
1. 학습
사용 모델 - YOLO v8 Nano
학습은 YOLO v8 Nano를 이용했다. YOLO v8 Nano는 경량화된 아키텍처를 제공하여 모델 크기가 작고, 메모리 사용량이 적다. Colab의 제한된 컴퓨팅 자원을 사용하고 있기 때문에 최대한 빠르고 가벼운 버전을 찾아서 써야했기 때문에 완전 최신은 아니면서 괜찮은 모델로 YOLO v8 Nano를 선택했다.
설치
ultralytics 설치
!pip install ultralytics
import ultralytics
print("Ultralytics version:", ultralytics.__version__)출력
Ultralytics version: 8.3.53`강제로 UTF-8로 인코딩
import locale
locale.getpreferredencoding = lambda: 'UTF-8'학습
학습하기 전 data.yaml 형식 확인
!cat /content/fishitify/data.yaml출력
names:
- bang-eo
- daegu
- gamseongdom
- gasung-eo
- godeung-eo
- hwang-eo
- nong-eo
- sung-eo
nc: 8
roboflow:
license: Private
project: fishitify
url: https://app.roboflow.com/fishistify/fishitify/4
version: 4
workspace: fishistify
test: ../test/images
train: ../train/images
val: ../valid/images`데이터 학습
지난 번 토이프로젝트에서 Early stopping의 patience를 낮게 설정해서 충분한 학습을 하지 못했음. 이번에는 patience의 값을 높이고 epochs도 300으로 넉넉한 값으로 설정.
from ultralytics import YOLO
model = YOLO('yolov8n.pt') # Pre-trained 모델 로드
model.train(
data='/content/fishitify/data.yaml',
epochs=300,
patience=50,
batch=16,
imgsz=640,
name='yolov8_training',
device=0
)출력
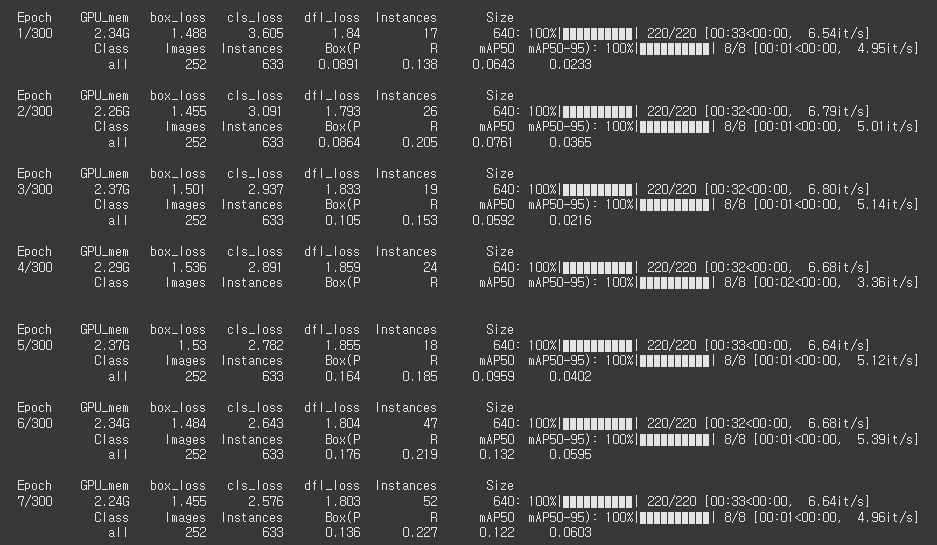
확인
import pandas as pd
import matplotlib.pyplot as plt
results_csv = '/content/runs/detect/yolov8_training3/results.csv'
results_df = pd.read_csv(results_csv)
# 컬럼 출력 및 확인
print("사용 가능한 컬럼:")
print(results_df.columns)
plt.figure(figsize=(14, 8))
# 손실 그래프: Train Loss vs Validation Loss
plt.subplot(2, 1, 1)
plt.plot(results_df['epoch'], results_df['train/box_loss'], label='Train Box Loss', marker='o')
plt.plot(results_df['epoch'], results_df['val/box_loss'], label='Validation Box Loss', marker='o')
plt.plot(results_df['epoch'], results_df['train/cls_loss'], label='Train Class Loss', linestyle='--', marker='x')
plt.plot(results_df['epoch'], results_df['val/cls_loss'], label='Validation Class Loss', linestyle='--', marker='x')
plt.title('Training vs Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)
# 정확도 그래프: Precision, Recall, mAP
if 'metrics/mAP50(B)' in results_df.columns:
plt.subplot(2, 1, 2)
if 'metrics/precision(B)' in results_df.columns:
plt.plot(results_df['epoch'], results_df['metrics/precision(B)'], label='Precision(B)', marker='o')
if 'metrics/recall(B)' in results_df.columns:
plt.plot(results_df['epoch'], results_df['metrics/recall(B)'], label='Recall(B)', marker='o')
if 'metrics/mAP50(B)' in results_df.columns:
plt.plot(results_df['epoch'], results_df['metrics/mAP50(B)'], label='mAP@50(B)', linestyle='--', marker='x')
if 'metrics/mAP50-95(B)' in results_df.columns:
plt.plot(results_df['epoch'], results_df['metrics/mAP50-95(B)'], label='mAP@50-95(B)', linestyle='--', marker='x')
plt.title('Precision, Recall, and mAP')
plt.xlabel('Epoch')
plt.ylabel('Metrics')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()총 160 Epchos 정도 학습하였다.
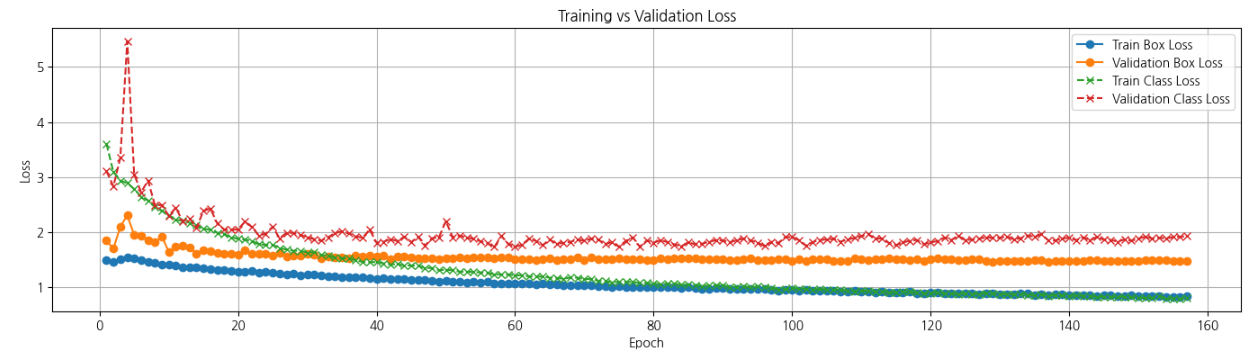
Box Loss
Train Box Loss와 Validation Box Loss는 학습 과정 초기에는 높은 값으로 측정되었지만, 에포크가 진행됨에 따라 안정적으로 감소하는 추세를 보인다. Validation Box Loss는 Train Box Loss와 유사한 감소 패턴을 보이며, 두 값 간의 차이가 크지 않다. 과적합 없이 학습되고 있다고 판단했다.
에포크가 약 50을 넘어선 이후에는 Validation Box Loss와 Train Box Loss 모두 비교적 낮고 안정적인 값을 유지하며, 학습이 수렴한 모습을 보여줍니다. Box Loss는 모델이 객체의 위치(바운딩 박스)를 잘 학습하고 있으며, 데이터셋에 대해 안정적인 성능을 보인다고 판단했다.
Class Loss
Train Class Loss와 Validation Class Loss는 초반에 급격히 감소하였지만, Train Class Loss가 지속적으로 낮은 값을 유지한 것과 비교해서 Validation Class Loss는 약간 높은 값을 유지했다. 이러한 모습은 학습 데이터에 비해 검증 데이터에 대해 상대적으로 더 많은 오차를 보인다.
하지만 Validation Class Loss의 값이 일정 범위에서 안정적인 모습을 보여, 비교적 안정적인 성능을 보여주고 있다고 판단했다. 클래스를 더 명확하게 구분할 수 있는 방법을 고민해보면 좋겠다. 🤔
해양생물에 대한 분류 연구가 선행되지 않아 분류 기준을 명확히 판단하지 못한 점은 이번 프로젝트의 아쉬운 부분 중 하나였다. 과(Family), 속(Genus), 종(Species) 중 하나를 기준으로 삼아 데이터를 체계적으로 정리한 후 진행했다면 훨씬 신뢰도 높은 Object Detection 프로젝트였을지도..
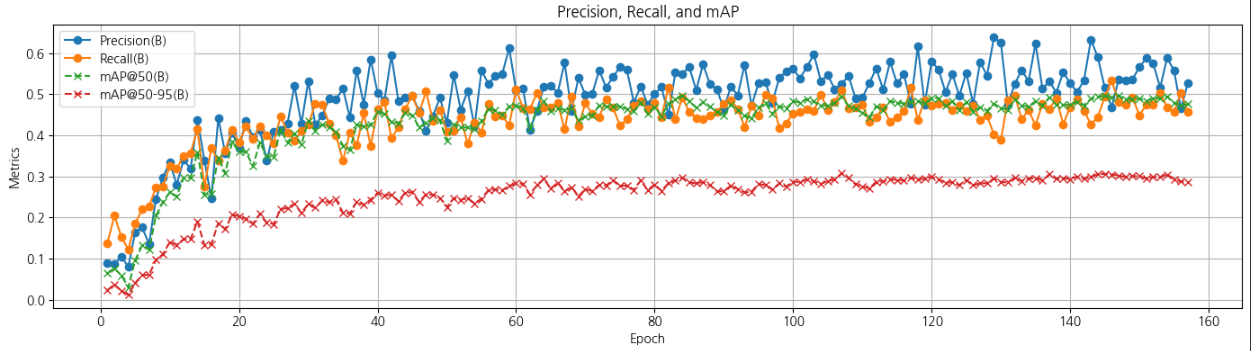
Precision (B)
Precision 값은 초기 에포크에서 큰 변동을 보였으나, 에포크 50 이후에는 대체로 안정적인 패턴을 나타내며 평균적으로 약 0.5~0.6 수준을 유지했다. 이는 기대했던 만큼 높은 수치는 아니지만, 8개의 클래스를 선정하고 특히 구분이 어려운 가숭어와 숭어를 포함시켜 모델의 성능을 평가하고자 한 의도적인 구성으로 해석할 수 있다. 이러한 구성은 YOLO의 실질적인 분류 능력을 확인하기 위한 시도로 의미를 부여해보겠다...😂
Recall (B)
Recall 값은 초기 에포크에서 빠르게 상승한 후, 에포크 50 이후로 안정적인 상태에 도달했다. 평균적으로 약 0.5~0.6의 값을 유지하며, Precision과 유사한 경향을 보인다. Recall이 높은 것은 모델이 실제 객체를 잘 탐지하고 있다는 것을 의미하기 때문에 그래도 상승은 하네.. 라는 마음에 좀 안심했다... 휴...
mAP@50 (B)
mAP@50은 IoU(Intersection over Union) 0.5를 기준으로 계산된 평균 정확도로 학습 초반부터 꾸준히 상승하며 에포크 50 이후 안정적으로 약 0.5~0.6 사이를 유지하고 있다. 바운딩 박스가 얼마나 잘 겹쳐졌나를 보는 것이기 때문에 그래도 반 이상은 갔구나 싶었다.
mAP@50-95 (B)
mAP@50-95는 IoU 0.5에서 0.95까지 다양한 기준에서 계산된 평균 정확도이다. 엄격한 평가 기준을 반영하기 때문에 약 0.3 수준에 그쳤다.
2. 평가
테스트 파일에서 무작위 9장을 가져와서 학습된 베스트 모델로 예측을 해보았다. 파란색은 예측한 바운딩 박스이고 초록색은 정답 바운딩 박스이다.
import os
import random
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
from ultralytics import YOLO
# 1. 학습된 모델 로드
model = YOLO('/content/runs/detect/yolov8_training3/weights/best.pt')
# 2. 테스트 이미지 경로 설정
image_folder = '/content/fishitify/test/images'
label_folder = '/content/fishitify/test/labels'
# 클래스 이름 리스트 (data.yaml 파일에 있는 순서)
class_names = [
'bang-eo', 'daegu', 'gamseongdom',
'gasung-eo', 'godeung-eo', 'hwang-eo',
'nong-eo', 'sung-eo'
]
# 클래스별 색상 설정 (Ground Truth와 Prediction 색상 분리)
class_colors = {
'GT': 'green', # Ground Truth 색상 (초록색)
'Prediction': 'blue' # Prediction 색상 (파란색)
}
# 폴더 내의 모든 .jpg 파일 리스트 가져오기
image_files = [f for f in os.listdir(image_folder) if f.endswith('.jpg')]
# 랜덤으로 9개의 이미지 선택
random_images = random.sample(image_files, min(9, len(image_files)))
# 3. 3x3 그리드로 테스트 이미지 표시
fig, axes = plt.subplots(3, 3, figsize=(15, 15))
for ax, img_file in zip(axes.flat, random_images):
# 이미지 경로
img_path = os.path.join(image_folder, img_file)
img = plt.imread(img_path)
img_h, img_w = img.shape[:2]
# Ground Truth 라벨 경로
gt_label_file = os.path.join(label_folder, img_file.replace('.jpg', '.txt'))
# 4. Ground Truth 바운딩 박스 표시
if os.path.exists(gt_label_file):
with open(gt_label_file, 'r') as f:
for line in f:
# YOLO 형식 GT 데이터 파싱
class_id, x_center, y_center, width, height = map(float, line.strip().split())
class_name = class_names[int(class_id)] # 클래스 이름 가져오기
# YOLO 형식을 픽셀 좌표로 변환
x_center *= img_w
y_center *= img_h
width *= img_w
height *= img_h
x1 = int(x_center - width / 2)
y1 = int(y_center - height / 2)
# 바운딩 박스 및 라벨 표시
ax.add_patch(Rectangle((x1, y1), width, height, edgecolor=class_colors['GT'], facecolor='none', linewidth=2))
ax.text(x1, y1 - 10, f"GT: {class_name}", color='black', fontsize=10, backgroundcolor='white')
# 5. Prediction 결과 표시
results = model.predict(source=img_path, save=False, conf=0.25)
for pred in results[0].boxes:
# Prediction 데이터 파싱
x1, y1, x2, y2 = map(int, pred.xyxy[0]) # 바운딩 박스 좌표
class_id = int(pred.cls[0]) # 클래스 ID
confidence = float(pred.conf[0]) # 신뢰도
class_name = class_names[class_id] # 클래스 이름
# 바운딩 박스 및 라벨 표시
ax.add_patch(Rectangle((x1, y1), x2 - x1, y2 - y1, edgecolor=class_colors['Prediction'], facecolor='none', linewidth=2))
ax.text(x1, y2 + 10, f"Pred: {class_name} ({confidence:.2f})", color='blue', fontsize=10, backgroundcolor='white')
# 이미지 출력
ax.imshow(img)
ax.axis('off')
plt.tight_layout()
plt.show()

best model을 가지고 streamlit을 활용해서 간단한 웹페이지를 구현했다.
같은 교실을 사용하는 사람만 잠깐 볼 수 있도록 서버를 열어두었다.
아직 너무 부족한 Fishitify를 해결하기 위해
3. 앞으로...?
프로젝트 기간에 기회가 된다면
- 사전적 분류로 체계화된 라벨링 하기
- 여러 해양생물이 있는 사진에서 잘 분류하는 모습 보여주기
---> 클래스에 해당하는 해양생물을 한 장면에 합성 - 참여형 웹플랫폼 구축
---> 사람들이 새로운 데이터(라벨링 완료)를 업로드 하고 이를 학습시켜 결과를 확인 할 수 있는 페이지 구축 (서버 비용은..?) ㅋㅋ 😮
위 내용을 하면 참 좋겠다.. 참.. 🙄
object detection


