2021년 8월 23일 ~ 2021년 9월 2일
본 글은 지난 2주동안 진행했던 Boostcamp AI-Tech 첫 p-stage인 Image Classification 대회 프로젝트의 Wrap-up report이다. 본래 report 형식에 따라 팀 제출 레포트를 먼저 올리고 이후 본인이 얻은 insight들에 대한 내용들을 이어나가겠다.
1. 팀 레포트
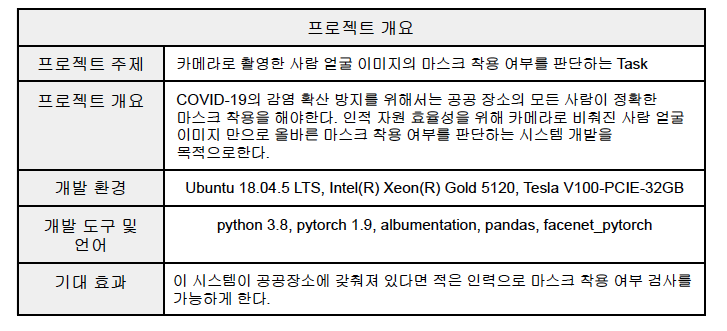
1. 프로젝트 개요
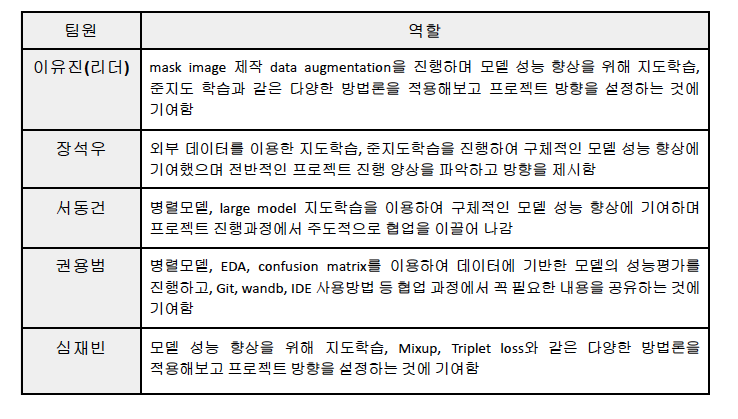
2. 프로젝트 팀 구성 및 역할
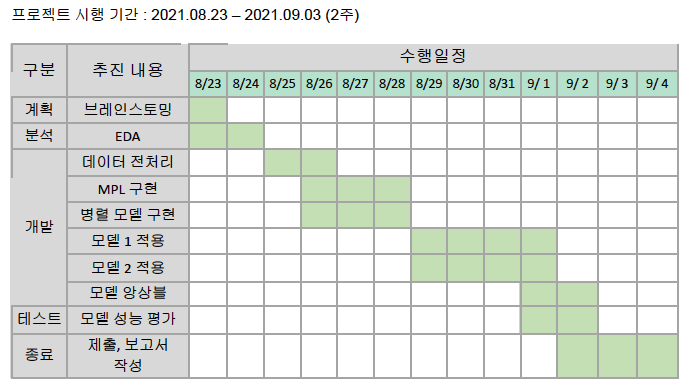
3. 프로젝트 수행 절차 및 방법
4. 프로젝트 수행 결과
1) 데이터 EDA와 브레인 스토밍
올바른 마스크 착용 유무를 판단하기 위해 인물의 얼굴을 중심으로 한 이미지 데이터들을 사용하여 본
대회를 진행하였습니다. 나이, 성별, 마스크 착용성을 종합하여 하나의 레이블로 표현이 됩니다. class
개수는 총 18개입니다.
지도 학습에 사용된 데이터는 총 2가지 입니다.
- 대회에서 제공한 기본 데이터 세트
- 2700명의 아시아인 남녀로 구성되어 있으며 나이는 20대부터 70대입니다.
- 각 인원 당 마스크 정착용 이미지 5장, 비정상 착용 1장, 미착용 1장으로 구성 - 500 GB of images with people wearing masks. Part 4 - (ref.1) (간략하게 외부 데이터 세트로 명명하겠습니다.)
- 7838명의 다인종 남녀로 구성되어 있으며 나이는 20대부터 80대입니다.
- 각 인원 당 마스크 정착용 1장, 비정상 착용 1장, 미착용 2장으로 구성
간략한 통계는 다음과 같습니다.
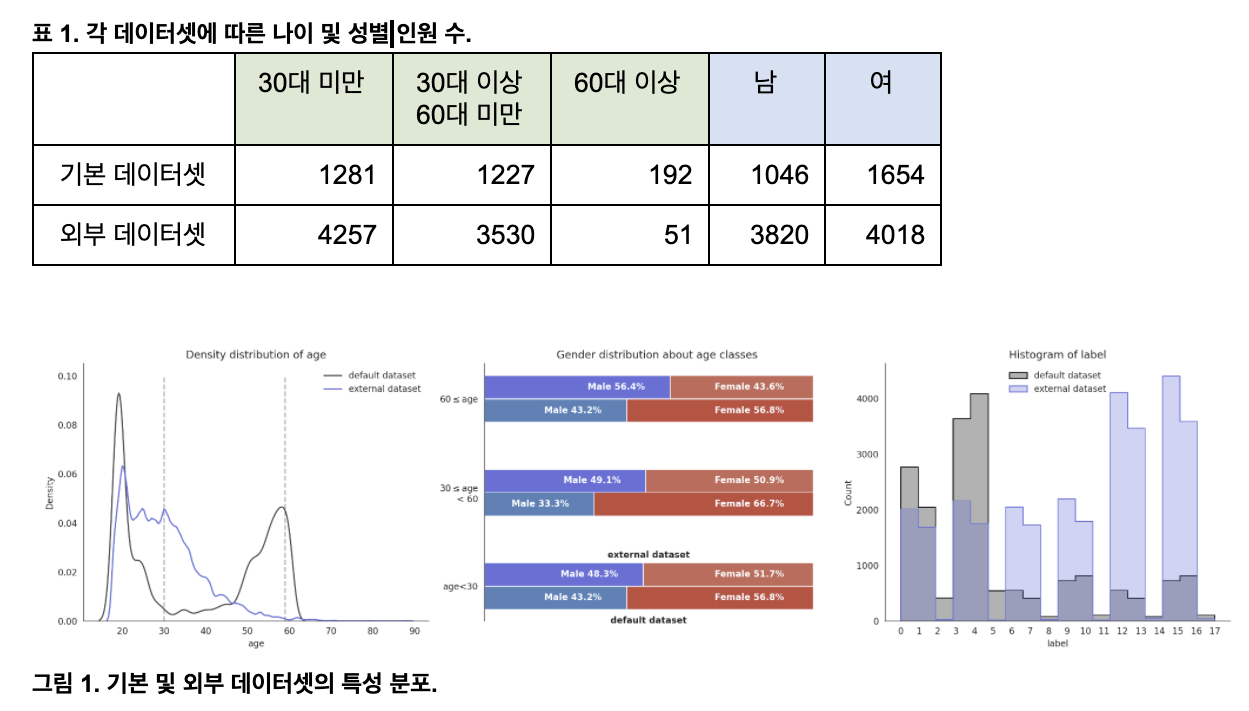
데이터 분포를 확인했을 때 나이가 60세 이상인 데이터가 다른 데이터에 비해 지나치게 적은 것을
확인했습니다. 이러한 데이터 불균형 문제를 해결하고자 2가지 방법을 채택했습니다.
(1) 외부 데이터셋에 대해 Meta Pseudo Labeling을 이용한 준 지도학습 방식 - (ref.5)
- Meta Pseudo Labeling : Label이 있는 데이터로 학습된 선생 모델로 Label이 없는
데이터를 라벨링한 후 학생 모델을 학습하고, 학생 모델의 성능을 이용하여 선생 모델을
다시 학습 - 구현의 난이도에 비해 Pretrained weight을 사용할 때 과적합(overfitting)에 취약하고,
학습에 소요되는 시간이 매우 커 이번 competition과는 부적합하다고 판단했습니다.
(2) 각 Task별로 데이터를 분류하여 학습하는 방식 (병렬 모델)
- 마스크, 성별, 나이에 대해 3개의 모델로 나누어 학습함으로써 데이터의 불균형 문제를
해결하려고 했습니다. - 병렬모델은 하나의 모델의 성능이 부족하면 전체 성능이 낮아지고, 병렬적으로 모델을
학습하기 때문에 사용해야 하는 pretrained 모델의 크기가 제한적입니다. 이는 모델의
표현력을 제한하여 최종 성능이 좋지 않다고 판단했습니다.
(3) 최종 선택 모델
- meta pseudo labeling보다 pretrained weight를 사용할 때 성능이 뛰어난 pseudo
labeling(4-2-1에 후술)을 사용하였습니다. - 병렬적으로 모델을 사용하는 것 대신, 18개 클래스를 충분히 구별할 수 있을 정도의
파라미터 개수를 가진 Big Model(vit_large, 4-2-2에 후술)을 사용하였습니다.
2) 데이터 전처리
- face detection으로 얼굴 부분만 crop하여 사용
- 외부 데이터셋 224X224로 Resize - (ref.2) ~ (ref.4)
3) 모델 설명
(1) 모델1. 준지도 학습(Pseudo Labeling)
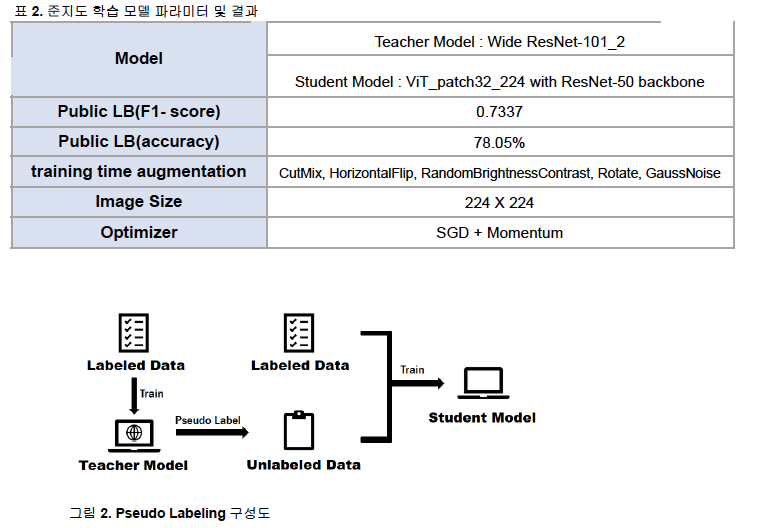
- 외부 데이터 셋을 활용하기 위한 방법으로 준지도 학습의 일종인 Pseudo Labeling
- 선생 모델: 레이블이 있는 데이터를 사용해 학습 후 레이블이 없는 데이터에 대한 가상 레이블 부여 [ Wide ResNet-101 ]
- 기존 데이터의 분포를 충분히 담아내기 위해 넉넉한 파라미터 개수를 갖는 모델
필수
- Competition의 특성상 다양한 시도를 깊은 모델들에 비해서 빠르게 시도 할 수 있다고 판단 - 학생 모델: 레이블이 있는 데이터와 가상의 레이블을 부여받은 데이터를 모두 학습 [ ViT_patch32_224 with ResNet-50 backbone ]
- 외부 데이터셋의 추가로 많아진 데이터를 최대한으로 활용하기 위해 파라미터가 많은 모델 선택
- 기존의 ViT 보다 학습 속도가 빠른 CNN backbone을 갖는 하이브리드 모델
(2) 모델 1 검증 및 개선
- 검증
- 나이대별로 사람을 뽑아 그 사람의 데이터를 모두 검증 데이터로 사용
- 모델이 validation 동안 학습에서 한 번도 본적 없는 인물에 대한 추론을 진행하기 때문에 evaluation 데이터와 유사한 환경 조성 가능
- 추가시도
- 학생 모델 학습 시 Label Smoothing을 통해 robustness 향상 시도, CutMix와 동시에 사용될 경우 task의 난이도 때문에 학습이 원활하지 않아 CutMix가 적용이 안되는 배치에만 Label Smoothing 적용
- 선생 모델은 주어진 데이터 셋의 분포에 맞는 pseudo label을 생성하기 위해 label smoothing 적용하지 않음
- 학생 모델의 레이블 데이터와 레이블이 없는 데이터로의 학습이 끝난 후 레이블 데이터로만 추가적으로 finetune 진행
(3) 모델 2. 지도 학습
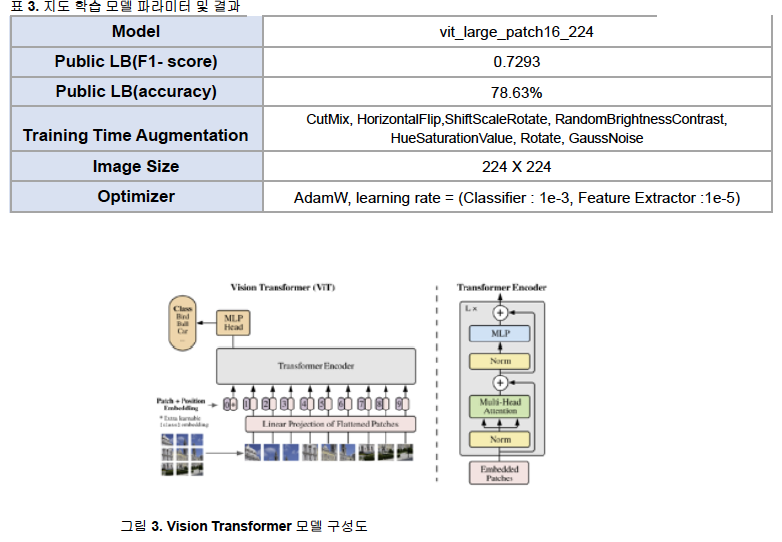
- ViT(Vision Transformer) : Transformer 기반의 Image classification model로, Transformer의 Encoder block을 통해 이미지를 분류하는 모델 - (ref. 6)
(4) 모델 2 검증 및 개선
- 모델 1과 동일
(5) 앙상블
- 가중치를 이용한 Soft Voting 사용
(6) 최종 시연 결과
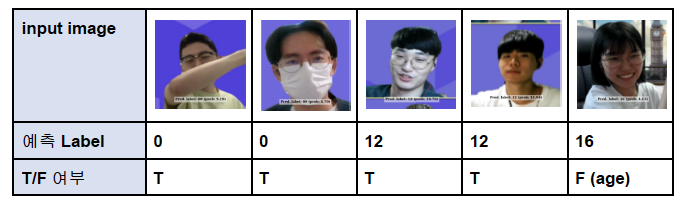
5. 자체 평가 의견
프로젝트를 진행하며 목적에 맞게 데이터를 처리 및 모델링 역량을 키울 수 있었습니다. 이론을 코드로 직접 구현해보며 팀원들과 공동성장을 할 수 있는 좋은 기회였습니다. 해당 모델을 좀 더 발전시킨다면 기존의 목표인 적은 인적자원으로 많은 사람의 마스크 착용 여부를 검사하는 것이 가능할 것입니다.
6. Reference
(1) 500 GB of images with people wearing masks. Part 4
https://www.kaggle.com/tapakah68/medical-masks-p4?select=images
(2) face-mask-lite-dataset https://www.kaggle.com/prasoonkottarathil/face-mask-lite-dataset
(3) age-recognition-dataset https://www.kaggle.com/rashikrahmanpritom/age-recognition-dataset
(4) face-mask-detectormask-not-mask-incorrect-mask
https://www.kaggle.com/spandanpatnaik09/face-mask-detectormask-not-mask-incorrect-mask
(5) Meta Pseudo Labeling https://arxiv.org/pdf/2003.10580.pdf
(6) Vision Transformer https://arxiv.org/abs/2010.11929
2. 개인 회고글
1. Goal of this project
대회에 들어온 이상 팀원들과 1등이라는 목표를 공유하였다. 리더보드의 성적을 올리기 위해 노력하는 것이 곧 실력을 향상시키는 것과 같다고 생각했고 팀원들도 같은 생각을 가졌다. 우리 팀은 우선 EDA를 통해 데이터의 분포를 확인하는 것이 먼저였다. 밑에서 자세히 서술하겠지만 EDA를 한 뒤 정상적인 분류 모델 학습 방식으로는 진행이 어려울 것이라는 결론이 나왔다. 따라서 진행 방향을 다같이 하나의 모델의 파이프라인에 붙어서 진행하기 보단 각자 다양한 모델과 방법론을 테스트해보고 그 Insight를 공유하며 서로의 모델을 발전시키고 최종적으로 지표상 좋은 성능이 나온 모델과 방법론들을 적절히 앙상블하여 최종적으로 결과를 내기로 하였다. 어떤 방법이 좋고 나쁘다를 쉽게 정할 수 없지만, 팀원 모두 어느정도 인공지능에 대한 경험과 Insight가 있기 때문에 파이프라인 하나에 모두가 달라 붙는 것보단 이 방법이 성적을 내는 것과 스스로의 성장에 더 큰 도움이 될 것이라고 생각했다. 이제 대회를 통해 얻은 몇 가지 경험과 insight와 한계점 등을 알아보고자 한다.
2 . Parallel model vs Big model vs Small model
EDA를 통해서 데이터가 가장 큰 문제라는 점을 먼저 인지하였다. Mask 착용 상태 3개, 성별 2개, 나이 범위 3개로 총 18개의 클래스로 분류하는 Task인데 주어진 학습데이터의 Class Imbalance가 너무 극심하였다. 가장 많은 클래스의 데이터와 적은 클래스의 데이터가 약 40배 정도 차이가 나는 상황이었기 때문에 이 데이터 그대로 18개 클래스 분류 학습을 진행하는 것은 무리라는 판단을 하였다.
(1) Parallel model
따라서 팀에서 처음으로 Parallel model에 대한 아이디어를 제공했다. 각 카테고리인 Mask, Gender, Age 별로 모델이 분류를 하게 한 뒤 그 결과를 어떤 방식으로 합치는 것이다. 당시 생각했던 장점은 카테고리 별로 모델을 나누게 되면 기존 40배 정도의 클래스 별 데이터 차이가 최대 10배(Age 카테고리) 정도로 줄어든다. 이 자체만으로 상황이 개선되기 때문에 충분히 문제를 해결할 수 있을 것이라고 판단하였다. 이 아이디어를 머릿속에 기억한 채, 우선 모델을 코드로 구현하는 방법을 연습하는데 시간을 쓴 뒤 병렬 모델을 본격적으로 구현하기 시작했다.
처음에는 어떤 외부데이터셋 없이 학습을 진행시켰고 각 카테고리 별 모델을 각각 학습시킨 뒤 그 Prediction을 종합해서 해당하는 18개 클래스 중 하나로 최종 Prediction하는 방식을 사용했다. 이 과정에서 Mask와 Gender의 경우 굉장히 좋은 성능을 보였으나 Age가 문제였다. 여전히 Class Imbalance가 남아있었지만 병렬 모델의 코드 구현에 너무 집중하느라 어떤 추가적인 조치를 취할 생각을 전혀 하지 못했다. 사실 이전에 너무 좋은 데이터셋들만 가지고 대회를 진행해와서 그런지 이런 상황에서 어떤 방법론을 적용해야 하는지 잘 몰랐다. 대회가 끝나고 상위권 팀들의 솔루션 발표에서 그 분들은 병렬모델을 사용할 때 Label smoothing 같은 method 사용으로 이런 문제들을 해결했다고 한다. 하지만 나는 그저 돌리다보면 해결되겠지 라는 생각에 개선할 생각을 못했다. 같은 조 권용범 캠퍼님 역시 병렬모델을 돌리셨고 나보다 좋은 성능이 나오셔서 그 분의 모델을 활용하는 것에 그쳤다. 물론 내 나름의 방식대로 더 발전 시켰지만 사실 성능이 좋게 나오지 않았다. 제일 중요한 것이 Age 카테고리 모델에 대해서 집중적으로 개선시키기 위해 고려했어야 했는데 최종적인 결과에만 너무 집중을 하였던 점이 너무 아쉬웠다. 회고를 하면서도 당장 Label smoothing이나 decision boundary 수정 등 여러 방법론이 떠오르는데 이러한 경험을 바탕으로 후에 비슷한 Task를 만난다면 그때는 좋은 병렬모델을 만들어보고 싶다.
(2) Big model vs small model
아무튼 당시의 상황으로 돌아와 병렬모델을 포기한 시점이 대회 진행 6~7일차였다. 주말에 이런 저런 시도를 하다가 결국 생각난 것이 큰 모델로 18개의 클래스를 바로 분류 해보고 싶다는 것이었다. 사실 학습데이터가 18900장 뿐이었고 이 적은 데이터로 큰 모델을 사용하면 overfitting이 일어날 것이라고 생각해서 팀원 모두 기피하던 아이디어였다. 하지만 병렬모델을 사용하기 전에 Small model로 해보면서 성능이 잘 안 나오기도 했고, 주말 동안 이유진 캠퍼님이 만들어준 외부데이터셋의 이미지에 마스크를 붙여 약 1만장의 추가 데이터를 얻게 되어 이를 바탕으로 새로운 마음으로 도전해보기로 하였다. 쭉 집중해왔던 ViT 모델을 large 버전으로 사용하였고 결과적으로는 리더보드를 여러차례 갱신하였고, 심지어 같은 조 장석우 캠퍼님이 진행하던 준지도학습 모델과의 앙상블로 리더보드 1등을 찍기도 하였다. 또 기본 18900장의 데이터만 학습시킨 모델과 최고 성능을 낸 모델을 앙상블하여 팀 최고기록을 만들었다. 스스로 뿌듯하였지만 사실 어떤 Insight를 통해 내린 판단과 그에 따른 결과는 아니었기에 엄청 만족스럽진 않았던 것 같다. 현재 가진 idea는 big model이 파라미터수가 많아 과적합에 예민하지만 feature extract 부분에서 더 디테일한 표현이 가능할 것이고, 우리가 가진 이미지가 서로 큰 차이가 없기 때문에 미세한 부분에서 클래스를 분류하기에 좋았던 것 같다. 일종의 Trade-off 였지만 남은 대회기간동안 그 overfitting을 잡기 위해 다양한 방법을 적용하였지만 결국 손을 대지 않은 것이 가장 성능이 좋았다. 아무래도 big model의 overfitting을 잡는 것이 쉬운 task는 아니다.
발표를 보니 다른 조는 small model이 더 성능이 잘 나왔다고 한다. 아무래도 small model이 그냥 돌리기에 성능이 더 안 나올 수는 있어도 Optimization과 Generalization에서 성능 개선이 더 쉽기 때문에 결국 더 좋은 결과를 얻을 수 있지 않았나 싶다.
3 . New point learned about Optimization and Generalization
가장 첫 번째로 Class weight loss이다. 이유진 캠퍼님께 배운 내용인데, Class Imbalance 때문에 일부 클래스만 학습이 되는 것을 완화 하기 위해 CrossEntropyLoss에서 각 클래스의 비율에 따라 weight를 줘 적은 데이터를 가진 클래스일 수록 높은 loss를 줘서 학습을 촉진시키는 방법이라고 할 수 있다.
두 번째로 learning rate와 overfitting 간의 관계이다. 정확히 얘기하면 배운 점이 아니라 완전히 잘못 생각한 부분이다. 대체 왜 learning rate를 낮게하면 overfitting에 도달하기 전에 최적해를 찾아낼 것이라는 잘못된 생각을 했는지 모르겠다. 실제로는 낮은 learning rate는 overfitting이 일어나게 하는 큰 원인이다. 더 바보(?)같은 점은 대회 마감 1~2일전 overfitting을 잡아보겠다고 learning rate scheduler까지 사용하였는데, big model이다보니 1~2 에폭 후에 바로 overfitting이 일어나 최대한 이를 delay 시키기 위해 매 에폭마다 learning rate를 감소시키는 StepLR을 사용하였는데 방법 자체가 잘못되었다고 생각한다. 가장 crucial하게 얻은 insight이자 다시는 반복해서는 안될 실수라고 생각한다.
세 번째로 Pretrained model freeze이다. 이전에 Pretrained model을 사용해 본 경험이 없었다. 그래서 Pretrained model을 사용할 때 어떻게 사용해야 하며 학습된 파라미터를 어떻게 유지해야하는지에 대한 지식이 없었다. 강의와 조원들의 조언을 통해 freeze라는 개념을 알게 되었고, 또 유진님을 통해 layer를 선택하여 freeze하는 것을 코드에서 조절할 수 있다는 것도 알게 되었다. 이 방법을 통해 그 정도를 조절해가며 성능을 향상시키는데 큰 도움을 받았다.
4. Conclusion
이번 프로젝트에서 수많은 삽질과 수많은 배움을 통해 모델을 개선시키는 많은 방법들을 배운 것 같다. 비록 내가 선택한 NLP도메인은 아니었던 대회였지만 그럼에도 불구하고 전반적으로 쓰일 수 있는 딥러닝 기법을 확실히 익히는데 큰 도움이 되었다.
프로젝트 코드 링크 : https://github.com/donggunseo/image-classification-level1-07
