
고령자를 위한 헬스 케어 플랫폼 프로젝트를 진행할 때 객체 탐지로 사용했던 Yolov5 모델에 대해서 어떻게 사용했는 지 기록하기 위해 이 글을 작성한다.
어떤 음식을 추천하고, 어떤 음식을 피해야 하는지 O 와 X로 표시하는 것에 대해서 작성하였다.
📔 YOLOv5?
Object Detection을 위한 모델 이다.
코드는 깃허브에 공개되어있어서 사용할 수 있었다.
PyTorch 기반의 모델이며, 모델의 크기에 따라 모델이 나뉘어져있다.
📕 How to use?
직접 어떻게 사용했는지는 다음과 같은 순서로 진행했다.
🌈 데이터 준비
나는 AI HUB와 크롤링을 통해 이미지를 준비하였으며 MAKE SENSE에서 라벨링과 Bounding box 작업을 진행하였다.

직접 라벨링을 마치고 나면 라벨을 포맷해서 받을 수 있는데 MakeSense 좌측 상단에 Actions - Export Annotations 를 통해 라벨을 받을 수 있다.
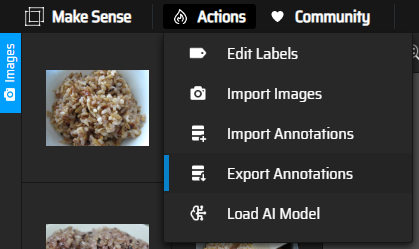
내가 사용하고자 했던 모델은 YOLO모델이었기에 YOLO형태의 라벨로 받아주었다.
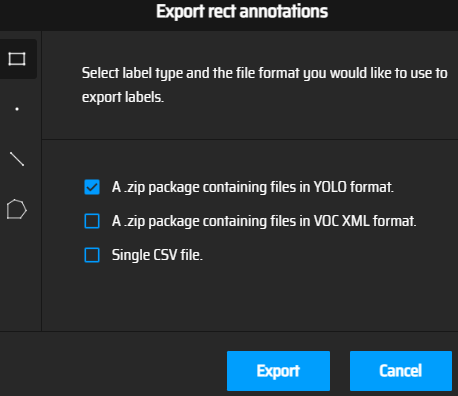
받은 파일의 알집을 풀고 안을 들여다보면 이런 형태이다.
이미지 파일과 같은 이름으로 txt파일이 생성되어 있고 들어가면 라벨의 Class num와 좌표값 4개로 총 5개의 숫자로 이루어져 있다.
사진은 Class num이 0이고 4개의 좌표 값으로 이루어진 라벨이다.

나는 사진마다 작업을 해서 모두 라벨이 0으로 나오고 폴더로 분류했었다.
그래서 이 사진들을 구분 할 수 있게 라벨을 수정하였다.
라벨 수정은 Python 라이브러리인 glob을 사용하여 바꾸었다.
아래 사진은 라벨을 바꾸기 위해 사용했던 코드 일부이다.
import glob
import os
def translabel(foldername, after_label):
# 폴더 안에 있는 txt 파일 리스트
filelist = glob.glob('{}\\*.txt'.format(foldername))
# 변환시킨 후 넣을 폴더 생성
if not os.path.isdir('trans_'+foldername):
os.mkdir('trans_'+foldername)
# 변환
for filename in filelist:
with open(filename, 'r') as f:
txtlines = ''
lines = f.readlines()
for line in lines:
# 첫번째 공백 찾기 (기존 라벨 찾아내기1)
first_blank = line.find(' ')
# 공백앞의 문자
pre_num = line[0:first_blank]
# 공백앞의 문자 제거
rm_pre_num = line.lstrip(pre_num)
# 바꿀 문장
after_line = str(after_label) + rm_pre_num
txtlines += after_line
# 바뀐것 생성
with open('trans_' + filename, 'w') as f2:
f2.write(txtlines)음식별로 라벨 숫자를 구분시켜두었기에 해당하는 숫자로 바꾸어서 사용하였다.
그리고 라벨에 대한 정보를 yaml파일로 만들어 두었다.
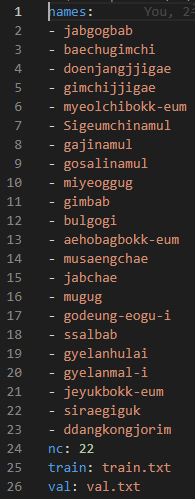
names : 0~21번 까지의 한식 이름
nc : 이름 개수 (여기서는 22개)
train : train시킬 라벨들을 가지고 있는 목록txt파일
val : test시킬 라벨들을 가지고 있는 목록txt파일
train과 val은 아래의 데이터 학습 코드들을 사용하면 알아서 수정이 되고 갱신이 되므로 만들지 않아도 상관이 없었다.
이 파일의 이름은 data.yaml로 만들어 IMG/dataset 폴더 안에 넣어두었다.
⭐ 데이터 학습
데이터 학습은 구글 코랩을 통해 학습시켰다.
import os
from glob import glob
import yaml
import shutil
from IPython.display import Image
import yaml
from google.colab import drive
drive.mount('/content/mount')
%cd /content/mount/MyDrive/IMG
img_list = glob('data/train/*.jpg') # 학습시킬 이미지가 있는 파일 경로
from sklearn.model_selection import train_test_split
# train test split
train_img_list, val_img_list = train_test_split(img_list, test_size=0.2, random_state=129) # 8:2
# train test split하고 난 파일들의 경로를 저장하고 있는 txt 파일
with open('/content/mount/MyDrive/IMG/train.txt', 'w') as f :
f.write('\n'.join(train_img_list) + '\n')
with open('/content/mount/MyDrive/IMG/val.txt', 'w') as f:
f.write('\n'.join(val_img_list) + '\n')
with open('/content/mount/MyDrive/IMG/dataset/data.yaml', 'r') as f:
data = yaml.load(f)
print(data)
data['train'] = '/content/mount/MyDrive/IMG/train.txt' # yolov5 경로
data['val'] = '/content/mount/MyDrive/IMG/val.txt' # yolov5 경로
with open('/content/mount/MyDrive/IMG/dataset/data.yaml', 'w') as f:
yaml.dump(data, f)
print(data)ipynb파일로 사용했기 때문에 원하는 부분에 어떻게 되어있는지 구조를 나누어서 보았다.
# Train
%cd /content/mount/MyDrive/yolov5
!python train.py --img 416 --batch 16 --epochs 200 --data /content/mount/MyDrive/IMG/dataset/data.yaml --cfg /content/mount/MyDrive/yolov5/models/yolov5m.yaml --weights yolov5s.pt --name food_yolov5s_results이렇게 Train을 하고 나면 모델이 다음과 같은 코드와 함께 저장된다.
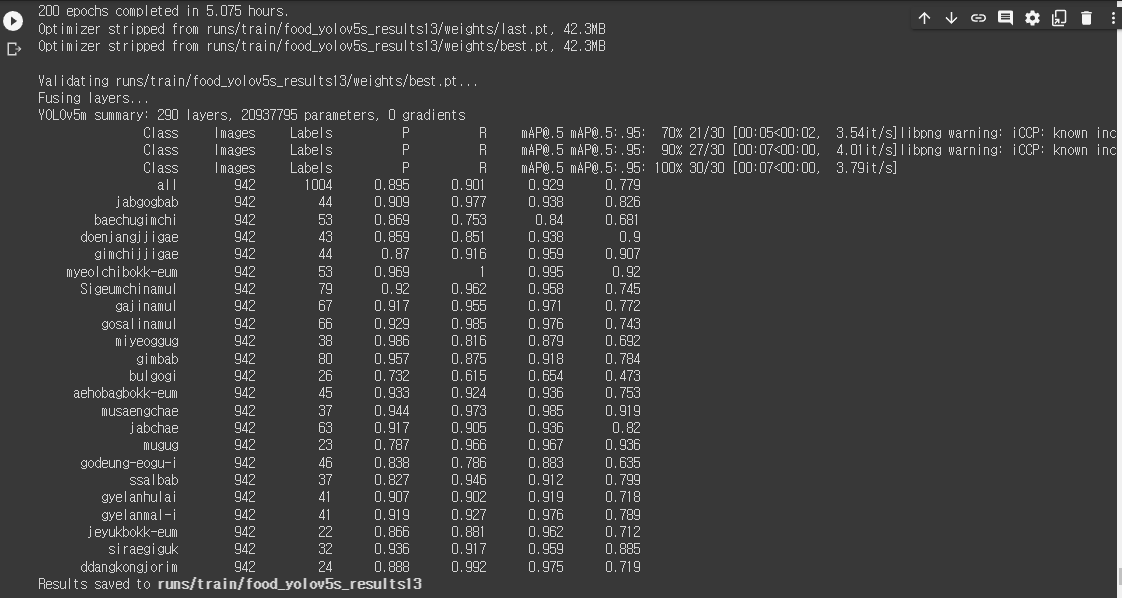
YOLOv5 디렉토리 안 runs/train/food_yolov5s_results13으로 저장된 것을 볼 수 있다.
학습이 되었는지 보기 위해 Tensorboard를 통해 확인했다.
아래도 Train직후 같이 출력되게끔 ipynb파일에 같이 실행했다.
%load_ext tensorboard
%tensorboard --logdir /content/mount/MyDrive/yolov5/runs/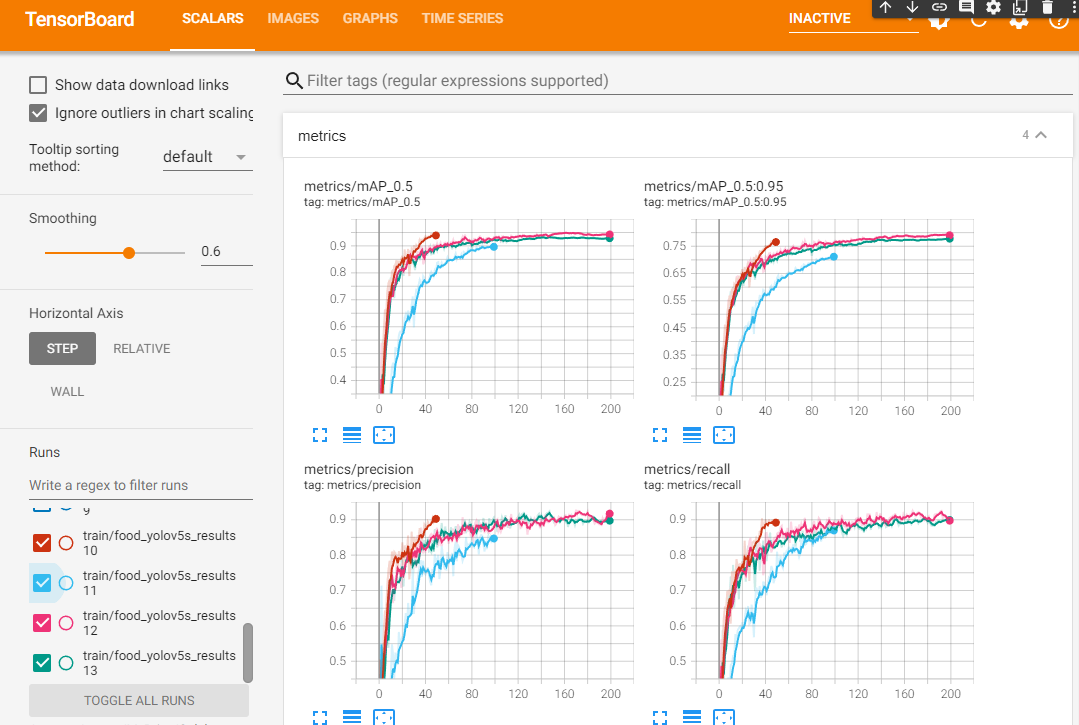
학습을 여러번 시켰는데 몇개만 출력 되게 눌러 보았다.
각 선들이 epoch에 따라 재현율과 응답률 그리고 mAP가 점점 상승하는 것을 볼 수 있다.
대부분 YOLOv5s를 사용해 학습시켰는데 위 사진에서 유독 느리게 학습되는 하늘색 선은 YOLOv5m모델이다.
epoch 100으로 학습 시켰다가 몇번 돌려보지못할 것 같아 그냥 s로 사용했다.
🌟 DETECT
학습된 모델이 생성 되었으므로 직접 탐지를 해보았다.
# Detect
from IPython.display import Image
!python /content/mount/MyDrive/yolov5/detect.py --weights /content/mount/MyDrive/yolov5/runs/train/food_yolov5s_results13/weights/best.pt --img 416 --conf 0.5 --source /content/mount/MyDrive/밥상3.jpg
성공적으로 탐지가 된 것을 알 수 있다.
하지만 우리 프로젝트에서는 단순히 탐지만 할 것이 아니었기 때문에 Detect.py 파일을 수정을 했다.
🎵 Detect.py 튜닝
깃허브에서 가져온 yolov5의 detect.py을 직접 열어보았다.
여기에 작성하기에는 코드가 길다고 생각되어 어떤걸 바꾸려고 했는지, 어떻게 바꿨는지에 대해 작성해본다.
🧿 What
🎨 1. 한글화
yaml파일이 영어로 되어있었기 때문에 한글로 바꿔줄 필요가 있었다.
🎨 2. 사용자에게 필요없는 정확도 수치
탐지한 객체 명 옆에 소수점 숫자의 정확도가 함께 출력되었는데 우리 프로젝트 사용자 입장에서는 굳이? 라는 생각이 들어 제거할 예정이다.
🎨 3. 식단 추천이기에 탐지된 색깔, 모양
우리 프로젝트에서는 질병에 따른 식단 추천이었기에 각각 다른 색이 아닌,
피해야할 음식 : 빨강 / 그렇지 않은 음식 : 초록
으로 바꿀 예정이었다.
더불어 박스 모양도 O, X로 바꿀 계획이다.
🧿 How
🎨 1. 한글화, 정확도 수치
detect.py 내에 이런 코드를 찾을 수 있었다.
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')Write results라고 되어 있는 부분 내에 있었는데, label이 가지고 있는 값이 실제 출력되는 수치까지 포함된 라벨이었다.
우리는 딕셔너리를 통해 영어 이름을 한글로 바꾸고 정확도 부분을 제거했다.
machine129_dic = {'jabgogbab':'잡곡밥', 'baechugimchi':'배추김치', 'doenjangjjigae':'된장찌개',
'gimchijjigae':'김치찌개', 'myeolchibokk-eum':'멸치볶음', 'Sigeumchinamul':'시금치나물',
'gajinamul':'가지나물', 'gosalinamul':'고사리나물', 'miyeoggug':'미역국',
'gimbab':'김밥', 'bulgogi':'불고기', 'aehobagbokk-eum':'애호박볶음',
'musaengchae':'무생채', 'jabchae':'잡채', 'mugug':'무국',
'godeung-eogu-i':'고등어구이', 'ssalbab':'쌀밥', 'gyelanhulai':'계란후라이',
'gyelanmal-i':'계란말이'}
label_acc = label.split(' ')
new_label = machine129_dic[label_acc[0]]
# 정확도까지 출력하려면
new_label_acc = machine129_dic[label_acc[0]] + ' ' + label_acc[1]이후 detect.py에서 여전히 한글을 읽을 수 없어서 살펴보았더니
annotator = Annotator(im0, line_width=line_thickness, example=str('가나다'))부분에서 example을 한글인 가나다로 수정해주었더니 한글화가 되었다.
Annotator의 경우 YOLOv5에서 만든 모듈이었는데 안을 살펴보니 abc로 사용하면 폰트를 정하는 부분에서 Unicode를 사용하지 않아 발생하는 문제였다.
🎨 2. 추천에 따른 분류
우리는 먼저, 이 음식이 추천 인지, 아닌지 구별을 할 필요가 있었다.
그래서 질병에 따른 기피 음식을 미리 정해놓고 피해야할 음식의 class num을 따로 입력 받게 하였다.
그래서 가장 첫 def run()의 파라미터를 하나 집어넣고 parser.add_argument를 통해 입력을 받을 수 있게끔 하였다.
@torch.no_grad()
def run(
weights=ROOT / 'yolov5s.pt', # model.pt path(s)
# ... 중략
machine129=[], # machine129 우리가 추가한 것
)def parse_opt():
parser = argparse.ArgumentParser()
# ... 중략
parser.add_argument('--machine129', nargs='+', type=int, help='machine129 I want to change box colors!')
# ... 후략이를 통해 피해야할 음식의 class num 숫자들을 받으면 이를 구분 할 수 있게 되었다.
그리고 위의 딕셔너리 작업을 한 이후 다음과 같은 명령을 주었다.
if len(machine129) == 0:
annotator.box_label(xyxy, machine129_dic[label_acc[0]] + ' ' + label_acc[1], color=colors(c, True))
else:
if c in machine129:
annotator.box_label(xyxy, machine129_dic[label_acc[0]], color=colors(0, True), safe129 = 'warn')
else:
annotator.box_label(xyxy, machine129_dic[label_acc[0]], color=colors(8, True), safe129 = 'safe')여기서 color = colors 파라미터를 통해 박스의 색깔을 바꿀 수 있었다.
임의의 색깔 0, 8로 주어 구별하였으며 O, X그림과 우리가 원하는 색깔을 집어 넣기 위해 코드들을 살펴 보았다.
safe129의 경우 우리가 O, X를 그리기 위해 추가로 준 파라미터이다.
다음은 우리가 모양을 바꾸기 위해 모듈을 수정하였다.
detect.py를 살펴보면 아래와 같은 코드로 모듈을 불러오는 것을 확인했다.
from utils.plots import Annotator, colors, save_one_box그래서 utils폴더 안의 plots.py를 직접 열어 보았다.
우리는 여기서 크게 2가지를 수정하였다.
🥇 첫번째는, 색깔이다.
class Colors:
안의 우리가 임의로 주었던 0, 8이 hexs라는 튜플에 hex코드로 색깔이 20가지가 있는 것을 보았다.
그래서 0, 8의 위치에 해당하는 hex색을 좀더 깔끔한 빨강과 녹색의 hex코드로 FF0000, 00FF00로 바꾸어 주었다.
class Colors:
# Ultralytics color palette https://ultralytics.com/
def __init__(self):
# hex = matplotlib.colors.TABLEAU_COLORS.values()
hexs = ('FF0000', 'FF9D97', 'FF701F', 'FFB21D', 'CFD231', '48F90A', '92CC17', '3DDB86', '00FF00', '00D4BB',
'2C99A8', '00C2FF', '344593', '6473FF', '0018EC', '8438FF', '520085', 'CB38FF', 'FF95C8', 'FF37C7')
self.palette = [self.hex2rgb(f'#{c}') for c in hexs]
self.n = len(self.palette)🥈 두번째는, 모양이다.
class Annotator:
에는 box_label이라는 함수가 있었고 그림을 그리는 것을 알 수 있었다.
우리는 안전한지 위험한지 safe, warn을 통해 파라미터를 입력받게 하고 PIL (pillow)라는 라이브러리를 통해 직접 그림을 그려주었다.
class Annotator:
def box_label(self, box, label='', color=(128, 128, 128), txt_color=(255, 255, 255), safe129 = ''):
# Add one xyxy box to image with label
if self.pil or not is_ascii(label):
if safe129 != 'safe' and safe129 != 'warn':
self.draw.rectangle(box, width=self.lw, outline=color) # box
if label:
w, h = self.font.getsize(label) # text width, height
outside = box[1] - h >= 0 # label fits outside box
self.draw.rectangle(
(box[0], box[1] - h if outside else box[1], box[0] + w + 1,
box[1] + 1 if outside else box[1] + h + 1),
fill=color,
)
if safe129 == 'safe':
self.draw.arc(
(box[0], box[1], box[2], box[3]),
start=0, end=360, width=self.lw, fill=color
)
if safe129 == 'warn':
self.draw.line(
(box[0], box[1], box[2], box[3]),
fill=color, width=self.lw
)
self.draw.line(
(box[2], box[1], box[0], box[3]),
fill=color, width=self.lw
)
# self.draw.text((box[0], box[1]), label, fill=txt_color, font=self.font, anchor='ls') # for PIL>8.0
self.draw.text((box[0], box[1] - h if outside else box[1]), label, fill=txt_color, font=self.font)직접 박스 좌표 box를 받아 rectangle을 통해 네모를 그려주었기에 우리는 draw.arc로 원을 그리고 draw.line 선 두개로 X를 그려주었다.
그 결과 다음과 같이 출력 할 수 있었다.

🎯 느낀 점
사실 이 YOLOv5코드를 뜯어보기 전 까진 Class라는 객체를 왜 사용해야하는지 알고는 있었지만 느끼지 못하고 있었다.
하지만 복잡하고 긴 코드를 보며 내가 필요한 부분을 수정하기 위해 직접 살펴 볼 필요가 있었고,
여기서 모듈화한 함수들을 Class 객체로 분류해놓음으로써 내가 원하는 부분을 정말 쉽게 찾아 볼 수 있었다.
정말 작은 기능 하나하나 모여 객체탐지라는 복잡한 기능을 구현해 놓은 듯한 느낌도 많이 받았다.
그래서 객체지향 프로그래밍이 무엇인지, 왜 사용하는지, 조금이나마 이해하게 된 것 같았다.


yolov5를 공부하고 있는 대학생입니다.
코드 관련하여 질문드려도 될까요?