Bag-of-Words(Naive Bayes Classifier)
흔히 얘기하는 통계적 방법의 NLP이다. 텍스트 데이터 속 무수히 많은 단어들을 one-hot vector로 만들고 각 문장들을 이 one-hot vector로 표현하는 방식이라 할 수 있다.
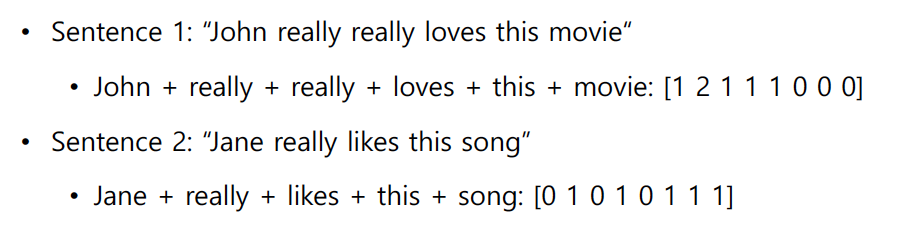
Naive Bayes Classifier는 단어-문맥 행렬을 통해 단어의 빈도를 파악하고 이를 베이즈 정리를 통해 해당 문맥, 문장의 클래스를 분류하는 것이다. 최종적인 목적식은 다음과 같다.
마지막 식에서 분모가 사라진 것은 문서 혹은 문장이 등장할 확률인 는 argmax 연산에 independent하기 때문에 연산을 쉽게 하기 위해 제외되었다.
라고 할 수 있고, Bag-of-Words에서는 기본적으로 각 단어의 순서와 나열에 있어서 서로 독립적이라는 가정을 한다. 따라서 해당 클래스에 대해 각 단어의 조건부등장확률에 대한 곱으로 표현할 수 있게되는 것이다. 하지만 특정단어가 학습데이터에 등장하지 않는다면 아무리 나머지 문장의 단어가 해당 클래스와 연관이 높아도 결론적으로 해당 클래스가 될 확률이 0이 되기 때문에 이를 위해 regularization이 필요하긴 하다.
