논문 출처 : https://arxiv.org/abs/1810.04805
1. Introduction
Language model을 통한 pretraining은 큰 성과를 얻었고 크게 주목을 받았다(ELMO, GPT-1, ULMFiT 등). NER같은 Token-level task 뿐만 아니라 sentence-level task와 그 이상의 task들에도 잘 적용되는 모습을 보여줬다. 이렇게 Pretrain를 통해 얻은 language representation을 downstream task에 적용하는 방법에는 크게 두 가지가 있다고 할 수 있다. ELMo와 같은 Feature-based, GPT-1 같은 Fine-tuning이 그것이다. Feature-based는 task-specific architecture에 pretrained representation을 추가적인 feature로 사용하는 것이고, Fine-tuning은 기존 파라미터를 미세하게 조정(fine-tuning)하고 약간의 새 파라미터만 추가하는 방식이다. 두 가지 방법은 모두 pretraining에서 Language Modeling이라는 objective function을 공유하면서 이 Language model이 unidirectional 하다는 것이 공통점이다.
BERT는 이 unidirectional을 개선하고 싶어했다. 즉, standard language model의 다음 단어를 추론하기 위애 이전의 단어들만 참조하는 특성이 QA task 같이 양방향의 참조가 필요한 task의 성능을 떨어뜨릴 수 있다는 것이다. 따라서 BERT는 standard language model 대신 MLM(masked language model) 을 사용하게 되었다. 이는 input sequence 중 일정 확률로 일부의 token에 mask를 씌워서 이 mask에 들어갈 단어를 추론하게 하는 것을 목적으로 한다. 이렇게 할 경우 더 이상 이전의 단어들만 참조해야하는 일반적인 language model과 objective가 달라지므로 양방향 참조가 가능해지는 것이다. 또한 BERT는 NSP(Next sentence prediction)이라는 task를 Pretraining 과정에서 진행하게 한다. 이는 두 개의 sentence를 하나의 input sequence로 넣어 이것이 이어지는 문장인지를 분류하게 하는 task이다. 추후 논문에서 다루겠지만 사실 NSP는 큰 의미가 없다고 한다.
2. Related Work
이 챕터에서는 Unsupervised pretraining에서 가장 널리 쓰인 두 가지 approach에 대해 알아보고자 한다.
(1) Unsupervised Feature-based Approaches
Pretrained Word-embedding은 NLP task에 있어 매우 큰 공을 세워왔다. 단순히 left-to-right language modeling objective를 사용하거나 혹은 유명한 Word2Vec같은 context안에 있어야 할 단어를 구별해내는 과정 같은 것이 Word-embedding을 얻는 예시이다. 하지만 이 친구들은 결국 Word-embedding이자 context-independent embedding에 불과하다. 즉, 단어가 문장 속에서 갖는 syntatic, semantic 정보에 대해서는 캐치하지 못한다는 말이다.
이를 위해 Sentence embedding나 paragraph embedding을 얻기 위한 노력이 이어졌다. Sentence embedding을 얻기 위하여 다음 sentence에 대한 후보군들을 얻는 방법이나 이전 시퀀스를 이용해 다음 시퀀스를 left-to-right 방법으로 generate 하는 방법이나 denoising auto-encoder를 사용하는 방법들이 제시되어 왔다.
그 후 제시된 ELMo는 Feature-based approach에 있어 당시 가장 현대적인 방법론이였는데, left-to-right 와 right-to-left language model을 사용하여 시퀀스 속 단어들을 통해 context-sensitive feature를 뽑아내는 방법이였다. 이를 통해 각 방향의 모델에서 나온 representation을 concatenate하여 contextual representation을 만드는 것이다. 이를 각 task에 따라 만들어진 Specific한 모델에 넣어 높은 성능을 얻는 것이 가능해졌다. Word2Vec도 결국엔 학습된 가중치 파라미터 행렬을 단어 임베딩으로 쓴 것처럼, ELMo 역시 모델을 통해 출력된 representation을 Pretrained word-embedding으로 사용하는 것이지만 각 방향의 LSTM 모델들을 사용하여 만든 representation이기 때문에 문장 내에서의 의미 정보를 더 잘 담고 있어 context-sensitive feature라고 불리는 것이다(ELMo에 대한 자세한 이야기는 추후 업로드 예정).
그러나 저자는 이 역시 완벽한 bidirectional이 아님을 분명히 언급하고 있다. 각 unidirectional LSTM을 두개 사용하던 아니면 biLSTM을 사용하던 잘 생각해보면 결국엔 정방향(forward)와 역방향(backward)를 동시에 진행하더라도 특정 단어와 그 단어와 2칸 이상 떨어진 단어간의 연관성을 direct하게 측정할 수는 없기 때문이다.
(2) Unsupervised Fine-tuning Approaches
Fine-tuning도 사실 아주 처음(2008년)에는 단어 수준의 임베딩만 얻는 방식이었다고 한다. 그러나 최근에 우리가 잘 아는 GPT, ULMFiT 같은 모델들처럼 Unlabeled text를 통해 contextual token representation을 학습하고 이를 fine tuning하여 supervised downstream task에 넘겨주는 방식이 주를 이루게 되었다. 이 approach의 가장 큰 장점이라고 한다면 처음부터 학습할 파라미터가 아주 아주 적다는 것이다(few parameters need to be learned from scratch). 대부분의 파라미터를 그대로 사용하며 task에 맞게 layer를 많아봤자 하나 정도 추가하는 방식을 사용하기 때문에 아주 큰 성능과 효율 향상을 이루었다.
3. BERT
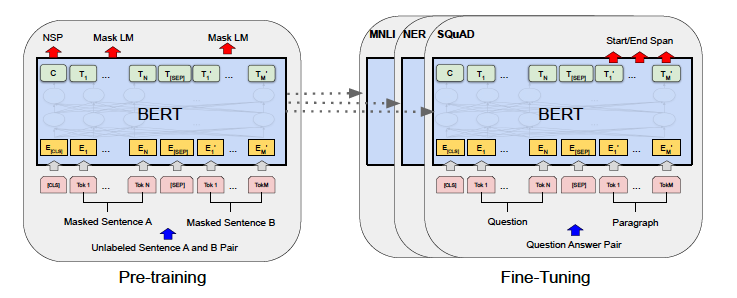
BERT는 이전의 GPT-1처럼 pre-training -> fine-tuning의 과정을 거친다. 즉, unlabeled data를 통해 두 가지(추후 자세히 설명) pretraining task를 수행하며, 학습이 끝나면 pretrained된 파라미터들을 활용하여 downstream-task를 수행한다. 이때 그림에서 볼 수 있듯이 각 downstream task 마다 모델을 각각 사용한다.
BERT의 가장 큰 특징이라고 한다면 unified architecture across different tasks 라 할 수 있다. 즉 task에 상관없이 모델 구조 변경없이 그대로 사용이 가능하다는 것이다. 앞에서 task 별로 모델을 각각 사용해야한다고 했지만 그 때 사용하는 모델의 구조는 모두 거의 같기에 추가적으로 밑바닥부터 학습해야할 파라미터가 거의 없는 셈이다. 논문에선 minimal change라는 표현을 쓰고 있는데 그럼에도 GPT-1과 비교했을 때 기본 모델만 쓰더라도 웬만한 task는 해결이 가능함을 강조하는 것이다.
(1) Model Architecture
BERT가 GPT-1와 모델 구조적으로 다른 가장 큰 점은 Transformer의 Encoder에 사용하던 일반적인 Multi-head attention을 사용한다는 것이다. GPT-1에서 Transformer Decoder의 Masked Multi-head attention을 사용했던 가장 큰 이유는 Language model의 auto-regressive한 성질을 지키기 위함이였다. 하지만 BERT의 pretraining objective는 일반적인 Language modeling이 아니다. 따라서 auto-regressive 성질이 필요하지 않게 되면서 시퀀스 내 모든 token간 attention 연산이 가능한 일반적인 self-attention module을 사용하는 것이다(뒤에서 자세히 설명).
기억하겠지만 Transformer의 Encoder Block은 Multi-head attention - Add & Norm - position-wise Feed Forward Network - Add & Norm으로 구성된다. 이 Block 내 변경없이 그대로 가져간다. 쌓는 Block의 개수(layer의 개수)를 L, hidden size()를 H, head의 개수를 A라고 할 때, BERT BASE 모델(L=12, H=768, A=12, Total Parameter = 110M)과 BERT LARGE 모델(L=24, H=1024, A=16, Total Parameter = 340M)을 제시한다. BERT BASE의 경우 GPT-1과 같은 사이즈이며 비교를 위해 제시한 것이다.
(2) Input/Output Representations
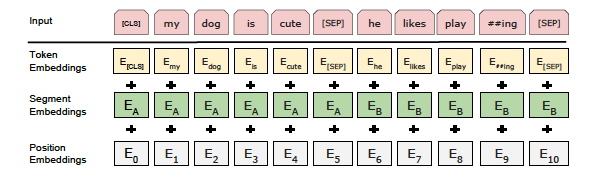
BERT로 다양한 Task를 다루기 위해선, input representation이 single sentence던 pair sentence(ex. <Question, Answer>)던 하나의 Sequence로 명확하게 input에 넣어야 한다.
BERT는 Token embedding으로 WordPiece embedding을 사용하여 30000개의 token vocabulary를 구성하였다. 모든 input sequence의 시작은 classification을 위한 [CLS] 토큰으로 시작된다. [CLS] 토큰이 feed 되어 최종적으로 나온 final hidden state는 classification을 위한 통합된 Sequence representation으로 사용된다. 또한 Pretraining 과정에서 이 [CLS] 토큰은 NSP task를 처리하기 위한 logit에 대한 input이기도 하다.
만약 input이 한 문장이 아니라면 어떨까? QA나 entailment task처럼 여러 문장이 input으로 들어가야 한다면 이를 [SEP]라는 구별 토큰을 사용해 input sequence내에서 다른 문장임을 표시하게 된다. GPT-1에서 delimiter 토큰과 같은 역할인 셈이다. 여기에 추가적으로 다른 문장임을 임베딩에 불어넣기 위해 Segment Embedding을 더하게 된다. 이는 A,B라는 문장이 하나의 input sequence에 들어있다면 A의 token들에는 A 임베딩을, B의 token들에는 B 임베딩을 넣는다. 또한 당연하게도 Positional Embedding도 추가된다. 종합적으로 input Embedding을 위해 Token Embedding + Segment Embedding + Position Embedding을 더해서 구성하게 된다. 상단의 그림을 참고하면 더 직관적으로 이해할 수 있다.
(3) Pre-training BERT
GPT-1이나 ELMo와 다르게 일반적인 Language model을 쓰지 않는다고 언급하였다. 이 챕터에서는 구체적으로 어떤 Task들을 통해 모델을 Pretrain 시키는지 알아보겠다. 명심할 건 두 Task 모두 Unsupervised task라는 점이다.
1) Masked LM
일반적인 LM의 목적을 생각해보자. token이 input으로 주어지면 이를 통해 다음 token을 예측하고 이를 실제 target sequence와 비교하면서 얼마나 문장을 잘 만들어내는지가 목적이다. 그 과정에서 auto-regressive 해야하기 때문에 left-to-right, 혹은 right-to-left의 방법만이 유효했던 것이다.
하지만 BERT의 Masked LM은 다르다. 기본적으로 Bidirectional 하다는 것은 어떤 token을 predict함에 있어 시퀀스 내 모든 단어들을 참조하는 방식이기 때문에 일반적인 LM objective를 사용하게 되면 Cheating이 되고 학습도 정확히 될 것이란 보장이 없다. 따라서 새로운 objective가 필요하다. 이를 위해 input sequence 속에 지정한 비율만큼의 token에 mask를 씌우고 이를 predict하는 새로운 LM method를 제시하게 된 것이다. 중요한 점은 input sequence를 feed했을 때 나오는 hidden representation 모두에 대해 predict해서 input sequence를 복원하는 기존 방법(denoising auto-encoder)와 다르게, 오로지 Mask된 input token이 들어간 자리의 hidden represenation들만 softmax를 통해 predict하고 이를 Cross entropy loss를 통해 학습하게 되는 것이다.
저자는 각 시퀀스마다 랜덤으로 15%의 토큰들을 Masked하기로 하였다. 그러나 이들을 모두 Mask하게되면 큰 문제가 하나 발생하게 된다. Fine-tuning 단계에선 Mask를 하지 않기 때문에 Pretraining과 Fine-tuning 사이의 discrepancy(차이) 가 발생하게 된다. 저자는 이를 해결하기 위해 15%의 비율로 선정된 token들에 대해서도 모두 mask시키지 않고 그 중 80%는 mask, 10%는 다른 토큰으로 교체, 10%는 그대로 두는 것을 제시하였다.
BERT가 분명 아직까지도 널리 쓰이는 것은 분명하지만 이 Masked LM의 discrepancy의 문제는 쉽게 간과할수 없기에 이후 BERT를 개선하고자 하는 노력들이 많이 이루어졌다.
2) Next Sentence Prediction(NSP)
앞에서 언급했던 문장간의 관계가 중요한 QA, entailment 같은 task들을 생각해보자. 저자는 Language modeling이 이 relationship을 잘 캐치할 수 있냐는 질문에 그렇지 못하다고 하였다.
Pretraining 과정에서 이 문장간의 relationship을 캐치할 수 있도록 하기 위해 고안된 것이 바로 Next Sentence Prediction task이다. 이는 pretraining 과정에서 corpus 속 Sentence A와 B를 골라 합쳐서 input sequence로 만들게 되는데, 이때 A에 대하여 B를 50%의 확률로 실제 A 다음으로 오는 문장으로 두고 나머지 50%의 확률로 corpus 내의 임의의 문장으로 두게 된다. 각각의 경우에 대해 label을 IsNext와 NotNext로 하고 위에서 언급한 [CLS] 토큰의 최종 hidden representation 값으로 이를 분류하는 task가 바로 Next Sentence Prediction인 것이다.
저자는 이 task를 pretraining 과정에서 학습시킴으로써 QA나 NLI task의 성능이 많이 올랐다고 한다(하지만 추후 BERT를 활용하는 여러 연구에서 NSP가 큰 효과가 없다고 제외하기는 추세가 되었다). 이 Task를 위해 pretraining 과정에서 쓰이는 training Corpus에 무작위로 섞인 sentence-level corpus 대신 Document-level corpus를 사용한다.
(4) Fine-tuning BERT
text pair를 다룰 때 이전의 방법(Parikh et al. (2016), Seo et at. (2017))은 Self-Attention이 등장하기 이전에 문장 간 attention 연산을 위해 고안된 bidirectional cross attention에 input 시퀀스를 넣기 전에 각각의 문장을 encode하는 방법이었다. BERT는 반면에 이를 한번에 하기 위해 두 문장을 하나의 연결된 시퀀스로 처리하고 이를 self-Attention 연산에 넣는 방식으로 encode하였다. 이를 통해 이전의 bidirectional cross attention라는 개념도 잘 구현할 수 있었고 절차도 단순화 되었다고 한다. 아무튼 핵심은 Task에 관계없이 하나의 시퀀스로 concatenate해서 input으로 넣어준다는 점이다.
4. Experiments
11가지 NLP task들에 대하여 BERT가 어떤 input format과 output predict를 진행하는지 확인해보자.
(1) GLUE(General Language Understanding Evaluation)
GLUE dataset은 NLU(Natural Language Understanding)을 위한 Benchmark로 총 9개의 labeled corpus로 구성되어있다. 대부분 분류나 문장 간 유사도 측정, 논리관계 분류, 질의응답 정답 분류 등 label이 단순한 task들로 구성되어 있다. 이를 해결하기 위해서 Pretraining 단계에서 NSP task를 위해 사용했던 [CLS] 토큰에 대한 출력값 hidden vector 를 linear layer에 feed하여 출력값에 대한 Softmax 연산을 통해 간단히 해결한다. 이때 linear layer에 사용하는 파라미터는 label 수 에 대하여 이다.
저자는 batch_size = 32로 3에폭만에 성능 향상을 이루었다고 한다. Learning rate는 5e-5, 4e-5, 3e-5, 2e-5, 1e-5 중 Validation set에서 가장 좋은 성능을 보인 learning rate를 empirically하게 골랐다고 한다.
BERT Large 모델의 경우, GLUE 내 dataset이 작을 때 성능이 안정적이지 않은 문제가 있었다. 저자는 같은 Pre-trained model에 대해 random restart(data shuffling, classification layer initialization)을 몇 번 시행하고 Validation set에서 가장 좋은 성능을 보인 모델을 선택하였다. 결론적으로 GPT-1 대비 큰 성능 향상을 이루었다.
(2) SQuAD v1.1
SQuAD는 Question과 Passage로부터 Answer를 찾아내는 dataset이다. Answer는 Passage안에 span해 있기 때문에 단순히 Passage 시퀀스 속에서 Answer 시퀀스를 찾으면 되는 task인 것이다. Input으로 question과 passage가 하나의 시퀀스로 묶으면서 question에는 Segment Embedding A, passage에는 Segement Embedding B로 놓고 fine-tuning을 진행한다.
Passage로부터 Answer를 찾는 이 과정은 Start Vector 와 End Vector 를 학습하는 것을 목표로 한다. input sequence의 i번째 token에 대한 출력 값을 로 하자. answer span을 찾기 위해 인 에 대하여 의 값을 score로 정의한다. 이때 이 score가 가장 큰 에 대하여 answer sequence라고 predict하게 된다. 해당 Task에 대한 training objective는 score의 값들이 Softmax를 통해 확률 값으로 표현될 수 있다는 점을 고려, 올바른 start position과 end position에 대한 log-likelihoods의 합으로 정의된다.
batch_size=32, learning_rate = 5e-5로 3 에폭만에 성능 향상을 이루었다. 다만 SQuAD이 개선되어 어떤 public data도 사용이 가능해졌다는 점을 활용하여 TriviaQA로 먼저 Fine-tuning 후 SQuAD에 대한 Fine-tuning이 진행됐다.
(3) SQuAD v2.0
Task는 앞과 같지만 Passage안에 답이 없는 경우가 추가된 좀 더 넓은 범주의 QA Task에 대한 Dataset이다. No Answer인 경우를 구별하기 위해서 [CLS] 토큰에 대한 출력값 에 대해 이라는 score 값을 하나 계산하게 된다. 앞에서 언급한 answer span score의 max 값 에 대하여, 최종적으로 Answer가 있다고 판단하기 위해서는 를 만족해야하며 이때 는 Validation set의 F1 score를 최대화하는 값으로 선택한다. 주어진 부등식을 만족하지 못하면 Passage에 Answer span이 없다고 predict하게 된다. batch_size=48, learning_rate = 5e-5로 2 에폭만에 성능 향상을 이루었다.
(4) SWAG(Situations With Adversarial Generations)
SWAG Dataset은 Grounded commonsense inference를 위한 Dataset으로, 각 instance가 sentence pair로 이루어져있다. 하나의 Sentence에 대해 다음으로 가장 올만한 Sentence를 4개의 보기중에 고르는 task이다.
Fine-tuning을 위해 주어진 Sentence(A)와 가능한 다음 Sentence(B)를 concatenation해서 4개의 input sequence를 만들게 된다. 그리고 [CLS]토큰의 출력값을 통해 4개의 choice에 대한 Softmax연산을 통해 predict하게 된다.
batch_size =16, learning_rate = 2e-5으로 3에폭만에 성능 향상을 이루었다.
마무리
BERT는 GPT와 분명하게 대비되며 auto-regressive 성질을 버리고도 Language Modeling을 충분히 구현할 수 있는 approach를 제시했고 성능도 압도적이었다. 현재 많은 후속연구들이 BERT를 개선하고 활용하고 있다.
