[논문 리뷰] QA-GNN: Reasoning with Language Models and Knowledge Graphs for Question Answering(2021)
Application of GNN
1. Introduction
기존의 Question Answering(QA)에서는 거대한 규모로 학습된 언어모델을 fine-tuning하는 방식으로 학습이 이루어지기도 했으나, 이러한 방식은 몇 가지 한계점을 가집니다.
- answer prediction에 대한 설명력(explainability)가 부족
- structured reasoning에 취약(ex. 부정에 대한 질문에서 오류가 많음)
따라서, 본 논문에서는 언어모델(LM)과 지식그래프(KG)라는 knowledge base를 동시에 사용하여 QA를 수행할 때의 challenge와 방법론에 대해 소개합니다.
Challenges
QA task란, 질문과 정답 선택지들(QA context)가 주어졌을 때, 정답을 고르는 task입니다. LM과 KG를 결합한 QA reasoning을 수행하기 위해 필요한 스텝은 크게 두 가지가 있습니다.
- QA context가 주어졌을 때, 추론에 필요한 entity들을 추출하여 KG로부터 의미 있는 정보를 포함한 subgraph를 retrieve하는 스텝.
하지만, 기존의 방식으로 subgraph를 retrieve하면, 그 안에 QA context와 연관이 없는 entity가 존재한다는 문제점이 있습니다.
- 추출된 KG와 QA context 상에서 Joint reasoning을 통해, 정답을 추론하는 스텝.
기존의 시도에서도 KG와 LM을 동시에 사용하여 QA를 수행하는 연구들이 있었으나(Lin et al., 2019; Wang et al., 2019a; Feng et al., 2020; Lv et al., 2020), 공통적으로 QA context와 KG를 분리된 modality로 다루었다고 합니다.
2. Methodology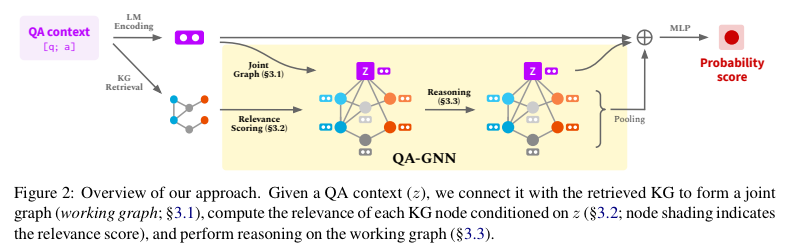
QA context와 KG가 주어졌을 때, QA-GNN의 inference과정을 순서대로 설명하자면 아래와 같이 요약할 수 있습니다.
- QA context를 LM을 통해 인코딩 후, QA context를 기반으로 KG로부터 필요한 정보들을 retrieve
- 1을 통해 완성된 KG의 각 노드에 QA context node를 연결시킴으로써working graph 를 형성
- Relevance scoring을 통해, working graph에서 추론에 불필요한 entity node를 filtering
- Attention based message passing을 통해 정답을 추론
세 가지 스텝을 기준으로 설명을 해 보겠습니다.
1. Retrieve subgraph from KG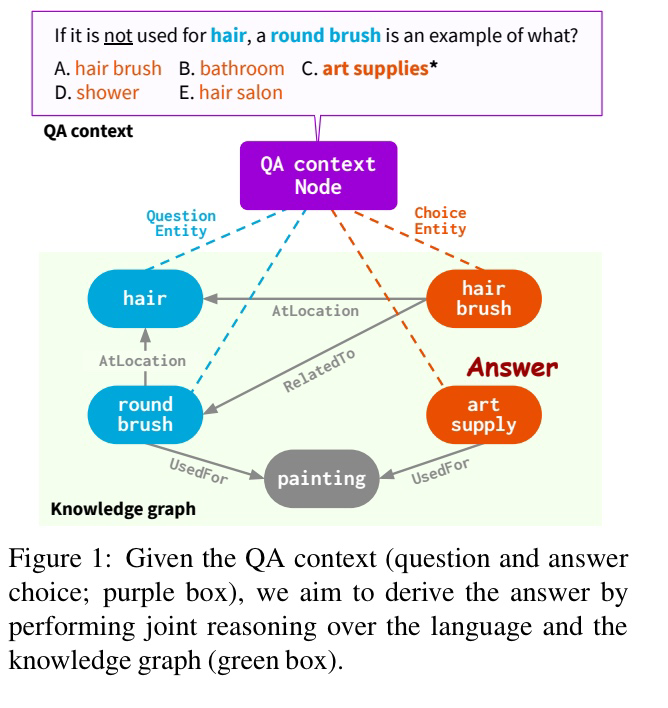
위 Figure와 같이, 질문과 정답 선택지들이 주어졌을 때 문맥 안에 존재하는 entity들을 통해 (Feng et al., 2020)에서 제안한 방식을 사용하여 KG로부터 subgraph를 추출합니다.
지금부터 KG는 라고 표기 하겠습니다. 여기서 retrieve된 question entity node를 , answer entity node를 라고 하겠습니다. 라 할 때, retrieve된 subgraph는 라고 표현할 수 있습니다.
여기서 는 의 모든 k-hop neighborhood node를 포함합니다.
또한, QA context 를 LM에 통과시켜 으로 인코딩합니다.
2. Joint Graph Representation
QA context node 를 의 모든 노드에 연결함으로써 working graph 를 만듭니다.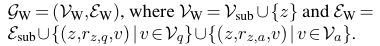 여기서 노드 의 initial representation은 (QA context를 LM으로 인코딩한 representation)로 정의됩니다.(는 LM).
여기서 노드 의 initial representation은 (QA context를 LM으로 인코딩한 representation)로 정의됩니다.(는 LM).
3. Relevance Scoring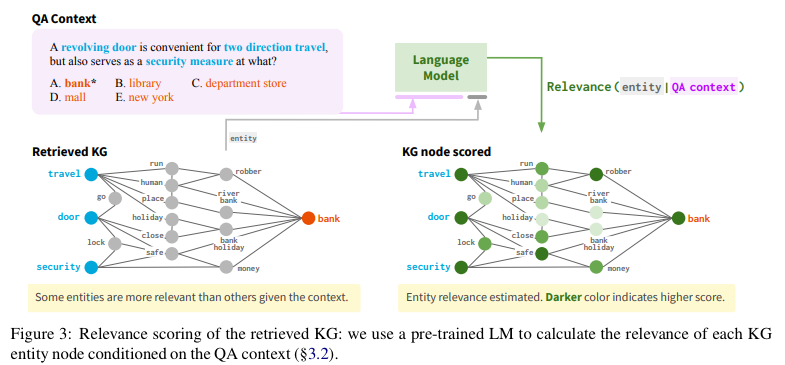
위 figure를 보면, 전부가 정답을 추론하는 데 필요하진 않다는 것을 알 수 있습니다. 이러한 irrelevant node는 오버피팅을 유발할 수도 있고, 의 크기가 너무 커지면 계산 효율의 문제도 생깁니다. ConceptNet KG를 기준으로 했을 때, 3-hop neighbor를 retrieve하게 되면 평균적으로 subgraph의 노드 수가 400개 정도라고 합니다.
따라서, 각 노드들의 QA context에 대한 relevance score를 계산합니다. 그리고 이를 바탕으로 상에서 message passing을 하거나, 혹은 아예 pruning을 한다고 합니다.
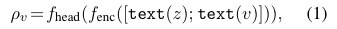 위 수식을 통해, 각 노드에 대한 relevance score가 계산되고 여기서 는 QA node, 는 학습 가능한 MLP입니다.
위 수식을 통해, 각 노드에 대한 relevance score가 계산되고 여기서 는 QA node, 는 학습 가능한 MLP입니다.
4. Message passing on working graph based on Relevance score
마지막 스텝은, 계산된 relevance score를 사용하여 working graph 상에서 joint reasoning을 하는 것입니다.
Graph attention network(GAT)가 사용되며, node representation update를 위한 수식은 아래와 같습니다.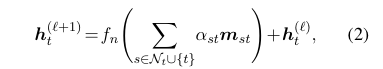
- : update function
- : aggregated message from node s to node t
- : attention weight from node s to node t(노드 s의 relevance score에 의해 결정됨)
일반적인 GAT와 다른 점이 있다면, attention weight가 relevance score의 영향을 받는다는 점입니다. QA context와 관련이 없는(relevance score가 낮은) entity 노드에 대해서는 attention weight를 낮게 설정하여 주변 노드의 message를 aggregate한다고 이해할 수 있습니다.
4.1. Message
KG는 기본적으로 multi-relational graph입니다. 이러한 multi-relational graph상에서 어떻게 를 생성할 수 있는지 설명해 보겠습니다.
는 노드 s에서 노드 t로 가는 message입니다. 따라서, 는 이웃 노드 s와 노드s 노드 t로 가는 엣지에 의해 결정됩니다.
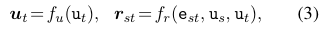
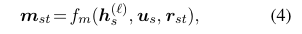
- : node t의 type에 대한 one-hot vector
- : edge s t의 type에 대한 one-hot vector
- : node t에 대한 임베딩
- : edge s t에 대한 임베딩
4.2. Score-aware attention
들을 aggregate하기 위해서 attention weight 가 필요합니다. 이 때, 는 relevance score에 조건화된 형태로 산출됩니다.

- 는 node 의 relevance score입니다.
- 는 실수인 relevance score를 embedding으로 바꾸어주는 MLP입니다.
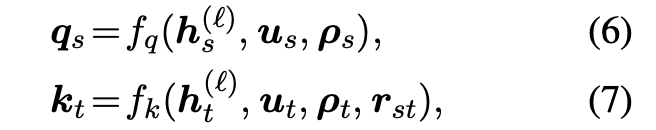
- 는 (노드 s의 임베딩, 노드 s의 relevance score 임베딩)를 인풋으로 받아서 query vector 를 산출하는 MLP입니다.
- 는 (노드 s의 임베딩, 노드 s의 relevance score 임베딩, 노드 s 노드 t로의 엣지 임베딩)를 인풋으로 받아서 key vector 를 산출하는 MLP입니다.
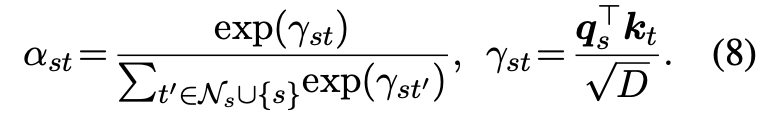
이렇게 산출된 간의 dot product를 통해 attention weight가 산출됩니다. 즉, 기존에 산출했던 QA context relevance score에 대해 dependent한 attention weight를 얻은 것입니다.

잘보고갑니다 ^^