지난 2021/9/28 ~ 2021/10/7 까지 약 2주의 기간동안 KLUE 데이터셋을 활용한 NLP 관계 추출 Task를 진행했다. 본 글은 해당 프로젝트의 레포트 및 개인 회고글의 내용을 담고 있다.
1. Team report
(1) 프로젝트 개요
KLUE RE Dataset으로 주어진 문장의 지정된 두 Entity의 관계를 추출, 분류하는 Task이다.
(2) 프로젝트 팀 구성 및 역할
(3) 프로젝트 수행
(1) EDA and preprocessing
주어진 KLUE Relation Extraction 데이터셋은 Train 32470개, Test 7765개로 이루어져 있으며 각 데이터는 Sentence, Subject Entity 정보, Object Entity 정보, Relation Label, Source로 구성되어있다. 각 Data의 Entity Column에는 해당 Entity Word와 문장 내 Index 위치, Entity Type 정보를 포함하고 있다. Entity Type은 단어의 개체명을 의미하며 이 Dataset에는 PER(사람), ORG(조직), DAT(시간), LOC(장소), POH(기타 표현), NOH(기타 수량 표현) 총 6가지 Type이 존재한다. 이 중 Subject Entity 단어는 PER과 ORG Type 단어만 쓰이며 Object Entity 단어는 모든 6가지 Type의 단어가 사용된다.
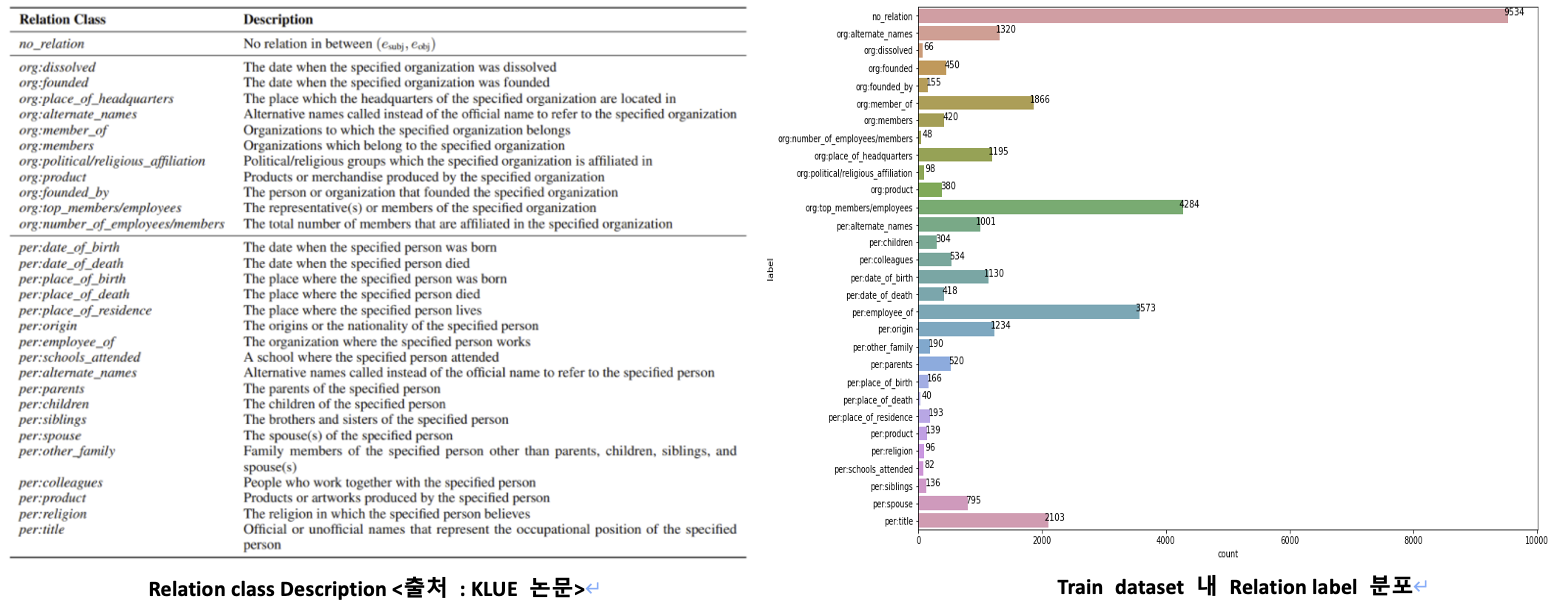
Relation에는 총 30가지 Class가 존재하며 그래프를 통해 확인할 수 있듯이 Data의 Class Imbalance가 극심하다. 또한 리더보드의 순위를 결정하는 Metric인 Micro F1 Score가 no_relation class를 제외한 나머지 Class 대해서만 F1 Score를 계산하는 것이기 때문에 일반적인 Classification Task Approach로는 문제를 잘 해결할 수 없다고 판단하였다.
전처리 과정에서는 Entity Word가 무조건 한 단어로만 구성되지 않는 것을 발견하였다. 또한 Entity Word 안에 ‘ , ’ , ‘ : ’ 가 포함되어 있는 경우도 있었다. 따라서 각 Entity Column의 Index 정보를 추출하여 Entity Word(Phrase) 전체를 뽑아내고 Entity Type도 동시에 저장하는 전처리를 진행하였다. 이 정보들은 추후 Input Format을 구성하고 Data Augmentation을 진행하는데 사용된다.
(2) Input Format
Typed Entity Marker with Punctuation : Special Token이나 Embedding Layer를 추가하지 않고 Entity의 위치와 Type을 표시하기 위한 방법으로 특수기호들을 이용해 문장의 형태를 바꿔 모델의 Input으로 사용했다.
Before) 이순신은 조선 시대 중기 무신이다
After) @ PER 이순신 @ 은 조선 시대 중기 # ^ POH ^ 무신 #이다
Add Query : Subject Entity와 Object Entity의 관계를 QA와 비슷한 형식으로 추가해주었다.
Example) @PER이순신@과 #^POH^무신#의 관계 [SEP] @ PER 이순신 @ 은 조선 시대
중기 # ^ POH ^ 무신 #이다 [SEP]
(3) Augmentation
Subject & Object Entity Random Masking : Subject Entity나 Object Entity를 Masking하게 되면 모델이 학습 시 주변 문맥에 더욱 집중할 수 있고, 모르는 단어가 Entity로 들어오는 경우에 더욱 잘 대처할 수 있을 것이라고 가정해 시도하였다. 50% 확률로 Fold내의 Train Data 중 Entity Masking 후보를 정한 후 다시 50%의 확률로 Subject를 가릴 것인지 Object를 가릴 것인지 정하는 방법을 이용하였다.
Before) @ PER 이순신 @ 은 조선 시대 중기 # ^ POH ^ 무신 #이다
After Subject Entity Masking) @ PER [MASK] @ 은 조선 시대 중기 # ^ POH ^ 무신 #이다
After Object Entity Masking) @ PER 이순신 @ 은 조선 시대 중기 # ^ POH ^ [MASK] #이다
AEDA: 문장 부호( . / , / ! / ? / ; / : )를 Okt 형태소 분석기 기준으로 토크나이징한 결과에 문장의 길이마다 다른 확률로 삽입하였다. 기존 train 문장에 AEDA로 생성한 한문장을 추가하여 문장을 두배로 늘려서 학습을 시켰다.
Before) @ PER 이순신 @ 은 조선시대 중기 # ^ POH ^ 무신 #이다
After ) ! @ PER 이순신 @ 은 조선시대 : 중기 # ^ POH ^ 무신 # ?이다
Random Delete : Text Data Augmentation 중 Easy Data Augmentation인 EDA에서 제시한 방법에서 Random Delete를 사용했다. 이 기법을 이용해서 노이즈를 가진 데이터들을 생성해 모델의 일반화에 도움을 줄 것이라고 가정해 시도하였다. Random Delete는 30%의 확률로 문장 안에서 Subject Entity와 Object Entity를 제외한 단어들 중 1개를 랜덤으로 삭제한다.
Before) 이순신은 조선 시대 중기의 무신이다.
After) 이순신은 조선 중기의 무신이다.
Entity swap: “Subject, Object를 서로 바꿔도 문제없는 라벨”, “Subject, Object를 바꾸면 라벨을 바꿔야 하는 경우”, “Subject, Object 한쪽 방향만 바꿔야 하는 경우”의 경우에 대한 Swap을 기존 Data에 추가했다.
ex) < no_relation label >
Before) 〈Something〉는 #^PER^조지 해리슨#이 쓰고 @ORG비틀즈@가 1969년 앨범 《Abbey Road 》에 담은 노래다.
After) 〈Something〉는 @PER조지 해리슨@이 쓰고 #^ORG^비틀즈#가 1969년 앨범 《Abbey Road》에 담은 노래다.
(4) Model Architecture
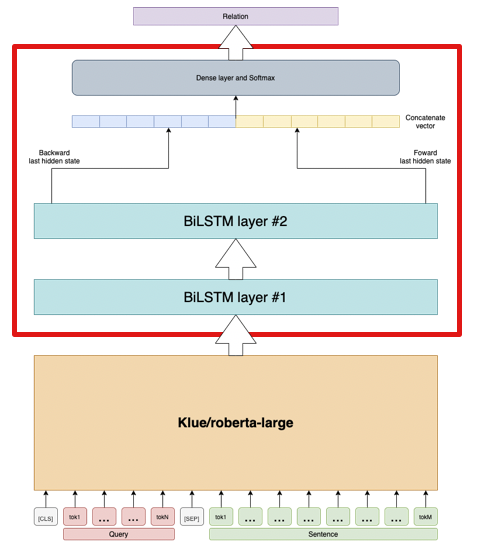
Query + Sentence 형식의 Input Sequence를 Klue/roberta-large 모델에 Feed하여 출력된 모든 Output을 BiLSTM Layer에 Feed한다. Top Layer에서 출력된 Forward, Backward Last Hidden State Vector를 Concatenate하여 Dense layer와 Softmax 연산을 거쳐 최종 Entity Relation을 Classify하게 된다.
- Loss Function : Label Smoothing Loss
- Optimizer : AdamW Optimizer
- Scheduler : Warmup and Linear Decay
(5) Ensemble
- Stratified K-Fold & OOF(Out-of-Fold) Prediction:
레이블 분포가 불균형함을 EDA로 확인하여 원본 데이터와 유사한 분포를 Train, Val Set에서도 유지하기 위해 Stratified K-Fold를 채택했다. 훈련 후 OOF Prediction으로 모델을 평가했다. - Soft voting
4가지 Augmentation을 각각 적용한 모델 4개와 적용하지 않은 기본 모델 1개를 각각 K-fold Ensemble한 후 0.4, 0.15, 0.15, 0.15, 0.15 의 Weight로 Soft Voting Ensemble하였다.
(4) 자체 평가 의견(프로젝트 소감 및 느낀점)
팀원 모두가 각자 하고자 하는 Method와 Approach들을 주도적으로 실험하고 결과를 공유하며 협업과정에서 적극적인 업무분담의 자세를 보여 좋은 결과를 얻었다. 다만 아이디어를 논의하고 결정하는 단계에서 시간을 많이 소요했고 제시된 방법론들의 Develop를 다양하게, 깊게 진행하지 못한 점에서 아쉬움을 느꼈다. 협의 과정과 결과를 공유하는 것에 미숙해 기록을 제대로 남기지 못한 점도 아쉬웠다. 이러한 부분을 다음 MRC 프로젝트에서는 보완하고자 한다.
2. 개인 회고글
(1) Pretrained Model and My Model
Dataset이 한글로 이루어져 있기 때문에 KLUE로 Pretraining된 “Klue/Roberta-large” 모델을
Huggingface에서 가져와 사용하였다. “BERT”가 기반이 된 “Roberta” 모델은 Language Modeling
Objective로 Pretraining되어 언어적 정보를 충분히 Capture하여 Downstream task를 수행할 수 있다. 여기서 나아가 Huggingface에서는 Pretrained Model을 Downstream task에 맞게 더 구체적인 모델 구조까지 제공하는 Tool을 가지고 있다. 예를 들어 단일 문장 분류 Task라면 “AutoModelforSequenceClassifiacation” 이라는 코드 한 줄을 통해 Backbone Model에 Classify dense layer가 추가된 모델을 쉽게 불러올 수 있는 것이다. 하지만 직접 모델 구조를 Custom하려면 이 Tool을 쓰지 않고 “AutoModel” 로만 Backbone model을 불러와 추가적으로 layer를 쌓아야 한다.
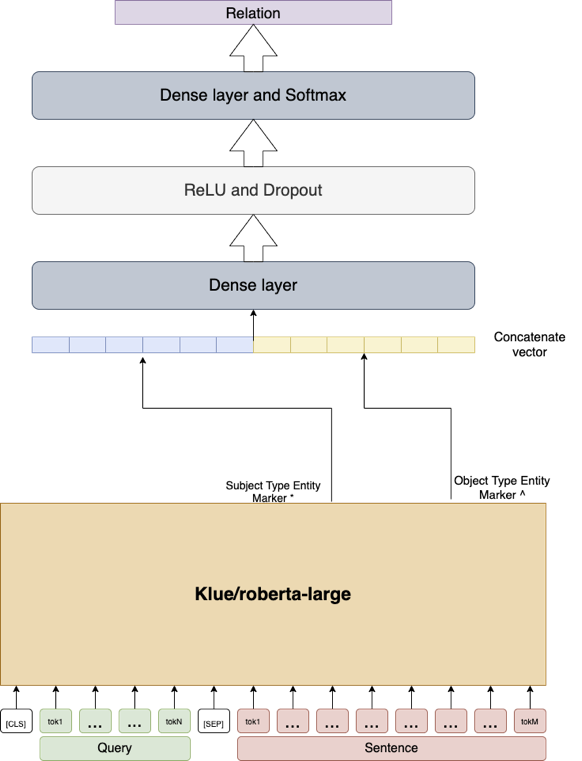
나는 우선 “An improved baseline for sentence-level relation extraction(2021)” 논문에서 정의한 RE Model(위 그림)을 구현하였다. Input Sequence 속 각 Subject, Object Type Entity Marker Punctuation 기호 Token이 Roberta를 통해 나온 출력값을 뽑아 Concatenate 하여 두 개의 linear layer를 통해 Relation을 분류한다. 비록 LSTM을 사용한 팀의 최고 성능 모델 대비 F1이 1점 정도 낮아 사용하지 못했지만 Huggingface 사용법을 잘 알고 익히게 된 좋은 계기였다. 특히 Huggingface에서 Train과 Evaluation, Backpropagation 등 모델 학습을 위한 모든 과정을 클래스로 제공하는 Trainer 클래스를 사용하였는데, loss function이나 optimizer, Lr scheduler 등을 Customizing 하기 위해서 Trainer 클래스를 상속하여 새로운 클래스를 만들어 사용해야 했는데 이를 위해 Huggingface Github를 열심히 뒤졌다. 이러한 과정은 이후 프로젝트와 더 나아가 개인 연구의 진행에도 큰 도움이 될 것이다.
(2) Is that really Co-Work(협업)?
직접 팀원을 찾아 구성하고, 남은 모든 부스트캠프 과정을 함께 할 팀과 맞이한 첫 대회였고 시작의 틀을 잘 잡고 싶은 마음이었다. 협업이라는 과정은 서로의 결과를 기록하고 공유하며 이를 바탕으로 다른 Task를 수행하다가도 기록만 봤을 때 쉽게 Workflow를 이해할 수 있도록 하는 것이다. 거기서 나아가 누군가의 Work에 붙어 Develop에 참여하는 것도 쉽도록 하는 것 역시 협업의 일부이다. 우리는 이 협업의 틀을 처음부터 완벽하게 하고 싶었던 것 같다.
대회 초반 기간(1주차 월요일 ~ 목요일)은 각자의 성장과 공부를 위해 개인별로 End-to-End 진행을 하기로 하였다. 그리고 금요일부터 각자가 만든 결과 중 잘 나온 것을 바탕으로 팀을 나눠 Develop 하기로 하였다. 초반에는 각자가 구현, 실험, 개발중인 것에 대해 공유가 잘 이뤄지지 않았다. Task 파악이 우선이라는 명목 아래 각자 개인적으로 실험하고 이를 구두로 공유하는 것이 대부분이었다. 그러다 보니 재현도 쉽지 않았고 좋은 method를 함께 Develop하는 것도 어려웠다. 간신히 Github Project를 통해 Issue card로 서로가 하고 있는 실험과 결과를 공유하지만 한 개인이 다음 과정으로 넘어가기위해 다른 사람의 진행 과정을 참고하는 정도까지는 못했던 것 같다. 또한 Issue card를 잘 남기더라도 Code를 제때 올리지 않거나 정해진 Convention(Code, Github Commit 등)이 없어 쉽게 가져다 쓰기에 어려움이 많았다. 또한 개인 실험의 진행과정을 Wandb 에서 확인하기로 하였으나 이 역시 정해진 Name Convention이 없어 학습 진행 그래프를 확인하려면 해당 팀원에게 일일이 그래프 이름을 물어봐야 하는 문제도 있었다.
후반에는 Model 팀과 Data 팀으로 인원을 나눠 Develop에 힘쓰기로 하였다. Model 팀에서는 최종 후보로 올라온 세 가지 모델을 개발한 세 명이 각자의 모델을 개선하기 위한 최종 method들을 실험해보며 결정하는 업무를 맡았고 Data 팀은 각자 Data Augmentation method를 개발하는 업무를 맡았다. 가장 큰 문제는 하나의 업무를 한 명이 맡아서 진행하다 보니 실수를 하더라도 이를 진행과정에서 Catch & Fix 할 사람이 없었다는 것이다. 또, 하나의 approach를 혼자 생각하니 Develop할 다양한 아이디어를 생각하지 못했다는 점이었다. 비록 다양한 아이디어를 효율적으로 단기간에 구체화할 수 있었지만 전반적으로 성능을 끌어올리지는 못했다는 점이 이번 대회에서 팀의 협업이 잘 안되었음을 증명해주는 것이었다고 생각한다.
추후 대회에서 협업을 개선하기 위해서 다음과 같은 방안을 생각했다. 우선 Issue card, Commit, Wandb 등의 여러 기록 공유에 있어 정해진 Template과 Convention을 이전의 경험들을 바탕으로 명확히 정해 다른 팀원의 실험을 쉽게 확인하고 점검할 수 있도록 해야한다. 두 번째로 각자 End-to-End를 경험해보는 기간을 줄이는 대신, Model이나 Data처럼 큰 범주로 Task를 쪼개는 것 이 아니라 아주 작은 Task로 쪼개면서 단기간에 Task를 마무리하고 이를 Develop하는 방식으로 진행하는 것이 더 효율적인 협업이 될 것이라고 판단했다. 그리고 Task마다 무조건 두 명 이상이 함께 작업하여 실수를 줄이고 Insight를 더 확고하게 얻는 것이 중요하다고 판단했다. 예를 들어 대회 초반에는 EDA, Baseline Code 파악, Task Trend 파악 정도로 Task를 나누고 단기간에 마무리한 뒤 EDA는 Data Preprocessing, Baseline Code 파악은 Baseline Code 추상화 작업, Task Trend 파악은 최신 논문 구현 등으로 Task를 이어나가는 것이다. Task마다 주어지는 기간이 짧기 때문에 양이 많지 않아 충분히 과정과 결과를 잘 공유한다면 경험해보지 않더라도 쉽게 이해할 수 있고 네트워크 조직처럼 다른 Task로 넘어가기도 어렵지 않아 End-to-End를 혼자 진행하는 것보다 빠르고 효율적으로 전체 과정을 이해할 수 있을 것이다. MRC Project는 4주라는 긴 기간 동안 진행되기 때문에 Workflow를 잘 계획해야 하며 제시한 방안들을 팀원들과 논의해 볼 생각이다.
(3) Is F1 really work for our task?
Best Model을 선정함에 있어 리더보드의 지표가 되는 f1 score를 metric으로 사용하였다. 이는 또한 모델이 Overfitting되기 전 학습을 중단하는 “EarlyStopping”의 지표로 사용하였다. 하지만 두 가지 문제가 있었는데, 먼저 Evaluation loss는 유지되거나 증가하는 반면에 Train loss가 감소하는 전형적인 Overfitting이 발생함에도 불구하고 F1 score가 오르는 현상을 꾸준히 확인할 수 있었다. Validation Set을 Stratify Kfold로 분포에 맞춰 다양하게 구성했음에도 불구하고 이 현상은 어떤 모 델을 쓰던, 어떤 Augmentation을 사용하던 동일하게 확인할 수 있었다. 이는 EDA를 통해 확인했던 문제와 연관되는데, 총 32470개의 data 중 같은 문장을 사용하는 데이터가 약 4000개 쌍 정도 확인되었다. 따라서 문장이 다수 겹치기 때문에 비록 그 안에서 Entity가 다를지라도 비슷한 데이터로 보일 것이라고 판단된다. 이는 곧 모델이 학습하지 않은 데이터로 Evaluate 해야하는 Validation stage 특성과 맞지 않았다고 판단된다. 또한 리더보드의 지표가 되는 f1 score가 모델이 no_relation 데이터를 no_relation이라고 맞춘 데이터들을 제외하고 계산되기 때문에 Overfitting을 Detect하기 알맞은 지표였다고 보기 어려웠다.
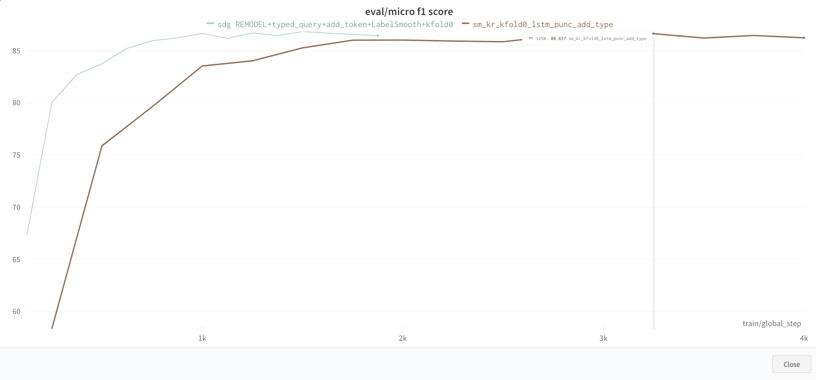
두 번째로, 어떤 모델을 쓰던 어떤 Augmentation을 사용하던 F1 score의 대소비교, 경향비교가 불가능했다는 것이다. 매우 비슷했기 때문이다. 위 그래프에서 볼 수 있듯이 Gradient accumulation 때문에 그래프 길이만 다르다 뿐이지 F1 score 값 자체에는 유의미한 비교가 불가능했다. 심지어 F1 score가 87일 때도 리더보드 제출에는 더 낮은 값이 나온 적이 있었다. 이로 인해 제출 전까지 어떤 approach가 더 좋은지를 비교할 수 없어 검증에 애를 먹었던 것 같다. 이에 대한 이유는 정확히 알 수는 없지만 위의 이유와 연결되어 Overfitting을 정확히 Detect 하지 못해 비교 역시 불가능한 것으로 판단하였다.
(4) Conclusion
이전에 연구를 진행하던 모든 과정을 혼자 했었기 때문에 이번 협업이 특히 어려웠고 공유가 잘 안되었던 것 같다. 다음 프로젝트에선 이 경험들을 바탕으로 더 좋은 결과와 좋은 과정을 만들고 싶다.
