21.12.22 ~ 2022.06.16 경북대 K-Digital Training 빅데이터 분석가 양성과정 1기 최종 프로젝트
주제 선정부터 최종 발표까지 22.04.20 ~ 22.06.15
📔 주제 선정
📌 주제 선정 배경
최종프로젝트는 기업참여 프로젝트로 여러 주제 중 우리가 선택하여 주제를 선정하게 되었다.
그래서, 우리 팀이 원하는 조건과 잘 부합할 수 있는 주제를 선정할 필요가 있었다.
우리 팀의 주제 선정 조건은 크게 2가지였다.
- 의료 데이터
- 객체 탐지
이 두가지가 우리 팀이 원하는 프로젝트였고, 우리는 이 두가지 조건을 만족시킬 수 있는 주제로 고령자를 위한 헬스케어 플랫폼을 주제로 선정하게 되었다.
📌 기업 멘토 미팅
주제 선정을 마치고, 기업에서 멘토와의 첫 미팅을 가졌다.
첫번째로, 기업 멘토분의 요구사항을 듣고, 우리의 요구사항과 의견을 말씀드리고 피드백을 받을 생각이었다.
우리의 첫번째 요구사항은 이것이다.
우리가 제공 받을 수 있는 데이터가 있나요?
아쉽게도 의료데이터 이다보니 제공해 줄 수 없다는 답변을 받았다.
대신, 어떤 식의 데이터를 활용하던 상관이 없고 우리의 방식대로 결과를 도출해내도 좋다는 이야기를 들었다.
이야기를 나누다보니 아마, 멘토분께서는 우리가 원하는 프로젝트 주제선정과 해보고 싶은걸 다 해보고, 직접 느껴보는게 좋다는 생각이신 것 같았다.
대신, 기업에서 요구하는 첫번째 사항은 주간보고서였다.
어떤 결과가 나오든, 혹여 결과가 나오지 않았더라도 보고서를 통해 어떻게 진행되었는지를 작성해서 매주 목요일에 보내드리기로 했다.
두번째 요구사항은 생활패턴 개선이었다.
단순히 예측하고, 추천하는 방식이 아닌, 결국 사용자에게 서비스 되려면 개선할 수 있어야 한다는 말씀을 하셨다.
그래서 어떤 식으로든 결과를 만들고, 생활패턴을 어떻게 개선해야하는지 제공해달라고 하셨다.
세번째는 웹이든 어플이든 만들어 보라고 하셨다.
기간이 굉장히 짧다라는 말씀을 하시면서 대신, 디자인이나 이런건 일체 신경쓰지 않고, 데이터 입력과 출력만 원하는 대로 "나오기만" 하면 된다고 하셨다.
미팅을 마치고, 우리는 어떻게 프로젝트를 진행할 지, 구체화하였다.
📕 프로젝트 구체화
우리는 프로젝트를 어떻게 구체적으로 진행할 지에 대해 이야기했다.
첫번째로, 직접적으로 프로젝트를 어떻게 진행할 것인지,
두번째로, 프로젝트 진행하면서 어떤 환경에서 진행할 것인지.
🎯 프로젝트 진행 방향
우리가 선정했던 두가지의 선정 조건을 어떻게 프로젝트에 적용시킬 것인지 이야기했다.
그 결과, 우리는 두가지의 방향에서 분석을 진행하고, 서비스로 제공하기로 했다.
첫번째는 질병 예측이다.
우리는 생활 패턴과 질병의 유병률을 분석하여 생활패턴과 유병률의 상관관계를 기반으로 질병예측을 하기로 했다.
그래서 사용자의 생활패턴을 기반으로 질병이 있을지 없을지를 예측하도록 했다.
두번째는 식단 개선이다.
객체탐지를 통해 사용자의 식단을 사진촬영을 통해 입력 받으면, 어떤 음식은 먹어도 좋은지, 어떤 음식은 피해야하는지, 질병예측 결과를 바탕으로 추천해주기로 했다.
마지막으로 이 두가지를 연결하여 웹앱으로 서비스를 제공하는 프로젝트를 진행하였다.
최종 발표까지 약 8주간의 기간이 주어졌는데, 발표 준비까지 생각한다면 꽤 빠듯하리라 생각했다.
🎯 프로젝트 개발 환경
방향은 정해졌으니 우리는 어떻게 개발할 것인가라는 이야기가 나왔다.
우리는 6명과 함께 협업을 하는 팀이었기에, 협업과 관련된 이야기가 가장 먼저 나왔다.
그래서 몇가지 툴들을 사용하기로 했다.
🧿 Github
우리는 깃헙을 통해 코드를 함께 만들기로 했다.
나를 포함하여 깃허브를 다뤄보지 않은 팀원들이 많았다.
깃허브를 다뤄본 팀원들도 개인으로 사용하고 팀으로는 사용해본 적이 없었다고 한다.
그래서 한번 해보자라는 생각으로 깃허브를 통해 협업하기로 했다.
🧿 Slack
깃헙뿐만 아니라, 우리의 진행상황과 의견, 참고 자료 등을 의논할 곳이 필요했다.
카카오톡으로 용도에 따라 구분하기에는 문제가 있었다고 생각하고 슬랙을 사용하기로 했다.
슬랙에서 진행상황에 공유하고, 깃헙에 코드 올라오는 것도 알림을 받을 수 있어 유용했다.
🧿 Notion
슬랙에는 우리가 의논할 공간이라면, 문서작업과 문서를 관리할 곳이 필요했다.
기업 요구사항에도 주간 보고서가 있었고, 강사님께서도 회의록, WBS 등 많은 문서를 작성해보고 요구하셨기에 노션을 통해 문서들을 관리했다.
📙 진행
우리는 시간이 부족할 것 같아 팀 내에서도 인원을 나누어 두 팀으로 나누었다.
앞서 말한것 처럼, 질병 예측팀과 객체 탐지(식단개선) 팀으로 나누어 진행하기로 하였다.
이후, 완료되는 대로 함께 웹앱을 만드는 방향으로 진행하였다.
🎀 질병 예측
질병예측에 사용 될 데이터는 생활패턴과 질병에 대한 정보를 가지고 있는 데이터가 필요했다.
그 결과 우리는 질병관리청에서 제공하는 국민건강영양조사 데이터를 구할 수 있었다.
🧸 데이터 전처리
우리가 사용한 주로 사용한 데이터는 국민건강영양조사 데이터 였다.
굉장히 많은 항목으로 이루어진 설문지 형태의 데이터였고, 매년 진행되었지만 매년 질문지의 항목도 다른 점들이 몇몇 있었다.
우리는 최근 5년치의 데이터를 사용하였고, 데이터를 살펴보았다.
데이터는 1년에 약 800개의 컬럼으로 이루어져 있었고, 매년 중복되기도, 중복되지 않기도 하였다.
설문지 형태의 데이터다보니 값이 1, 2 라고 해서 어떤 의미인지 알 필요도 있었고, 컬럼명도 항목번호에 맞추어두어서 하나하나 찾아보고 이해할 필요가 있었다.
게다가 같은 질문인데도 컬럼명이 다르고, 컬럼명이 같은데 질문이 다른 경우가 존재해서 5년치 데이터를 합치고 통일하는 데 생각보다 많은 시간을 소요했다.
데이터에는 무응답, 비대상이라는 항목들도 존재하여 의미가 없는 데이터를 제거하는 작업을 진행하였다.
우리가 제공하는 서비스에 설문지는 문항을 많이 간소화 할 생각이었기에 질병들에 대해 상관관계가 높은 항목들, 여러 질병에 상관관계가 나타나는 항목들을 간추리는 작업을 진행하여 총 35개의 항목으로 줄였다.
또한, 모델의 정확도에 신뢰성을 높이기 위해, 지나치게 유병률이 치우진 경우, 비율을 맞춰주는 작업을 진행했다.
🧸 모델링
우리는 총 20개의 질병에 대해 질병을 예측하는 모델을 진행했다.
질병마다 모델링을 하였기에 우리는 총 20개의 모델이 만들어졌다.
모델링은 pycaret이라는 라이브러리를 통해 정확도가 높은 모델을 선정했다.
그 결과 Support Vector Machine 모델과 Logistic 회귀 모델이 가장 많이 사용되었고 정확도는 최소 74.2% ~ 최대 84.5% 로 약 80퍼센트의 정확도를 가지고 있었다.
이 모델들은 pickle파일로 만들어 사용하였다.
🧸 결과 및 사용
설문지 응답 항목에 대해 테스트를 진행해본 결과, 유병률에 대한 예측 결과가 확률로 나타나는 것을 확인하였다.
우리는 각 90%이상인 항목은 위험, 50% 이상 주의, 그 외 정상으로 총 3단계로 나누어 나타내었다.
그 결과,
위험 질병 : A
주의 질병 : B, C
정상 질병 : D, E ...
와 나타낼 수 있게 표현이 가능했다.
🎁 객체 탐지 (식단 개선)
우리는 식단 사진을 찍어서 어떤 음식이 있는 지 탐지하는 모델을 만들기 위해 객체 탐지를 진행하였다.
⚡ 사용 데이터
우리는 총 22종의 한식 사진을 약 200장 정도씩 총 4500장 가량의 사진을 사용했다.
앞서 사용한 국민건강영양조사 데이터에 최근에 어떤 식사를 했는지에 대한 항목이 있었고 그 항목에 대해 만 65세 중 가장 많이 나오는 음식 20종과 우리가 발표를 하기 위해 준비할 사진에 따로 존재하는 2종을 추가하여 22종의 사진을 구하였다.
사진은 AI hub 에서 제공하는 한식 사진과 크롤링을 통해 사용하였다.
크롤링은 만개의 레시피라는 사이트와 bing에서 크롤링 하여 사용하였다.
⚡ 데이터 라벨링
우리는 makesense.ai 라는 툴을 사용하여 라벨링을 진행했다.
makesense에서는 이미지 사진을 집어넣고 객체가 있는 위치에 bounding box를 그리면 해당 좌표와 객체의 class num을 yolo에서 사용하는 형태로 포맷하여 저장하게 만들어 주는 툴이다.
앞서 수집한 사진들이 실제로는 수만장이 훨씬 넘었지만 이 과정에서 직접 선별과 box작업, 라벨링을 진행하며 4500장을 사용하였다.
⚡ 모델링
우리는 yolov5라는 모델을 사용하여 객체 탐지를 진행하였다.
객체탐지에 많은 모델들이 있었는데 yolov5를 사용한 이유에 대해 한번 적어보고자 한다.
1. 🎨 최신 모델
우리는 예전에 나온 모델보다는 최근 모델들을 사용해보고 싶었다.
yolov5의 경우 약 1~2년전에 나온 모델로 현재까지도 깃허브에 코드가 업데이트 되고 있는 걸 보았기 때문에 최신 모델을 사용하고자 하는 우리의 조건에 일치했다.
2. 🎨 PyTorch 기반의 모델
이전 v4까지 yolo 시리즈의 모델은 tensorflow기반의 모델이었다.
하지만 v5부터는 pytorch기반의 모델이 되었는데 두 차이점은 다음과 같다.
Tensorflow 의 장점
1. pytorch보다 사용하고 있는 곳이 많음.
2. 더 큰 오픈소스 커뮤니티. (리소스나 솔루션 제공 받기 쉬움)
PyTorch 의 장점
1. 훨씬 직관적임
2. 위의 장점 때문에 pytorch기반의 논문들이 굉장히 늘어나고 있는 추세임
우리는 우리가 사용하고자하는 목적에 따라 개선할 필요가 있었기 때문에 직관적이라는 PyTorch가 더 사용하기 적합하다고 생각했다.
3. 🎨 많은 모델
yolov5는 모델의 크기로 크게 s, m, l, x 등 나누어서 여러가지 모델을 제공하고 있다.
모델의 크기가 클수록 정확도가 좋고, 작으면 속도 측면에서 좋다는 장점이 있다.
우리는 약 8주라는 프로젝트 기간동안 많은걸 해보고 싶고, 기간도 생각보다 짧은 것 같다는 생각이 들어 정확도 vs 속도라는 선택지가 꽤 매력적이었고, 실제로 s 모델을 사용하다가 m을 사용해보기도 하며 직접 비교해보며 사용하였다.
⚡ 개선
우리는 이 과정에서 몇가지 문제에 부딪혔다.
1. 🩸 한글화
우리는 class num에 대한 음식 이름을 Yaml파일로 저장하였는데, 이 파일을 인코딩하면 읽지를 못하고, 그렇지 않으면 한글을 쓸 수 없는 문제가 생겼다.
그래서 우리는 영어로 이름을 다 작성하고, 마지막에 detect 부분에서 영어이름으로 나온 결과를 딕셔너리를 통해 한글로 수정하여 출력하게 끔 만들었다.
2. 🩸 Plot
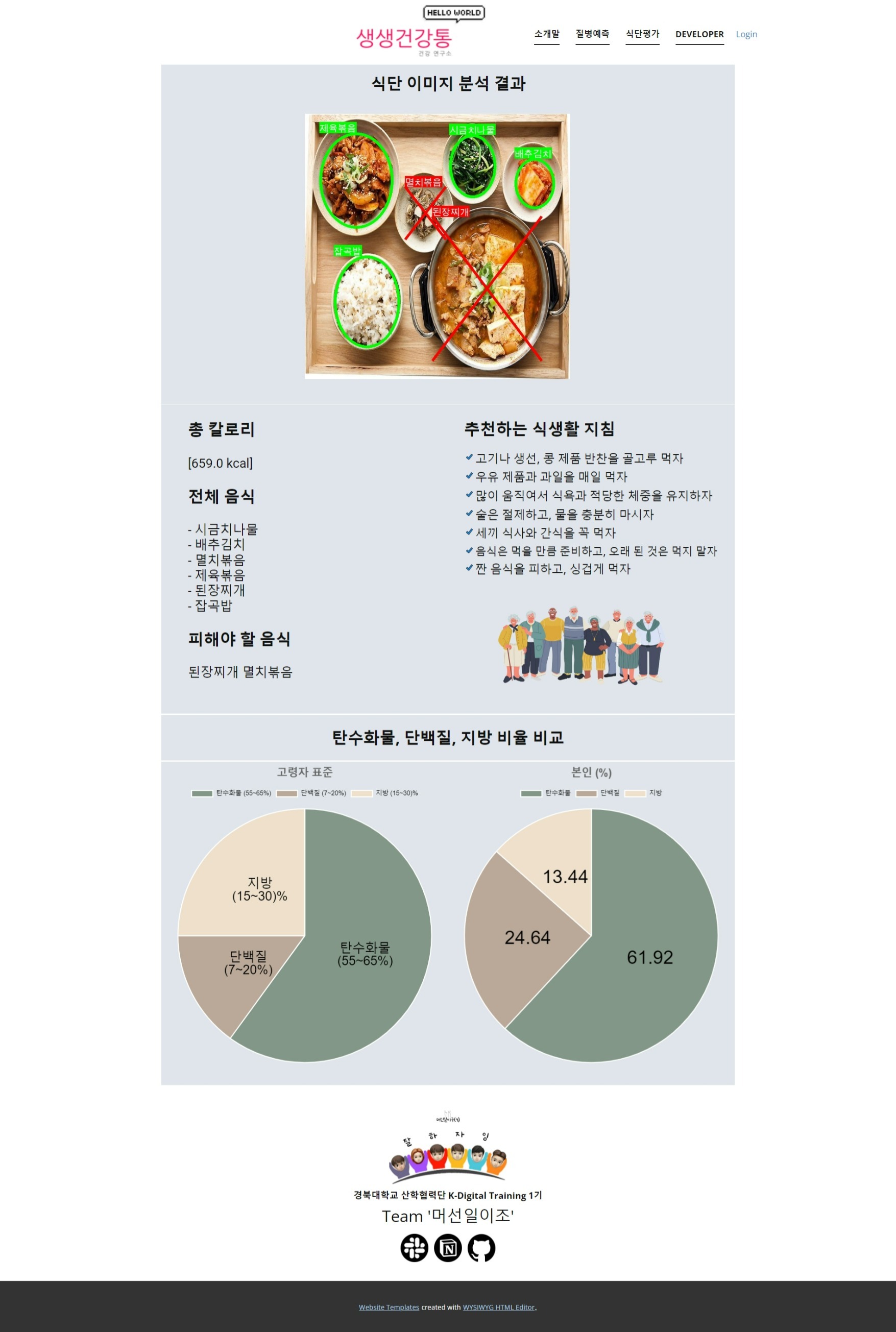
기존 결과는 탐지한 객체에 따라, 이름과 정확도가 위에 나오고, 네모 모양의 박스로 위치를 알려주는 결과를 출력했다.
우리는 사진에서부터 기피 음식과 그렇지 않은 음식으로 나눌 필요가 있었기 때문에 코드를 찾아보기 시작했다.
그 결과, yolov5안의 utils라는 디렉토리에 plot이라는 모듈을 발견할 수 있었다.
plot이라는 모듈에서는 PIL(pillow)를 이용하여 좌표를 받아 직접 네모 박스를 그리고 적어주는 것을 확인하였다.
그래서 먼저, 우리는 탐지한 객체가 기피해야 하는 음식인지 아닌지를 나누어 입력을 받게 하고 분루하였다.
그 후에, O와 선 2개를 통해 X를, 그리고 색깔을 O는 Green, X는 Red로 Hex 코드를 찾아 주었다.
📦 데이터베이스
우리는 Google Cloud의 MySQL로 데이터 베이스를 구축했다.
위 과정의 코드들을 작성하며 동시에 DB 연결과 입력과 출력을 진행하였다.
pymysql이라는 라이브러리를 사용하였으며, 우리가 원하는 테이블에 원하는 데이터를 집어넣기 위해 함수를 모듈화 하여 만들어서 사용하였다.
Yolov5의 코드들이 알아보기 쉽고 깔끔하게 정리되어있어 비슷하게 흉내내보며 사용하였으며,
코드들이 Class로 함수를 구분해놓으니 원하는 부분만 찾아보는게 굉장히 편했기 때문에 Class로 만들어 작성했다.
📒 웹
우리는 Flask를 통해 웹 서버 구축과 배포를 했다.
파이썬을 사용한 웹 프레임워크에는 Django도 있었고, 많은 기능들이 제공되는 것도 보았다.
하지만 우리는, 실제로 배포 해보는 것은 처음이었고, 많은 이해가 필요로 했기때문에 필요한 기능을 직접 찾아서 밑바닥에서부터 설계 할 수 있게끔 유연성이 장점인 Flask를 사용했다.
아무래도 발표를 할 때, 결과를 어느정도 꾸밀 필요가 있었기 때문에 HTML과 CSS도 직접 만들며 서버를 구축했다.
GCP의 서버를 사용하여 배포를 하려고 했는데 local환경에선 CSS가 잘 적용되고 window에서 배포하니 잘 되는게 GCP에서 배포하기만 하면 CSS가 적용이 되질 않았다.
환경이 잘못 된건가 싶어 굉장히 가볍게 테스트용으로 만든 코드에는 CSS가 잘 적용 되는 걸 보아 다른 문제가 있겠다 싶었지만, 시간 문제상 발표는 Local환경에서 배포와 진행을 하였다.
📘 아쉬웠던 점..
너무 좋은 팀원들을 만나 만족스러운 결과를 얻은 것 같았다.
8주라는 시간이 정말 눈 깜짝할 새 지나간 것 같다.
특히 협업하는 방법과 제대로 해본 적 없는 것들을 직접 공부해가며 구현하는 것은 재밌었고 만족스러웠다.
하지만 더 나은 발전을 위해 아쉬웠던 점을 정리해보았다.
📖 디버깅
디버깅을 하는데 꽤 많은 시간을 소요했다.
물론 많은 시간을 소요하는게 어떻게 보면 당연하기도 하지만, 특히 마지막에 해결하지 못했던 GCP서버 배포 부분에서 CSS가 적용되지 않는 문제를 해결하지 못한 점이 아쉬웠다.
📖 데이터
분명 의료데이터를 사용하려다 보니 많은 제약이 있었고 그로 인해 데이터의 규모가 상대적으로 작았다고 생각된다.
게다가 한식사진을 따로 사용해보았지만 사용한 사진 양도 별로 많이 되지 않았다.
많은 데이터를 핸들링해보는 경험도 해봤으면 하는 아쉬움이 남기도 한다.
📖 NoSQL
객체 탐지 결과를 DB에 저장할때, 어떤 음식, 또는 몇개의 음식이 나올지 몰라 Key-Value형태의 NoSQL DB가 더 어울리지 않았나 싶은 생각이 든다.
NoSQL을 직접 다뤄본적이 없어 결과를 다른 방식으로 RDBMS인 MySQL로 사용했는데 NoSQL로 사용해봤으면 어땠을까 하는 아쉬움이 남는다.
📖 모델링
우리가 사용한 ML모델들은 오랜 시간동안 전처리 과정을 거쳐 사용하였다.
정작 프로젝트가 끝나고 나니, 결과를 만들어 낸 후에, 추가로 개선하기 위해 다른 방법을 써보는 등에 대한 것들이 약간 부족하지 않았나 싶다.
실제로 개선된 결과가 많이 없어서 그랬나 싶기도 하지만, 개선이 되었다면 더 좋았을 것이라 생각된다.
📖 웹 캐시
우리가 너무 많이 테스트를 진행하다보니 웹에서 자동으로 사진을 캐시 저장을 하기 시작했다.
캐시를 무시하고 불러오게끔 진행하였지만, 캐시저장을 하지 않게 만드는 방법이 있지 않을까 싶기도 하다.
마지막에 발견되어 개선하지 못했지만, 다음엔 다른 방법으로 많이 사용하더라도 저장하지 않게끔 만들어 보고 싶은 생각이 든다.
📗 마치며..
직접 공부하고 배운것이 너무 많고 좋은 팀원들을 만나 가장 만족했던 프로젝트였다.
특히, 내가 작성한 코드들이 다른 팀원들이 보기에 어떻게 느껴지는지, 어떻게 하면 알아보기 쉽게 만들 수 있을지 실제로 사용되는 코드들을 보고 흉내내보며 만들어 보는 등 협업에 필요한 능력이 무엇인지 하나하나 느껴볼 수 있었다.
그와 동시에 6개월간 정말 많은 걸 배웠다고 생각했는데 아직까지도 많은 부족함이 느껴지는 프로젝트였다.
특히, 우리는 많이 쓸 일 없을 줄 알았던 JS는 왜 많이 쓰는지 말해주기라도 하듯, 많은 기능들이 JS 공부를 시작하게 만들기도 했다.
그래서 사실 조금더 공부를 하고 취업준비를 하고 싶지만, 늦게 시작한 탓인지 시간에 쫓기는 듯한 느낌이 들어 내 역량을 올릴 수 있는 기업과 함께 빨리 취업하고 싶다는 생각도 들고 있다.
또, 실제 프로젝트를 진행해보며 필요에 의해, 배우는 것이 너무 즐겁고 효과적이었다고 생각한다.
아마 앞으로는 개인 공부와 더불어 나만의 작은 프로젝트를 틈틈히 진행하며 공부하고자 한다.
마지막으로 이번 프로젝트의 대한 결과는 깃허브에서 확인할 수 있다.
다음 이미지들은 질병예측 결과와 식단추천 결과 페이지이다.
1. 질병 예측 결과 페이지

2. 식단 추천 결과 페이지