논문 출처 : https://openai.com/blog/language-unsupervised/
1. Introduction
NLP의 다양한 task들은 거의 대부분 충분한 labeled data들을 요구하며 이를 통해 Supervised learning으로 해결해왔다. 그러나 이런 labeled data들은 항상 충분하지 않으며 task에 따라 부족한 경우가 더 많다. 그렇기 때문에 raw text를 통해 학습하는 것이 중요한 포인트로 인식되어가기 시작한 것이다. 즉, unlabeled data를 통해 Unsupervised learning으로 linguistic information을 최대한 얻고자 하는 것이다. 이 방법으로 얻은 text에 대한 representation으로 부족한 데이터의 Supervised learning도 쉽게 가능하게 할 수 있다는 것이 요지이다. 그 예시로 Word2Vec, Glove 같은 pretrained word Embedding을 활용하여 여러 NLP task에서 성능을 끌어올린 사례가 있다.
하지만 word-level 이상, 즉 문장 레벨이나 그 이상의 텍스트에 대한 정보를 unlabeled text로 부터 얻는 것은 두 가지 어려움이 존재한다.
먼저 첫 번째로, 어떤 optimization objective가 transfer하기 좋은 text representation을 학습할 수 있는지 확실하지 않다는 점이다. 이는 곧 Unsupervised learning을 위해 모델을 어떤 task로 학습시켜야 이를 Supervised task로 transfer 했을 때 좋을 지를 고민해야 한다는 말이다. 대표적으로 ELMO에서는 Language Model task를 통해, CoVe에서는 machine translation을 통해, 그리고 Discourse coherence(담화 응집성) task를 통해서 모델을 학습시키고 이를 transfer하는 연구가 진행된 바 있다.
두 번째로, 이렇게 겨우 학습시킨 representation을 어떻게 transfer해야할 지 확실하지 않다는 점이다. 현존하는 기법으로는 모델의 구조를 task에 맞게 변화시키는 방법과 복잡한 learning scheme 사용, 그리고 auxiliary learning objective를 사용하는 방법이 있고 이들을 적절히 합쳐서 사용하고 있다는 것이다.
이렇게 Unsupervised pretraining -> Supervised fine-tuning 하는 일명 Semi-supervised approach를 탐구하겠다는 것이 이 논문의 목적이라고 할 수 있다. 즉, universal representation을 배워서 이를 아주 조금의 변화만 주어 여러 Supervised한 target task에서 사용할 수 있게 하겠다는 것이 목적인 셈이다. 이 target task들은 꼭 Unlabeled text와 같은 domain일 필요는 없다. 정리하자면 다음과 같은 과정인 셈이다.
- Unlabeled data를 Language modeling objective를 통해 학습하여 모델의 초기 파라미터(initial parameter)를 학습
- 학습된 모델을 target task에 맞게 약간 조정하여 해당하는 Supervised objective에 맞게 조정
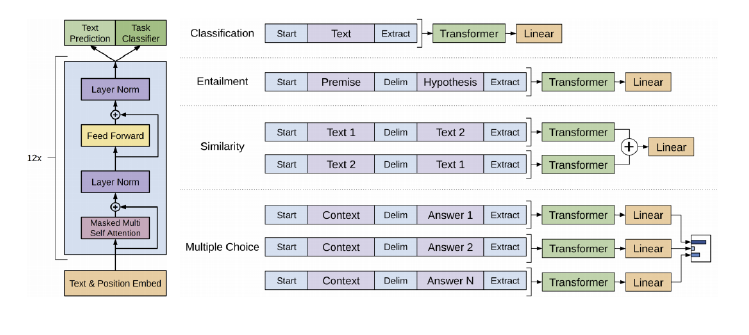
GPT는 기본적으로 Transformer의 Decoder를 모델 구조로 채택하고 있다. 기존의 Transformer Decoder는 Masked-Multi head attention -> Encoder-Decoder Multi head attention -> Feed Forward Network 로 이루어져 있었지만 가운데 Sub-layer를 제외한 이 Block을 더 쌓는 것으로 구성되었다. Transformer는 long-term dependency를 잘 잡아준다는 측면에서 robust한transfer performance를 보여줄 수 있다. GPT-1은 transfer 과정에서 task-specific하게 input을 조정하는 방식을 채택한다. 구체적으로는 task에 맞게 구별자(delimiter)를 사용하여 텍스트들을 single contiguous sequence로 만들어 input으로 사용한다는 것이다.
GPT는 Evaluation을 위해 NLI(Natural language Inference), QA, Semantic Similarity, text classification 네 가지 task에 대해 성능을 확인했고 성능을 대폭 상승시켰다는 것을 확인했다고 한다. 심지어 학습 중에 전혀 발견되지 않은 클래스나 분포의 데이터를 잘 예측하는 zero-shot의 성질도 pretrained 모델에서 확인할 수 있었다고 한다. 이를 통해 모델을 pretraing하는 과정에서 downstream task에 유용한 linguistic knowledge를 얻을 수 있음도 확인한 것이다.
2. Related Work
(1) Semi-supervised learning for NLP
앞에서 언급했듯이 unlabeled data를 학습하여 word-level representation을 얻어 supervised model에 사용하는 방식의 Semi-supervised learning 방법이 NLP에서 크게 주목을 받게 되었다. 그러나 이제는 단순히 word-level을 넘어서 higher-level semantic, 즉 Phrase-level, Sentence-level의 정보를 얻기 위한 방법론들이 계속 연구되어 온 것이다.
(2) Unsupervised pre-training
Unsupervised pretraining은 이런 semi-supervised learning의 special한 케이스라고 볼 수 있다. Supervised learning objective를 바꾸는 대신 처음부터 좋은 initialization point를 찾는 것이 목적이라고 할 수 있다. 즉, pretraining한 모델을 그대로 적용해도 여러 task들을 잘 수행할 수 있도록 universal하게 만들겠다는 것이 목적이다. 실제로 연구를 통해 이 Pretraining이 딥러닝 모델의 generalization 성능을 향상시키는 regularization scheme로 작용한다는 것도 밝혀졌다. 그리고 이 방법은 domain을 가리지 않고 다양한 task에서 성능 향상에 큰 도움이 되고 있다.
앞에서 언급했지만 GPT-1의 방식은 language modeling objective로 pretraining 후 supervised target task에 fine-tuning하는 방식이다. 이런 방식을 활용한 시도가 있었지만 LSTM을 활용하였고 이는 넓고 깊은 정보를 얻는데 제한이 되는 반면에 GPT-1은 Transformer를 사용하였기 때문에 더 깊은 정보를 얻을 수 있다는 것이 저자의 주장이다. 또한 깊은 정보는 곧 더 많은 task를 target task로 활용할 수 있음으로도 이어지는 것이다. 또 다른 방식으로는 Fine tuning이 아닌 Feature-based(BERT에서 이를 더 자세히 비교함) method인데, 즉 pretrained model로부터 얻은 hidden representation을 supervised target task에 추가적인 feature로 활용하는 방식이다. 대표적으로 ELMo가 이런 approach를 활용하고 있는데, 이는 더 많은 파라미터를 요구하게 된다. 반면 GPT-1에서는 모델 구조에서 아주 조금의 변화만 주어서 tranfer하는 것이 차이가 있다.
(3) Auxiliary training objectives
Auxiliary unsupervised training objectives를 supervised learning 단계에서 추가적으로 활용하는 것 역시 Semi-supervised learning의 한 방법론이다. 이미 여러 연구에서 language modeling 같은 task의 objective를 target task에 보조적으로 활용하여 성능 향상을 보인 사례가 있다. GPT-1 역시 Auxiliary objective를 사용하지만 저자는 이미 Unsupervised learning에서 충분히 학습이 되는 점을 다시 한번 강조하였다.
3. Framework
(1) Unsupervised pre-training
앞에서도 언급했듯이 Unsupervised pre-training에는 large corpus of text, 즉 아주 큰 데이터셋으로 standard language modeling objective를 사용한다. language modeling은 Corpus 에 대하여 다음과 같은 Likelihood 식을 최대화 하는 것을 목적으로 한다.
이때 는 context window size를 의미하고 는 모델의 파라미터들을 의미한다. 이 파라미터들은 SGD(Stochastic gradient descent)를 통해 학습된다.
모델의 구조는 그림에도 묘사되어있듯이 Transformer의 Decoder 구조를 거의 그대로 쓰고 있다. 앞에서 언급했지만 기존의 Decoder에서 Encoder와 연결된 Multi-head attention layer가 빠졌다. 또 Transformer에서는 Position 정보를 주기 위해 sinusoidal function을 사용하여 Positional Encoding을 하였지만 이 모델에서는 Positional Embedding을 사용하고 있다. 따라서 전체 input Embedding은 token embedding과 position embedding을 더하여 구성된다. 마지막으로 Language modeling을 위해 마지막 Decoder Block에서 출력된 hidden representation에 밑에서 사용했던 token embedding matrix과의 linear 연산 후 softmax연산을 진행하여 다음 단어를 predict하는 language model의 역할을 수행하게 된다.
(2) Supervised fine-tuning
이제 열심히 pretrain한 model을 가지고 supervised한 task를 해결해보자. 각각의 instance가 input tokens sequence 과 해당하는 label 로 구성된 labeled dataset 가 있다고 하자. 물론 task마다 이 의 format은 다르겠지만 당장은 이해를 쉽게 하기 위해 Classification하는 과정에서의 label이라고 편의상 가정하자. input sequence가 모델에 feed되고, 마지막 Decoder block의 hidden represenation (h_l^1, h_l^2, ... , h_l^m)의 마지막 element인 을 얻게된다. 이를 새롭게 만든 linear layer with parameter 에 feed한 뒤 Softmax를 통해 을 얻게 된다. 그러면 이 fine-tuning의 objective를 다음 식을 최대화하는 것으로 정의할 수 있다.
앞에서 언급했듯이 GPT-1은 Unsupervised learning의 objective 을 auxiliary learning objective로 사용한다. 라는 weight 값을 hyperparameter로 두어 최종 fine-tuning의 objective를 다음과 같이 정의한다.
auxiliary learning objective를 사용하는 것은 Supervised model의 generalization 성능을 높여주는 것은 물론 convergence를 가속화하는 것에도 장점이 있다.
주목해야 할 점은 fine-tuning에서 추가적으로 필요한 파라미터는 와 delimiter token에 대한 embedding 뿐이다.
(3) Task-specific input transformations
Classification같은 task는 위에서 설명한대로 하면 쉽게 fine-tuning 할 수 있다. 그러나 QA나 textual entailment같은 몇몇 task들은 요구하는 형식의 sentence들(Structured input)을 Input으로 가진다. GPT-1은 contiguous sequence로 학습되었기 때문에 문제 해결을 위해 이 input들을 약간 바꿔줘야 할 필요가 있다는 것이 요지이다.
기존에는 이런 문제들을 해결하기 위해 transfered된 representation만 이용해 task-specific architecture들을 새로 만들어 처음부터 학습시키는 Feature-based 방식을 활용했다. 하지만 이는 기존에 학습된 파라미터들을 전혀 사용하지 않고 새 task를 위해 추가적으로 많은 파라미터들을 학습시켜야한다는 단점이 있다. 따라서 GPT-1에서는 이런 structure input을 pretraining 할 때 사용했던 input format처럼 만들기 위해 ordered sequence로 바꿔서 사용하기로 하였다. 이렇게 하면 큰 변화 없이 학습된 모델을 그대로 task에 적용시켜 사용할 수 있다. 몇 가지 task를 예시로 어떻게 바꾸는지 자세히 알아보자(모든 시퀀스에 randomly initialized된 token인 start token <s>와 end token <e>을 넣는다.)
1) Textual entailment
전제 Premise p와 가정 Hyphothesis h 두 문장 간의 논리적 관계가 맞는지 확인하는 task이다. 따라서 input으로 [<s>, p, <delim>, h, <e>]을 넣어주게 된다.
2) Similarity
두 문장이 얼마나 유사성을 가지는지를 판단하는 task이다. 따라서 문장 사이의 순서가 없는 task이기 때문에 두 문장 a, b에 대해 [<s>, a, <delim>, b, <e>], [<s>, b, <delim>, a, <e>]를 각각 넣어주고 앞에서 언급한 를 각각 뽑아낸 뒤 더해서 linear layer에 넣어서 유사성을 측정하게 된다.
3) Question Answering and Commonsense Reasoning
이러한 task에는 세 가지 sequence가 주어진다. 본문이라고 부를 수 있는 context document z, question q, 그리고 가능한 answer의 집합인 가 주어지며 이를 통해 answer set의 각각의 answer에 대해 [<s>, z, q, <delim>, a_k, <e>]를 모델에 넣어줘서 을 뽑아내 여기에 softmax를 먹여서 어떤 답안이 가장 possible한지 측정하게 된다. 사실 QA는 answer set을 주고 그중에 고르는 객관식형태보단 answer를 시퀀스로 뽑아내는 주관식형태가 더 일반적이고 원하는 task인데 이는 BERT에서 해결한다.
4. Experiments
그림의 Decoder Block을 12개를 쌓았다. Transformer에서 표현한 은 768을 사용하고 head는 12개를 사용한다. Feed-forward Network의 가운데 inner dimension은 3072 값을 사용한다. Adam optimizer를 사용하며 learning rate는 처음 2000 updates까지는 0부터 최대 2.5e-4의 값까지 linear하게 증가하고 이 후에는 0까지 annealed 되는 cosine scheduler를 사용한다. 64 batch size로 100 에폭동안 mini-batch 학습을 하였으며 한 시퀀스당 512개의 token이 있도록 조정하였다. Weight initialization은 LayerNorm의 성능을 믿고 N(0,0.02)로 조정하였다. 또한 Byte-pair Encoding(BPE)을 사용하였으며 Weight decay를 위해 modified L2 regularization을 로 사용하였다. activation function으로 GELU를 사용하였으며 Dropout rate를 0.1로 사용한다. 그리고 학습된 position embedding을 사용한다. Pretraining 단계를 통해 얻은 Language modeling의 perplexity는 18.4 정도로 비교적 학습이 잘 되었다고 할 수 있다.
Fine tuning 단계에선 기본적으로 Pretraining과 같은 hyperparameter 값을 사용한다. task를 위해 추가하는 linear layer에 dropout을 추가하며 learning_rate 6.25e-5에 batch_size 32를 사용한다. Fine tuning 단계에선 3에폭의 학습만으로도 충분하다. 전체 training의 0.2%의 warmup으로 linear learning rate decay scheduler를 사용한다. 앞에서 언급한 Auxiliary learning objective hyperparameter 는 0.5로 사용한다.
주목할 점은 Pretraining이 충분히 잘 되었기 때문에 Fine tuning에서 적은 에폭만으로도 훌륭한 성능을 얻을 수 있다는 점, 대부분의 hyperparameter를 그대로 사용하는 점, learning rate를 pretraining 단계보다 훨씬 작게 사용하는 점이다. Pretraining과 Fine tuning이 가지는 특징이자 장점이라고 할 수 있다.
5. 마무리
이 논문을 계기로 Fine tuning이 NLP에서 핫해지기 시작했다. 하나의 잘 학습된 모델로 최대한 다양한 task를 해결하려는 노력은 분명 큰 의미가 있다. 상단에서 언급한 task들 이외에도 linear layer를 어떻게 구성하냐에 따라 더욱 다양한 task가 적용이 가능할 것이다. 다만 요즘 가장 핫한 QA의 경우 객관식 형태로 진행되는 것이 조금 마음에 걸리는데 주관식으로 가능한지 잘 모르겠다. 확실한건 BERT에서 QA를 주관식형태로 진행하는 것을 보여준다. 만약에 GPT-1에서 QA를 주관식형태로 진행하려면 context와 question만을 input으로 주고 language model처럼 출력이 answer로 나오는 형태가 되야할텐데 아마 그렇게 되려면 Fine tuning임에도 더 많은 학습을 해야하지 않을까 싶다. 그러나 확실히 객관식 형태는 무리없이 쉽게 학습할 수 있다고 본다.
