논문 출처 : https://arxiv.org/abs/1802.05365
참고 자료 : https://jalammar.github.io/illustrated-bert/
(모델을 설명하기 위한 표와 그림은 논문과 참고 자료에서 가져왔음을 밝힘)
ELMo는 2018년 발표된 논문으로 Pretraining을 Language Model로 진행하는 approach를 대중적으로 만든 Method이다. 블로그를 통해 이미 GPT-1이나 BERT 등 Fine-tuning의 approaches를 소개했었고 실제로 이 방법이 현재로선 더 major한 방법이었지만 이 당시만해도 ELMo가 주도하는 Feature-based 방법 역시 주요했다는 점에서 그 흐름을 쫓기 위해 ELMo 논문을 리뷰하는 것이 나쁜 선택은 아니라고 생각한다.
Deep contextualized word representations
1. Introduction
(여러번 같은 내용이 나와 겹치지만) Word2Vec, GloVe등의 Pre-trained word represenation, 혹은 우리가 Pre-trained word embedding 이라고 부르는 이 친구들은 NLP의 여러 task에 있어 성능 향상에 큰 기여를 하였다. 하지만 더 높은 수준의 representation을 얻는 것은 여전히 어려웠다고 한다. 더 높은 수준이란 syntatic, semantic 한 정보는 물론이고 linguistic context(문서, 문장 내에서 단어의 의미 등) 정보들 전체를 담을 수 있는 수준을 의미한다. 이를 해결하기 위해 저자는 Deep contextualized word representation을 얻으려는 시도를 한 것이다.
기존의 Word embedding은 문장 속 Word 혹은 token 마다 임베딩을 독립적으로 가져오는 방식이었다. 하지만 ELMo는 모델에 문장 전체를 input으로 주어 각각의 token에 대한 임베딩을 얻는 방식이다. 이것이 가지는 의미는 어떤 task에 적용하던 여러 token들이 문장 안에서 갖는 contextual한 정보를 임베딩에 충분히 반영하게 한다는 것으로 더 높은 수준의 정보를 임베딩에 담을 수 있는 훌륭한 방법이다.
이 방법이 처음 제시된 것은 아니다. 동일한 저자가 2017년 제시한 방법이나 CoVe에서 제시된 방법도 비슷했으나 큰 차이가 하나 있다. 바로 ELMo는 각 LSTM Layer에서 나오는 모든 출력들에 대한 linear comibination으로 최종 Embedding을 완성한다는 것이다. 기존에는 맨 위 LSTM layer의 출력으로만 만들었고, 그렇기에 ELMo에게 Deep이라는 명칭이 붙은 것이다 (참고로 ELMo는 LSTM을 2층만 쌓아서 쓴다. 모델 layer가 깊게 쌓여서가 아니다). 이렇게 모든 layer의 출력을 합치는 방식을 논문에서는 Combining inner states라고 표현하고 있으며 이 방법으로 매우 수준 높은 단어 임베딩(rich word representation)을 얻을 수 있다고 한다.
저자는 자체적인 검증을 통해 재밌는 사실을 밝혀냈다고 한다. LSTM의 위쪽 층(higher-level)에서 얻는 states들은 단어의 context-dependent한 의미들에 대한 정보를 많이 담고 있으며 아래쪽 층(lower-level)에서 얻는 states들은 Syntax적인 정보를 많이 담고 있었다고 한다. 전자는 supervised word sense disambiguation task(중의어 구별) 등에 사용될 수 있고, 후자는 POS tagging (품사 태깅) task에 사용될 수 있다. 따라서 이를 적절히 linear combination하는 것이 여러 task에 잘 대응할 수 있는 좋은 접근이라고 할 수 있다.
2. Related work
(1) Context-dependent representaion
Introduction에서도 언급했지만 Word2Vec이나 GloVe같은 Pretrained word vector를 통해 NLP의 여러 task들의 성능향상을 이루었지만 이들은 single context-independent representation, 즉 맥락과 무관한 독립적인 단어임베딩에 불과하다는 것이 한계였다.
이 단점을 극복하기 위해서 Subword 단위로 쪼개는 방법이나 단어 의미별로 다른 벡터를 만드는 방식이 사용되었다. ELMo 역시 Subword 방법의 일환인 Character Convolution을 사용한다.
또한 Context-dependent representation을 얻기 위한 시도도 있었다. Context2Vec라는 2016년에 발표된 이 방법은 biLSTM을 통해 pivot word에 대한 context 전체를 encode해서 벡터를 얻는 방식이었다. 또 CoVe나 저자의 이전 논문에서도 pivot word를 포함한 contextual representation을 얻는 방식을 진행하였으나 CoVe는 Machine Translation task를 통해 얻기 때문에 dataset size에서 한계가 있었다. Language Modeling을 사용하는 것이 따라서 훨씬 많은 텍스트를 학습할 수 있다는 장점을 가진 것이다.
(2) Different layer has different information
역시 Introduction에서 언급했지만 deep biRNN에서 각 layer마다 다른 정보를 줄 수 있음을 보여준 연구들이 있다. 예를 들어 deep LSTM의 아래 층 layer에서 syntactic supervision task를 학습시켜서 dependecy parsing 같은 더 높은 레벨의 task에 대한 성능을 올렸던 연구가 있었다. 또 Encoder-Decoder RNN model로 Machine Translation task를 학습시켰을 때. 2-layer LSTM Encoder의 첫 번째 layer에서 얻은 representation이 두 번째 layer에서 얻은 representation보다 POS tagging에 더 좋다는 것을 증명한 연구도 있었다. 마지막으로 Word context를 encoding하는 LSTM에서 가장 위 layer가 단어의 의미에 대한 정보를 잘 제공해준다는 연구도 있었다. 따라서 ELMo 역시 여러 task에 잘 대응하기 위해 모든 layer의 representation을 활용하고자 하는 것이다.
3. ELMo: Embeddings from Language Models
ELMo는 input sentence 전체를 통해 word representation을 얻는다. 먼저 Character convolution을 거친후 2-layer biLM을 통해 각 layer에서 나온 states에 대한 Linear function을 거쳐 최종적으로 단어 임베딩을 얻는 과정이다. 이 단어 임베딩을 가지고 downstream task를 진행하는 것이다. 자세히 하나하나 뜯어서 알아보자.
(1) Bidirectional language models
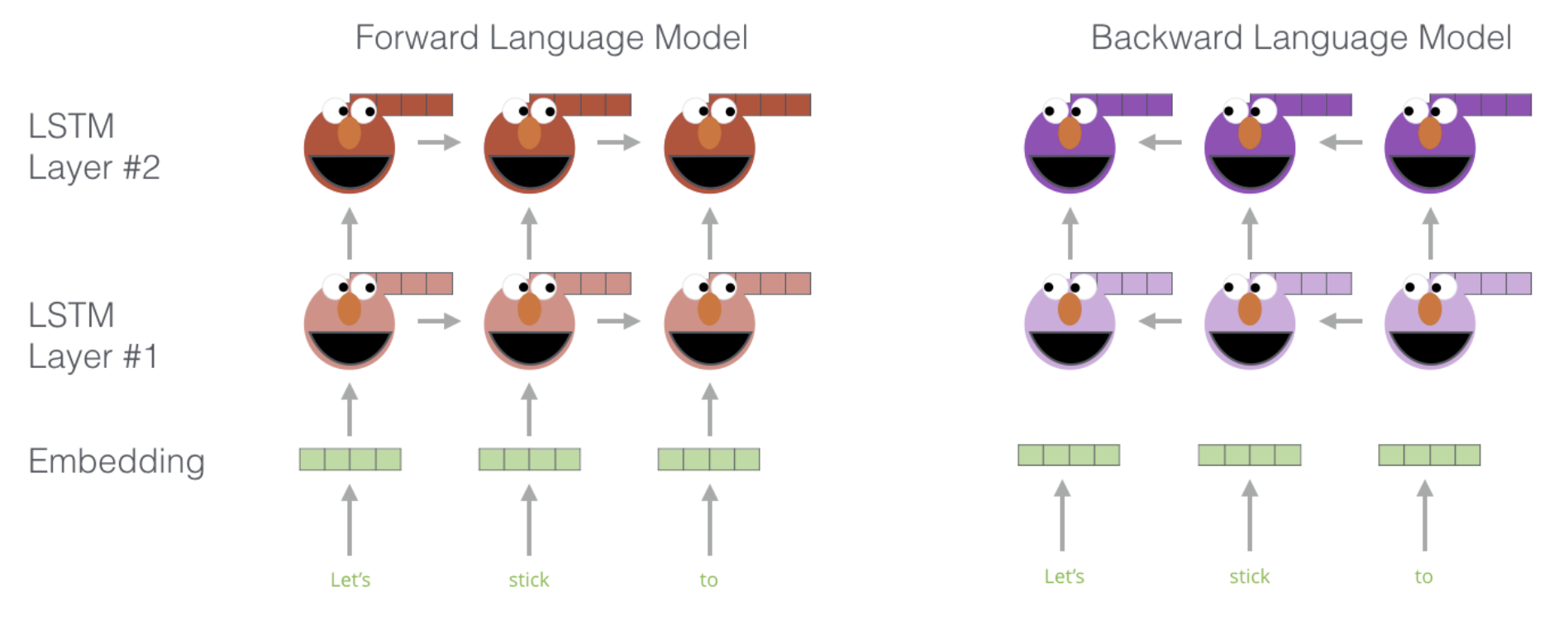
N개의 token으로 이루어진 Sequence 가 있다고 해보자. ELMo는 forward 방향 LSTM과 backward 방향 LSTM 두개를 동시에 학습한다. 먼저 Forward Language model에서는 다음과 같은 식을 통해 학습한다.
반면 Backward Language model에서는 다음과 같은 식을 통해 학습한다.
두 모델을 통해서 Forward LM의 states 을 얻게 되는데, 이때 은 각 token의 position을 의미하며 은 몇 번째 Layer인지를 의미한다. 당연히도 Language model이기 때문에 , 즉 마지막 출력 state를 통해 다음 단어를 Softmax 연산을 통해 Predict한다. 화살표는 Forward와 Backward를 의미한다.
그전에, 즉 LSTM으로 들어가기전에 각 token을 token embedding이나 ELMo처럼 Character Convolution을 통해 context-independent token representation 를 얻는다. 이 token representation들이 biLM의 input으로 들어가 context-dependent representation 을 얻는 것이다. 이 context-dependent와 context-independent를 모두 활용한다는 점이 중요하다(이건 다음 장에서 알게 된다).
이 biLM의 최종 목적식은 각 방향 LM의 Log-likelihood를 jointly하게 maximize하는 것이 목적으로 다음과 같다고 할 수 있다.
여기서 는 token representation을 위한 파라미터들이며 는 Softmax layer 파라미터이다. 저자의 이전 논문과 달리 개선된 점은 을 공유한다는 점이다.
(2) ELMo
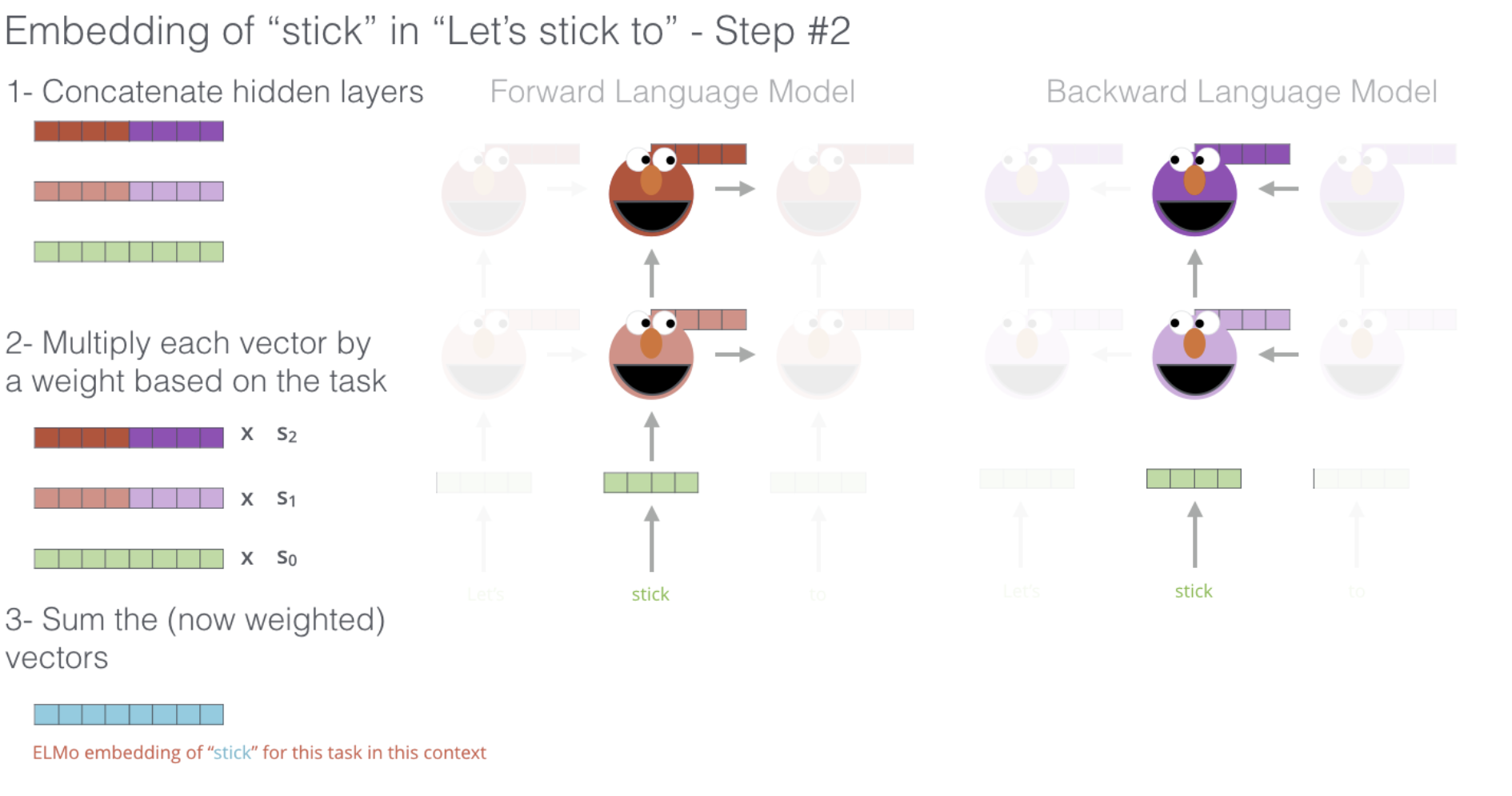
논문에서 ELMo는 task specific combination of the intermediate layer representations in biLM이라고 명시되어있다. 즉 각 층 layer의 states들에 대한 combination을 하되 task에 맞게 weighted sum하겠다는 것이다. 이는 앞에서 언급했듯이 각 layer마다 주요하게 capture하는 정보가 다르기 때문에 task에 맞는 정보 위주로 representation을 완성한다는 것이다.
-layer biLM을 통해서 얻은 어떤 token 에 대한 representation들 총 개(Layer L개 별 forward state 하나, backward 하나, token embedding 딱 한 개)의 representation을 모아서 라는 set을 정의하자. 이때 를 token layer에서 얻은 representation, 즉 라고 하고 , 즉 각 방향의 state들의 concatenation이라고 한다면 로 압축하여 정의할 수 있다.
이 를 weighted sum을 통해 하나의 벡터로 합쳐서 최종적으로 downstream task를 고려한 representation인 를 얻게 된다. 정확한 식은 다음과 같다.
이 때, 는 softmax-normalized weights 들이다. 각 layer의 states가 포함하는 정보의 결이 다르니 task에 맞게 어느 쪽을 중점적으로 받을 것인지를 결정하는 계수라고 생각할 수 있다. 이 값은 Hyperparameter로 Supervised task를 진행하면서 학습을 통해 업데이트 된다. 는 scalar 값으로 task에 맞게 벡터를 scaling하는 역할이다. 이는 biLM internal representations들의 distribution과 task specific representation의 distribution이 다르기 때문에 scaling을 통해서 맞춰주는 단계라는 것이다. 혹은 이 biLM internal representations들의 distribution을 맞춰주기 위해 layerNorm을 weighting(가중치 파라미터들과 곱해지는 단계)전에 적용하는 것이 도움이 될 때도 있었다고 한다.
(3) Using biLMs for supervised NLP tasks
Supervised NLP task에 적용하는 방법은 너무나도 쉽다. 우선 biLM을 freeze 시킨 후, task를 진행하는 과정에서 들어오는 input 텍스트 데이터 각 토큰에 대해 biLM을 거쳐 를 뽑아낸다. 이를 token representation(context-independent) 와 concatenate하여 의 형태를 input으로 Supervised task 모델(RNN)에 넣어주게 된다.
몇몇 Task(SNLI(문장 간 논리관계 유추), SQuAD(질의응답))의 경우에는 Supervised task 모델(RNN)의 출력에도 를 concatenate하고 predict를 위한 output layer의 파라미터를 다른 task보다 추가로 더 두는 이 방식이 더 좋은 성능을 보였다고 한다.
마지막으로 ELMo 모델에 dropout을 하며, regularization을 위해 loss에 biLM의 weights 에 대하여 를 더하는 방법도 적용했다고 한다. 이는 weight에 inductive bias를 부과해 모든 weights가 가능하면 biLM 전체 layer의 평균 weight에 가까이 있게 하기 위함이라고 한다. 일 수록 weighting function을 layer 전체에 대한 simple average function으로 만들어주고 (대부분 task에서 이 값을 적용) 일 수록 layer weight를 다양하게 만들어준다. 실제로 성능은 일때 대부분 더 높았다고 한다. 단 NER task에서는 큰 의미가 없었는데 이는 Supervised task dataset size가 작으면 값에 insensitive하기 때문이라고 한다.
(4) Pre-trained bidirectional language model architecture
이제 말로만 떠들었던 이 모델의 자세한 구조를 알아보자.
BiLSTM을 이용한 Language Modeling은 사실 그렇게 혁신적이진 않다. 하지만 저자는 ELMo의 pretraining 과정의 objective가 jointly 하게 양방향의 학습을 진행한다는 점에서 기존과 다름을 언급하였다. 또 LSTM의 layer간 residual connection도 추가하였다고 한다.
ELMo는 , 즉 2층 짜리 biLSTM을 사용하였으며 embedding, hidden states 등의 vector dimension은 512로 통일하였다. 논문에서 4096 units이라는 표현을 썼는데, 보통 LSTM에서 unit이란 단위는 블록 안에서의 states의 dimension을 의미한다. ELMo는 2층짜리 biLSTM이기 때문에 512-dimension의 hidden state와 cell state 2개의 한 쌍이 양방향이니까 총 2쌍, 2층이니까 층별로 1쌍씩 총 4쌍 있어서 512 * 8= 4096의 units을 매 time step마다 가지고 있다가 다음 step으로 넘겨주기 때문에 4096 이라는 숫자가 나오게 되는 것이다.
context insensitive type representation, 즉 context-independent token representation을 얻기 위해 ELMo는 2048 character n-gram convolutional filters에 두개의 highway layer를 사용한다고 한다. 2048의 의미는 한 개의 단어에 대해 CNN 연산을 거쳐 2048-dimension의 vector를 만들어낸다는 의미이다(이전의 Character CNN 관련 method를 그대로 가져온 것인데 추후 해당 논문들을 읽어보고 업데이트하겠다).
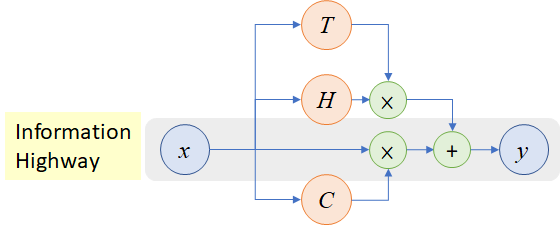
Highway layer는 위 그림을 따르는 layer로 마치 LSTM처럼 information flow에서 가져갈 정보와 버릴 정보의 조합을 weight로 적당히 조절하는 식의 layer이다. 식은 다음과 같다.
마지막에는 linear layer 하나를 통해 모든 단어 임베딩 벡터 dimension을 512로 맞춰준다.
4. 마무리
물론 지금은 Feature-based method가 추가적인 모델과 파라미터를 필요로 한다는 점에서 잘 쓰이지 않는 방법이지만 Pretraining approach에 대한 관심을 일으키기에 충분했다고 본다.
