GPT-2의 논문 발표가 BERT를 의식한 듯 꽤 빠르게 이루어졌다. BERT의 혁신적인 MLM 방식에 경쟁의식을 느끼고 OpenAI에서는 그들과 NLU에서 competitive한 성능을 얻고자 하기보단 auto-regressive를 유지하되, zero-shot과 multitask 라는 키워드를 강조하며 그쪽에 초점을 맞추겠다는 의지를 확인할 수 있다. GPT-2라고 해서 모델 구조가 혁신적으로 바뀌기보단 본 논문은 pretraining을 위한 corpus를 web에서 대량으로 긁어와 데이터양을 충분하게 확보하는 새로운 아이디어를 제시하는데 의의가 있다고 생각하고 본 논문을 읽으면 좋을 것 같다.
1. Introduction
일반적인 ML system을 구축하기 위해서 작업자는 원하는 task에 대해 원하는 행동(behavior)을 보여주는 데이터를 수집하여 데이터셋을 구축한 뒤 해당 behavior를 system이 모방(imitate)하도록 훈련시키고 해당 system의 성능을 IID(Independent and Identically Distributed) 하게 뽑힌 examples에 대해 검증해야 한다. 이 일반적인 방식이 narrow expert를 만들 수는 있어도 generalist를 만들기에는 어렵다는 것이 저자의 의견이다. 그 이유로 이러한 시스템들이 data distribution이나 task specification의 작은 변화에 아주 불안정하고 민감하기 때문이라는 것이다. 생각해보면 일반적인 지도학습에서 같은 이미지 분류 태스크라도 이미지의 분야 (동물 혹은 사람 등)가 바뀌어도 성능이 보장될 것이라고 장담하기는 어려운 것처럼 말이다. 정리하자면 이유는 단일 도메인 데이터셋에 대해 단일 task로 학습하는 일반적인 방법론의 유행이라는 것이다. 따라서 특별한 labeling이나 annotation 없이도 여러 task들을 잘 수행해낼 수 있는 generalist가 필요하며 이러한 관점에서 종합적인 system의 성능을 파악하기 위해 GLUE와 같은 통합 벤치마크가 관례처럼 사용되기도 하며 decaNLP같은 generalist model을 만들기 위한 노력도 이어져왔다.
이 부분을 다루는 키워드를 우리는 "Multitask learning" 이라고 칭할 수 있다. NLP에서 이 Multitask learning은 아직 극 초기단계 (논문 발표 시점 기준) 이지만 몇몇 연구에서 초기단계라는 점을 감안했을 때 놀라운 성능을 보여준 바가 있다. 하지만 여전히 데이터의 양을 늘리는 것의 한계와 multitask learning을 위한 복잡하고 난해한 set-up은 아직 갈 길이 멀다고 볼 수 있는 포인트가 되시겠다.
language task를 가장 잘 수행해내고 있는 system은 명실상부하게 "Pretraining + fine-tuning" 이다. word vector를 학습시켜 task-specific architecture에 input으로 사용하는 방식 (word2vec, Glove) 에서 RNN을 활용한 contextual representation을 활용하는 방식 (ELMO) 으로 진화하였고, 현재는 self-attention block의 위대함 덕분에 task-specific architecture 필요없이 하나의 모델에서 end-to-end 로 진행하는 방식이 되었다. 그러나 이 역시도 supervised training이 필요한 것은 마찬가지이다. supervised training을 위한 데이터셋이 부족하거나 없을 경우를 위해 language model로 특정 task를 수행하는 연구가 진행어왔다.
본 연구는 language model이 downstream task들을 zero-shot으로 수행할 수 있음을 입증하고자 한다.
2. Approach
GPT가 사용하는 Language modeling은 variable lenght sequence에 대한 unsupervised distribution estimation으로 처리된다. 보통 ordering이 있기 때문에 joint probability를 conditional probabilities에 대한 product로 factorize하는 것이 일반적이다.
한편 transformer의 탄생으로 이러한 conditional probabilities의 연산과 표현력이 매우 우수해졌다.
Probabilistic framework의 관점에서 single task의 학습은 conditional distribution 의 estimation으로 표현된다. 반면 general system은 같은 input에 대해서도 여러 다른 task들을 수행할 수 있어야 하기 때문에 수행할 task 역시 condition에 들어가야 한다. 즉, 를 estimation해야한다. 이를 Task Conditioning 이라고 칭할 수 있다.
Multitask와 Meta-learning setting에서 task conditioning이 다양하게 활용되고 있다. Architectural level에서는 task-specific encoder와 decoder를 사용하는 연구가 있었고 (One model to learn them all (Kaiser et al., 2017)), Algorithm level에서는 MAML(Model-Agnostic Meta-Learning)의 inner and outer loop optimization framework를 suggest하는 연구가 있었다 (Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks (Finn et al., 2017)).
그러나 McCann은 DecaNLP와 MQAN 연구에서 language 자체만으로 task, input, output 모두를 sequence of symbols로 표현하여 처리할 수 있음을 제시하였다. 예를 들어 QA task에서 (answer the question, document, question, answer) 의 형태로 training example을 구축할 수 있을 것이다. 그는 MQAN으로 여러 task들을 이러한 통일된 format으로 처리할 수 있음을 입증하였다.
language modeling은 어떤 symbol이 output으로 나와야하는지에 대한 prediction을 해야만하는 explicit supervision 없이도 MQAN의 task format들을 학습할 수 있다. 구체적으로 supervised objective와 unsupervised objective는 unsuperviesd가 sequence의 subset에 대해서만 evaluate되는 점 하나만 차이가 나기 때문에 두 objective의 global minimum은 동일하다. 이제 여기서 density estimation을 principled training objective로 설정해도 되는지에 대한 걱정은 뒤로 밀어두고 중요한건 이 unsupervised objective를 convergence 시킬 수가 있는지를 걱정해야 한다. 이전 연구들에서 분명히 밝힌 점은, 큰 language model을 사용하면 이런 toy-ish set-up (language 형태로 task와 input, output을 표현하는 것) 아래서 multitask learning을 할 수 있긴 하지만 학습이 supervised 에 비해 현저하게 느리다고 한다.
이렇듯 잘 정돈되었던 과거의 supervised의 설정에서 모든 처리를 language로 하려는 "language in the wild"의 혼란 속으로 넘어가는 것이 쉽지는 않겠지만, Weston의 연구 (Dialog-based Language Learning (Weston et al., 2016)) 에서는 dialog의 context에서 natural language에서 직접 학습할 수 있는 system을 개발하는 것에 대한 필요성을 강조하였다. 다만 dialog는 너무 restrictive하다는 점이 있다.
본 연구는 충분한 크기의 language model이 있다면 task를 natural language sequence로 표현하여 활용하면 method에 관계없이 predict를 잘 할 것이라고 추측하며 그것이 곧 unsupervised multitask learning이 된다는 것이다. 따라서 본 연구는 다양한 task에 대해 zero-shot setting으로 확인해보고자 한다.
2.1 Training Dataset
이전 연구들에서 Language model을 훈련시키기 위한 text들은 주로 single domain에 한정되어 있었다(신문기사, 위키피디아, 소설책 등). 본 연구는 최대한 크고 다양한 데이터셋을 구축하여 다양한 domain과 context속 task들에 대한 natural language demonstration을 포함할 수 있도록 하는 것이다. 즉, 단순한 pretraining을 넘어서 그 과정만으로도 어떤 task를 해야한다고 자연어의 형태로 알려줬을 때 모델이 그것 또한 이해할 수 있도록 하고싶다는 것이다. 아마 어쩌면 이 시도가 추후 prompt와 few shot으로 이어지지 않았을까 하는 추측을 해본다.
본 연구에서는 다양하고 아주 많은 text들을 수집하기 위해 웹 크롤링에 주목하였다. 분명 의도는 좋지만 아쉽게도 웹 상의 텍스트인 만큼 data quality issue
가 존재한다. A Simple Method for Commonsense Reasoning (Trinh & Le (2018)) 연구에서 Commonsense reasoning을 위한 데이터셋 구축과정에서 크롤링을 사용했지만 많은 문서들이 "unintelligible"하다는 것을 확인하였고, 이에 target dataset인 Winograd Schema Challenge와 가장 비슷한 극히 일부 문서들만 사용하여 최고 성능을 냈다고 한다. 본 연구 역시 초기 실험에서 이런 data quality issue를 확인하였고, 이에 대응하기 위해 Reddit에서 3개의 karma (좋아요) 이상 받은 페이지에 대해서만 사람의 filtering, curating을 거쳐 수집하였다.
이렇게 구축된 데이터셋 WebText는 약 45M개의 link 속 텍스트를 포함하고 있다. extracting 방법은 큰 의미가 없으므로 설명하지 않겠다. 중요한 점 중 하나는 WebText에서 Wikipedia를 뺐다는 점인데, 이는 위키 문서들이 test evaluation 데이터셋에 중복이 많이 되기 때문에 추후 analysis를 위해 제외하였다고 한다.
2.2 Input Representation
일반적인 Language Model은 어떤 string이든 probability를 compute하거나 generate할 수 있어야 한다. 현재의 large scale LM은 lower casing, tokenization, OOV token 처리 등의 pre-processing을 포함하고 있다. Unicode string으로 처리하는 것이 위의 조건들을 대부분 만족시키는데 반해, 현존하는 byte-level LM은 word-level LM (One Billion Word Benchmark)에 비해 한참 뒤쳐진다. 본 연구에서는 standard byte-level LMs를 WebText에 대해 훈련시키고자 한다.
Byte Pair Encoding (BPE)은 자주 나오는 symbol sequence에 대한 word level input과 자주 나오지 않는 symbol sequence에 대한 character level input을 interpolate 하는 효과적인 알고리즘 이라고 논문에 적혀있지만 무슨 말인지 모르는 사람을 위해 이 포스팅에서 자세히 설명하기엔 흐름을 벗어나므로 이 링크를 확인하여 자세한 알고리즘 예시를 확인하는 것을 추천한다. 그러나 그 이름에도 불구하고 reference BPE implementation은 byte sequence가 아니라 Unicode로 되어있다. 이 implementation은 약 13만개의 vocab size를 요구한다 (심지어 BPE의 multi-symbol을 더하기도 전인데 말이다!). 이는 일반적인 BPE에서 약 32000개에서 64000개의 vocab size를 필요로 하는것을 보면 엄청나게 큰 숫자이다. 반면 byte-level BPE는 단 256의 vocab size를 요구한다. 그러나 BPE를 바로 byte sequence에 적용하는 것은 greedy frequency based heuristic을 token vocab 구축에 사용하는 BPE 특성상 sub-optimal merge를 유발할 수 있다. 예를 들어, dog이라는 단어를 공유한 여러 multi-symbol (dog! , dog. , dog?)이 각각 별개의 token으로 처리될 수 있다는 것이다. 이는 곧 vocab size를 불필요하게 늘릴 수 있는 method이기 때문에 본 연구에서는 BPE가 문자 카테고리 (영어, 특수기호, 숫자 등)를 넘어서 merge하는 것을 prevent하는 식으로 조정하였다. 단 공백은 merge에 포함되도록 허용하였는데 이는 아주 조금의 fragmentation of words 발생에 반해 compression efficiency를 크게 향상시키기 때문이라고 한다.
결론적으로 BPE 적용을 통해 어떤 string도 잘 처리할 수 있기 때문에 어떤 dataset도 LM으로 처리가 가능하다는 장점을 가지게 된다.
2.3 Model
기본적으로 GPT의 구조는 따른다. 몇 가지 변경점이 있는데, Layernorm이 각 sub-block의 input 부분으로 옮겨졌다 (He 선생님의 pre-activation residual network와 비슷하다고 하는데 잘 모름). 또한 final self-attention block 뒤에 추가적인 Layernorm이 추가되었다. 그리고 model depth에 따른 residual path의 축적을 고려한 modified initializaiton이 사용되었다. 마지막으로 residual layer의 weight를 (=the number of residual layers) 로 조정하였다.
Vocabulary 크기는 50257로 키웠고 context size는 512에서 1024로, batch size는 512로 늘렸다.
3. Experiments
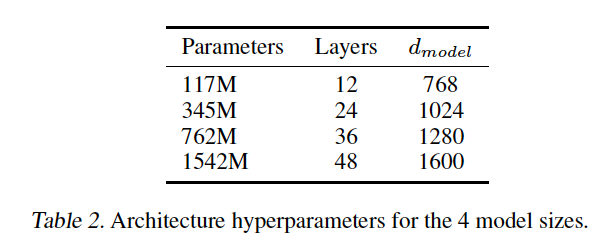
실험은 총 4가지 size의 LM에 대해 실행되었는데, 첫 번째는 GPT와 같은 사이즈고 두 번째는 BERT-large, 가장 큰 모델은 GPT-2로 칭한다. 각 모델의 learning rate는 WebText의 5% sample로 측정한 best-perplexity의 learning rate로 manually tune되었다. 중요한 포인트는 모든 모델은 여전히 WebText에 underfit 되어있으며 더 많은 training time이 있다면 개선될 여지가 남아있다.
3.1 Language Modeling
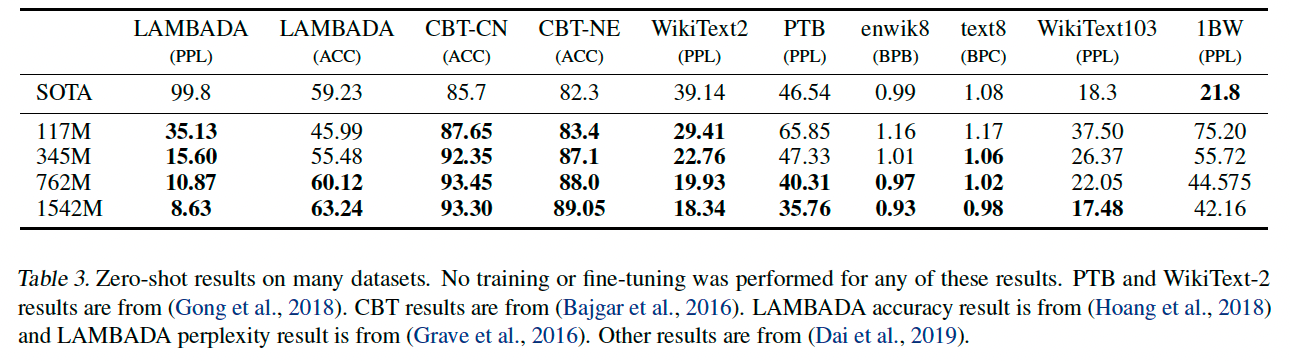
우선 WebText로 훈련된 LM이 zero-shot setting으로 다른 language model benchmark에 대해 어떤 성능
을 보이는지 확인해보고자 한다. WebText LM transfer는 domain과 dataset에 제한되지 않고 좋은 성능을 보였다.특히 Penn Treebank나 WikiText-2 처럼 작은 데이터셋에서 더 큰 성능 향상을 보였고 LAMBADA나 CBT(Children’s Book Test) 처럼 long-term dependency를 측정하기 위한 데이터셋에서도 큰 성능 향상이 있었다.1BW (One Billion Word Benchmark) 에 대해서는 매우 안좋은 결과를 얻었는데 이는 매우 큰 데이터셋이며 long-range structure를 제거하는 sentence level shuffling 을 하는 파괴적인 전처리를 하기 때문이다.
3.2 Children's Book Test (CBT)
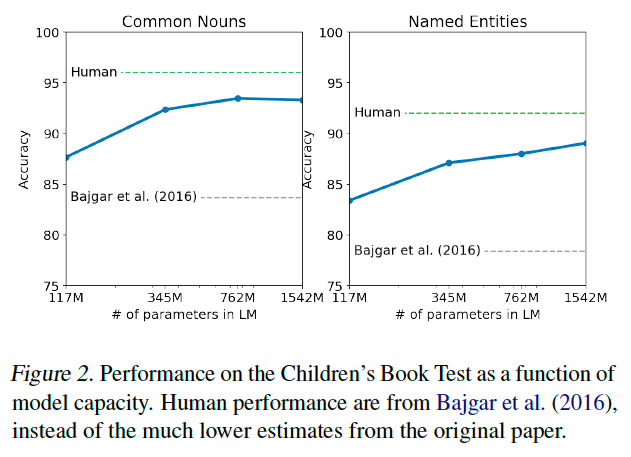
The Children’s Book Test (CBT) (Hill et al., 2015) was created to examine the performance of LMs on different categorie of words: named entities, nouns, verbs, and prepositions.
Perplexity 대신 Cloze test(10 choice)의 accuracy를 evaluation metric으로 설정하였고 모델 사이즈가 커질수록 human performance와의 gap이 점점 줄어들고 있음을 확인할 수 있다. CBT의 test set book 중 하나와 WebText가 겹치는 것이 있어서 이를 validation set에서 제외하고 결과를 report하였다고 한다.
3.3 LAMBADA
The LAMBADA dataset (Paperno et al., 2016) tests the ability of systems to model long-range dependencies in text. The task is to predict the final word of sentences which require at least 50 tokens of context for a human to successfully predict.
GPT-2는 8.6이라는 압도적인 SOTA perplexity를 달성하였으며 test 환경에서 accuracy가 19%에서 52.66%로 상승시켰다. GPT-2가 해당 데이터셋에서 보인 Error는 문장의 마지막을 단어로 종결하는 것이 아닌 연속해서 이어가려고 했기 때문에 발생한 것이라고 한다. 즉 해당 LM이 문장 마지막에 단어가 와야한다는 중요한 constraint를 사용하지 않는다는 것이므로 stop-word filter를 사용하는 것이 좋으며 정확도를 63.24% 까지 상승시켰다고 한다.
3.4 Winograd Schema Challenge
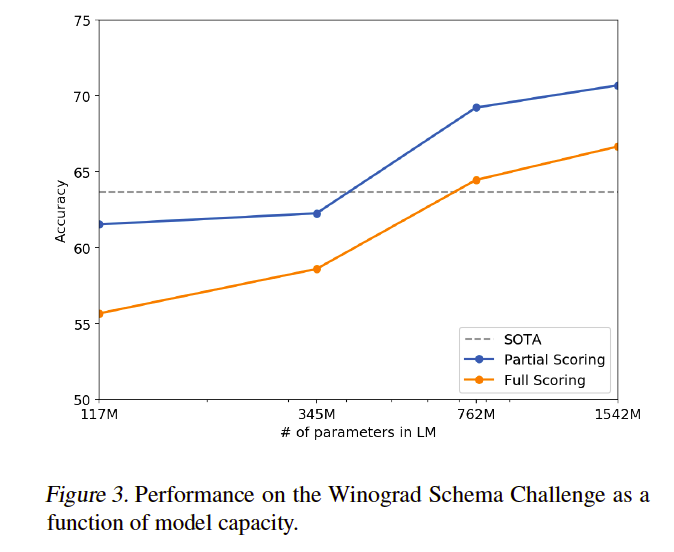
The Winograd Schema challenge (Levesque et al., 2012) was constructed to measure the capability of a system to perform commonsense reasoning by measuring its ability
to resolve ambiguities in text.
3.5 Reading Comprehension
CoQA (Conversation Question Answering dataset)은 7가지의 다른 domain에 대해 Question asker와 Question answer간의 natural language dialogue를 담은 데이터셋이다. 따라서 Reading Comprehension Capability 뿐만 아니라 converation history에 기반한 model의 질의응답 ability를 확인할 수 있다. document와 conversation history, final token에 대해 conditioned하여 Greedy decoding 하였을 때, development set 기준 55 f1 score를 달성하였다. SOTA 모델인 BERT는 supervised training을 하였지만 GPT-2의 성능은 supervised training 없이 이루었기에 분명히 주목할만 하다. 그러나 몇몇 에러를 통해 “GPT-2는 simple retrieval based heuristics(answer with a name from the document in response to a who question) (Who 질문에 대한 응답으로 문서의 이름을 사용하여 대답합니다.)를 사용한다" 라는 정보를 얻었다고 한다. 아마 아직 부족하다는 뜻으로 해석된다.
3.6 Summarizaiton

CNN and Daily Mail dataset을 사용하였으며 TL;DR: (Too long didn’t read) 를 article 뒤에 붙여서 summarize를 induce하였다. 100개의 token을 Top-k sampling(k=2)으로 생성하였는데 이는 반복을 줄이고 greedy coding 대비 더 abstractive한 summary를 유도할 수 있기 때문이라고 한다. 100개의 token들에서 처음 만들어진 3개의 문장을 요약으로 사용하였고 퀄리티있는 요약을 만들어내는 반면, article의 recent content에 집중하거나 specific detail을 헷갈리는 등의 문제를 보였다고 한다. ROUGE(Recall-Oriented Understudy for Gisting Evaluation) metric 기준 생성된 요약은 Classic neural baseline에 접근하기 시작하고 article에서 랜덤으로 3개의 문장을 뽑은 요약을 간신히 넘긴다. Task hint(TL;DR:) 이 제거 되면 성능이 좀 떨어지는데 이를 통해 LM이 task specific behavior를 유도할 수 있는 능력을 입증하였다고 한다. 즉, prompt를 연구해볼 촉매가 된 셈이다.
3.7 Translation
English text = French text format으로 모델을 학습시키고 inference에서 Englist text = ? 형태로 prompt 제공한 뒤 Greedy decoding으로 얻은 첫 번째 문장을 번역문으로 얻었다고 한다. WMT-14 English-French test set에서는 5 BLEU score를 얻었고 이는 bilingual lexicon(사전)기반 word-by-word substitution을 활용한 Unsupervised word translation보다 살짝 더 낮다. WMT-14 French-English test set에서는 매우 강력한 English language model을 활용하기 때문에 11.5 BLEU를 얻었다. 이는 몇몇 Unsupervised machine translation보다 성능이 우수했지만 여전히 현존하는 가장 훌륭한 Unsupervised machin translation (An effective approach to unsupervised machine translation (Artetxe et al., 2019))의 33.5 BLEU 보단 성능이 낮다고 한다. 그럼에도 불구하고 놀라운 것은 non-English를 WebText에서 필터링 했음에도 이런 결과가 나왔다는 점 (확인해본 결과 10MB 뿐)이다.
3.8 Question Answering
language model안에 정보를 잘 담는지 확인하는 방법은 factoid-style question에 대해 모델이 정확한 정답을 생성하는지 확인하는 것이고 NQ (Natural Questions Dataset)은 이를 확인하기 좀 더 좋은 데이터셋이다. context와 question, answer를 집어넣어서 모델이 short answer style에 대해 잘 Infer 하도록 하였다고 한다. GPT-2는 4.1%의 질문에 정확히 대답 (Exact match 기준) 하였으나 GPT-2 base Model은 1.0 accuracy를 넘지 못하였다. 이는 곧 모델 크기가 클 수록 더 많은 정보를 담을 수 있다는 반증이다. 가장 confident한 1% 질문들에 대해 생성된 답은 63.1% accuracy를 보였으나 GPT-2는 여전히 QA에서 나쁜 성능을 보인다.
4. Generalizaiton vs Memorization
CV분야의 연구에서 Common image dataset(ex. CIFAR-10)에 near-duplicate 이미지가 non-trivial amount 존재함을 보였다고 한다. 예를 들어 CIFAR-10에는 train과 test data에는 3.3%의 overlap이 존재한다. 이는 곧 generalization performance의 over-reporting라고 볼 수 있고,Dataset size가 커질수록 이 이슈는 더 부각될 것이며 WebText에도 위와 같은 사례가 발생할 수 있다. 따라서 얼마나 많은 test data가 train data에도 등장하는지 확인해야할 것이다. 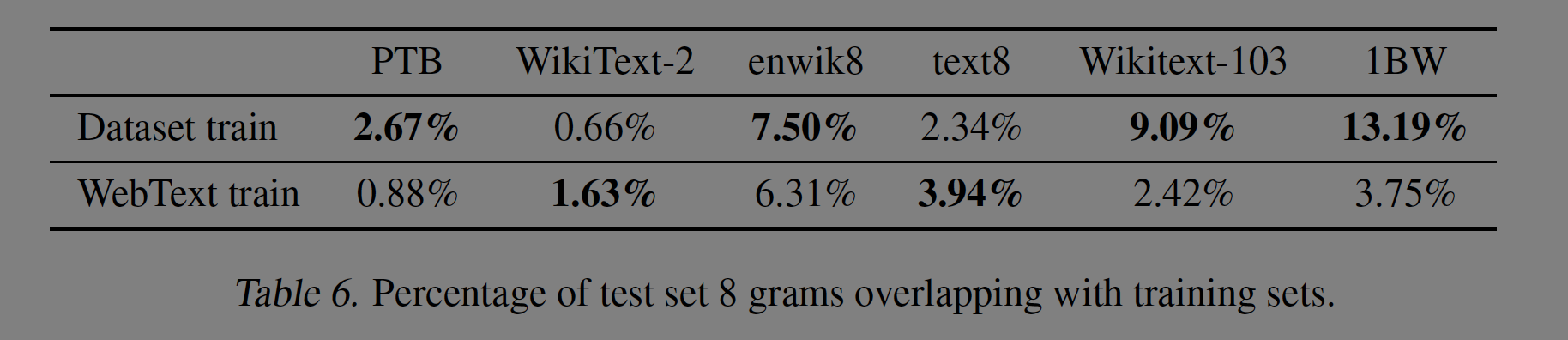
각 데이터셋의 중복에 대한 자세한 설명은 생략하고 표로 대체하겠다. WebText training data와 Evaluation dataset간의 data overlap은 분명한 소폭 성능향상을 불러온다. 그러나 이 overlap은 Evaluation dataset에 존재하는 train-test overlap보단 작다는 것을 어필한다. 즉, 본인의 모델의 평가가 더 공정하고 정확하다는 것이다.
5. Related Work
논문들과 간단한 설명만 첨부하고 넘기겠다.
Measuring the performance of larger language models trained on larger datasets.
- Exploring the limits of language modeling (Jozefowicz et al., 2016) : **Scaled RNN based language model을 1BW에 대해 학습
- Embracing data abundance: Booktest dataset for reading comprehension (Bajgar et al., 2016) : Project Gutenberg를 통해 standard training dataset을 보충하여 훨씬 큰 데이터셋을 만들어 CBT의 성능을 향상시킴
- Deep learning scaling is predictable, empirically (Hestness et al., 2017) : model capacity와 dataset size에 대한 성능 변화를 많은 deep learning model에 대해 확인해봄
Learned functionality in generative models
- Visualizing and understanding recurrent networks (Karpathy et al., 2015) : Cells in RNN Language model performing line-width tracking and quote&comment detection
- Generating wikipedia by summarizing long sequences (Liu et al., 2018) : model trained to generate Wikipedia articles also learned to translate names between language
Filtering and constructing a large text corpus of web pages
- The 14 billion word iweb corpus (Davies, 2018)
Pre-training methods for language tasks
- Glove: Global vectors for word representation (Pennington et al., 2014) : scaled word vector representation learning to all of Common Crawl
- Skip-thought vectors (Kiros et al., 2015) : Deep representation learning for text
- Learned in translation: Contextualized word vectors (McCann et al., 2017) : explored the use of representations derived from machine translation models
- Universal language model fine-tuning for text classification (Howard & Ruder, 2018) : Semi-supervised sequence learning (Dai & Le, 2015)의 RNN based fine-tuning approach를 개선
- Supervised learning of universal sentence representations from natural language inference data (Conneau et al., 2017) : studied the transfer performance of representations learned by natural language inference models
- Learning general purpose distributed sentence representations via large scale multi-task learning (Subramanian et al., 2018) : explored large-scale multitask training
Language model
- Unsupervised pretraining for sequence to sequence learning (Ramachandran et al., 2016) : Seq2Seq models benefit from being initialized with pre-trained language models as encoders and decoders
LM pre-training is helpful when fine-tuned for difficult generation tasks like chit-chat dialog and dialog based question answering systems
- Transfertransfo: A transfer learning approach for neural network based conversational agents (Wolf et al., 2019)
- Wizard of wikipedia: Knowledge-powered conversational agents (Dinan et al., 2018)
6. Discussion
Supervised와 Unsupervised pre-training methods의 representation에 대한 연구로 다음과 같은 연구들이 있다.
- Learning representation : Learning distributed representations of sentences from unlabelled data (Hill et al., 2016)
- Understanding representation : Neural word embedding as implicit matrix factorization (Levy & Goldberg, 2014)
- Critically evaluating represenation : No training required: Exploring random encoders for sentence classification (Wieting & Kiela, 2019)
본 GPT-2 연구를 통해 Unsupervised task learning이 유망한 연구분야임을 제시하고자 하며, Reading Comprehension에서 GPT-2의 성능이 zero-shot setting에서 Supervised baseline과 비벼볼만 하다. 그러나 요약은 아직 멀었고, 따라서 실용적으로 zero-shot을 사용하기엔 아직 부족하다
WebText LM의 zero-shot transfer를 다양한 NLP task에서 성능을 보여줬지만 아직 여전히 많은 task들이 남아있고, 의심할 여지 없이 많은 task에서는 GPT-2가 random보다도 못한 성능을 보여줄 것이다. 심지어 일반적인 task인 QA나 translation도 모델 사이즈가 충분할때 비로소 trivial baseline을 넘기는 모습을 보여준다.또한 본 연구가 Zero-shot이 아닌 fine-tuning에서는 어떨지 보여준 바가 없다.
On some tasks, GPT-2’s fully abstractive output is a significant departure from the extractive pointer network based outputs which are currently state of the art on many question answering and reading comprehension datasets.
이전 GPT-1이 fine-tuning에서 좋은 성과를 얻은 것을 생각하여 decaNLP나 GLUE 같은 benchmark에 fine-tuning하는 것을 진행해 볼 예정이며 추가 데이터(WebText)와 모델 사이즈가 GPT의 uni-directional을 극복할 수 있을지 미지수이기 때문에 더 많은 탐구가 필요할 것이다.
7. Conclusion
네 가지 정도의 키워드로 정리해볼 수 있을 것 같다.
large language model, large and diverse dataset, zero shot transfer, without the need for explicit supervision
필자의 의견으로 prompt learning의 촉매가 되는 것은 분명하다 당시 논문 자체의 관점으로는 많이 부족해보이는 것은 사실이다. 성능보다는 어떤 길을 열어준 논문과 연구로 바라보는 것이 더 좋아보인다.
