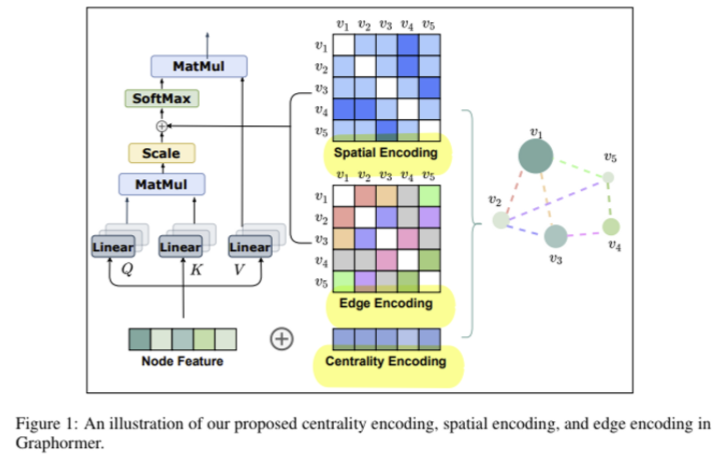
트랜스포머에 그래프의 structural information을 주입할 수 있는 세 가지 요소를 소개합니다.
2.1. Centrality Encoding
node centrality란, 노드의 중요도를 의미합니다. 노드의 중요도를 측정하는 방법은 다양한데, 일반적으로 node degree (특정 노드와 연결된 다른 노드들의 개수)를 사용합니다. 즉 특정 노드 의 node centrality는 정숫값으로 주어집니다. 노드 의 feature를 라고 할 때, 트랜스포머의 입력은 아래와 같이 주어집니다.
여기서 는, 노드의 in degree (정숫값)에 상응하는 학습 가능한 임베딩이고, 마찬가지로 는, 노드의 out degree에 상응하는 학습 가능한 임베딩입니다.
일반적인 트랜스포머 구조에서 input embedding에 Positional embedding을 더해주는 것과 매우 유사합니다.
2.2. Spatial Encoding
입력에 centrality encoding을 더해 줌으로써, 트랜스포머 모델이 "어떤 노드가 중요한지"에 대한 정보를 포착할 수 있도록 했습니다. 하지만, 노드의 중요도 말고도 그래프의 위상 구조는 더 많은 정보를 가지고 있습니다. 따라서, 노드들 간의 spatial relation을 인코딩하여, node feature를 기반으로 산출된 attention map을 조금 수정해주어야 합니다.
일반적인 트랜스포머에서, 특정 원소 와 간의 attention weight 는 아래와 같이 정의됩니다.
위와 같이 구해진 attention weight는 node의 semantic relation을 반영할 뿐, spatial relation을 반영하지 못합니다. 따라서 Graphormer는 이 를 아래와 같이 수정합니다.
여기서 는, 두 노드 간의 shortest-path distance를 의미하고, 따라서 는 항상 정숫값을 산출합니다. 는 에 대한 함수 ()로, 학습 가능한 파라미터로 구성되어 있습니다.
2.3. Edge Encoding
마지막으로, SPD를 기반으로 구한 spatial information 외에, 두 노드 를 연결하는 edge에 대한 정보도 attention weight에 반영합니다. 즉, 노드 간의 attention weight는 아래와 같이 표현할 수 있습니다.
여기서 는 노드 를 연결하는 edge를 실숫값으로 인코딩한 것으로, 아래와 같이 표현할 수 있습니다.
식을 조금 더 자세히 설명하자면, 노드 를 잇는 shortest path가 이라고 하겠습니다. 이 때, 은 엣지 의 feature vector를 의미합니다. 그리고 는 학습 가능한 파라미터입니다. 즉, 위 함수는 shortest path 상에 있는 edge feature들을 실수로 사상해 주는 역할 (는 실수이어야 하므로)을 하는 것입니다.
3. Experiments
3.1. OGB Large-Scale Challenge
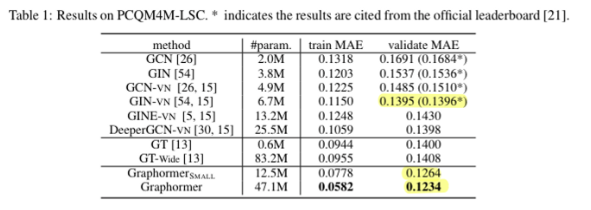
- 기존의 SOTA인 GIN-vn을 앞지름
- 모델 층을 늘려도 성능이 지속적으로 향상 → oversmoothing issue가 어느정도 해결됨
- graph-level task 트랙에서 우승
3.2. Graph Representation (OGB, ZINC)
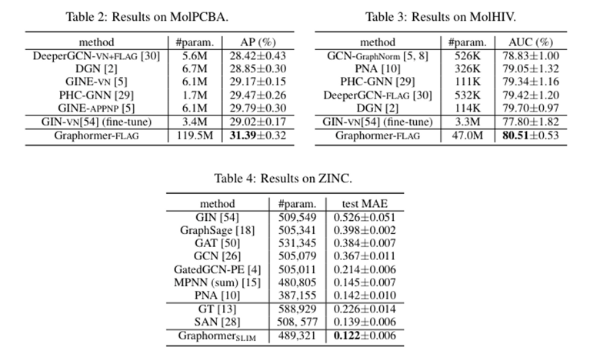
- small dataset들이므로 overfitting이 발생 → 더 작은 model variant를 사용
