논문출처 : https://arxiv.org/abs/1907.11692
사실상 연구가 진행되는 기간까지 생각하면 GPT-2와 거의 같은 시기에 연구가 진행되고 같은 시기에 발표가 되었다고 볼 수 있다. BERT의 후속연구이며 BERT에 제시되는 여러가지 약점과 단점을 분석하고 발전시켰다.
1. Introduction
ELMo, GPT, BERT, XLM, XLNet 등의 Self-training 기법들이 큰 성능 향상을 불러왔으나 어떤 요소가 향상에 기여했는지 정확히 파악하기는 어렵다. 또한 training dataset를 Private하게 사용하는 점과 실험에 오랜 시간이 걸리는 점은 어떤 method가 성능에 어떤 영향을 끼치는지 정확히 비교 분석하는 것을 방해한다고 언급한다.
본 연구는 BERT의 hyperparameter tuning과 training set size에 따른 BERT의 성능 변화를 확인하고 더 나은 BERT 모델 훈련의 레시피(?)를 제시한다. 변경점을 정리하자면 다음과 같다.
- 더 많은 데이터로 더 큰 배치 사이즈에서 더 오래 학습시키기
- Next Sentence Prediction (NSP) 제거
- 더 긴 sequence에 대해 학습
- masking pattern의 dynamic changing
- CC-NEWS 라는 큰 새로운 데이터셋을 수집
2. Background
간단히 BERT를 리뷰하면서 몇 가지 부분들을 짚어보자
2.1 Setup
BERT는 최소 한 문장 이상으로 이루어진 Segment라는 단위에 대해 두 Segment를 concatenation하여 input으로 처리한다. 그 형태는 로 이때 지정한 최대 sequence length 에 대해 이 되게끔 과 을 제한한다. 모델은 large unlabeled text corpus에 대해 pretrain한 후 end-task labeled data에 대해 fine-tune한다.
2.2 Architecture
Transformer 구조를 사용한다. Denotation을 정리하자면 self-attention head의 갯수를 , hidden dimension 을 , Layer 수를 라고 할 것이다.
2.3 Training Objectives
Masked Language Model (MLM)
MLM은 input sequence의 token 중 일부를 random 하게 sampling하여 [Mask] 토큰으로 대체하는 것이다. 따라서 objective는 masking된 token에 대해 cross-entropy loss로 predict하는 것이다. BERT는 input token들의 15%를 선택하여 이 중 80%는 [MASK]로 대체하고 10%는 바꾸지 않고 10%는 vocab 내의 다른 random한 token으로 대체한다. original implementation에서는 이 random masking과 replacement가 미리 실행되어 저장되고 훈련동안 사용된다. 단, data들을 복제하여 각각 다르게 masking하기 때문에 훈련동안 같은 문장이라도 masking이 똑같지 않다.
Next Sentence Prediction (NSP)
NSP는 두 segment가 원본 text에서 서로 이어지는지 아닌지를 예측하는 binary classification task이다. Positive sample은 같은 문서에서 연속된 두 문장을 가져와서 만들 것이고 negative sample은 다른 문서에서 가져온 두 segment를 연결해서 만들 것이다. positive와 negative는 같은 probability로 sampling될 것이다.
NSP objective는 NLI와 같이 문장 쌍 간의 관계를 추론해야하는 downstream task의 성능을 올리기 위해 고안되었다.
2.4 Optimization
BERT는 Adam optimizer를 사용하였다. 구체적인 Adam parameter는 이고 의 weight decay를 사용하였다. learning rate는 첫 10000 step동안 까지 warm-up한 후 linearly deacy하도록 했다. 모든 layer와 attention weight에 0.1의 drop-out을 적용했고 GELU activation function을 사용했다. 총 1000000 step동안 update되었고 최대 512의 sequence length로 256의 배치사이즈로 훈련되었다.
2.5 Data
BOOKCORPUS와 English WIKIPEDIA 를 합쳐 총 16GB의 uncompressed text를 사용하였다.
3 Experimental Setup
3.1 Implementation
기본적으로 FAIRSEQ BERT를 재구현하였고, BERT의 대부분의 hyperparameter를 그대로 사용한다. 단 peak learning rate와 warm-up steps의 경우 각 세팅마다 다르게 조절하여 사용한다. 또한 본 연구에서 Adam optimizer의 epsilon 값이 훈련에 미치는 영향이 매우 큰 것으로 판단하여 이를 적당히 조정하여 더 나은 성능이나 안정성을 얻었다고 한다. 또한 큰 배치사이즈에 대해 로 설정하는 것이 안정성을 더 높인다고 한다.
Pretrainig에서는 sequence length를 512로 설정하였으며, BERT와 달리 중간중간에 짧은 sequence를 넣지 않았고 첫 90%의 update에서 sequence 길이를 일부러 줄인채로 훈련시키지도 않았다고 한다.
3.2 Data
BERT-style pretraining은 굉장히 많은 양의 데이터 (텍스트)를 요구한다. 선행 연구들이 BERT 대비 더 많고 다양한 데이터로 모델을 학습시켜 훌륭한 성능을 얻었다. 그러나 이런 추가 데이터들 모두가 공개되어있지 않다. 본 연구에서는 공개되어있는 최대한 많은 데이터를 수집하고자 한다. 단순히 수집하는 것에 그치지 않고 품질과 양을 각 비교에 맞게 조정할 수 있도록 한다.
크게 5가지 corpora를 사용한다.
- BOOKCORPUS + English WIKIPEDIA (BERT 학습데이터)
- CC-NEWS
- OPENWEBTEXT : GPT2 학습에 쓰였던 WebText의 open-source recreation 버전
- STORIES : story-like style data
3.3 Evaluation
세가지 벤치마크에 대해 평가를 진행한다.
GLUE
GLUE benchmark는 NLU (Natural Language Understanding) 분야를 평가하는 9가지 데이터셋의 collection이다. 내부 task들은 single-sentence classification 이나 sentence-pair classification 이다. replicaiton study (section 4)를 위해 ensemble이나 multitask learning없이 모델을 training data에 대해 fine-tuning 시킨 후 (수치나 방식은 BERT의 것을 그대로 따라감) development data에 대한 결과를 report하였다고 한다. 또한 Section 5에서 약간의 task-specific modification을 거친 test set result를 보일 예정이다.
SQuAD
SQuAD 데이터셋은 Extractive QA를 위한 데이터셋으로 V1.1은 모든 질문에 정답이 있지만 V2.0은 일부 질문이 정답이 없는 데이터셋이다. 본 연구 및 실험에서는 V1.1에서는 BERT와 같은 방식으로 fine-tuning하였으며 V2.0의 경우 question의 정답 존재 여부를 분류하는 binary classification loss를 추가하여 span loss와 더해 훈련시켰다고 한다. evaluation에서는 답변 가능하다고 분류된 데이터에 대해서만 span indices를 predict 하였다고 한다.
RACE (ReAding Comprehension from Examinations)
passage와 question에 대해 4가지 답 중 하나를 선택해야하는 task를 위한 데이터셋으로 passage가 다른 reading comprehension dataset 대비 매우 길고 question이 reasoning을 요구하는 정도가 크다.
4. Training Procedure Analysis
모델 구조는 BERT-base (L=12, H = 768, A = 12, 110M params) 로 고정한 채로 실험을 진행한다.
4.1 Static vs Dynamic Masking
기존 BERT는 data preprocessing에서 미리 random masking을 한다. 이를 single static mask라고 칭할 것이다. 각 training instance가 매 epoch마다 똑같은 mask를 사용하지 않게 하기 위해, 10배 복제하여 각각 다른 mask를 씌워 40 에폭을 학습시킨다. 따라서 어떤 하나의 masking된 sequence를 모델은 훈련동안 총 4번 보게 될 것이다.
이와 반대로 본 연구에서 제시하는 dynamic masking은 model에 feed하는 매 순간마다 masking pattern을 만들어내는 방식이다.
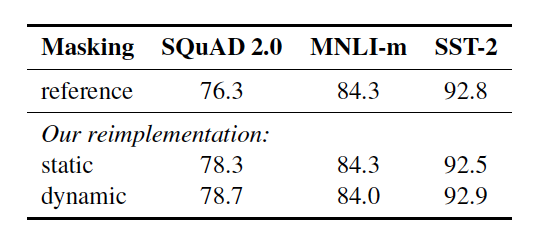
실험결과 전반적으로 대등하거나 더 나은 성능을 보였다.
4.2 Model Input Format and Next Sentence Prediction
기존 BERT의 pretraining에서는 같은 문서 혹은 서로 다른 문서 (확률은 반반)에서 sampling 해온 두 segment에 대해 이것이 같은 문서에서 왔는지 아닌지를 predict하는 Next Sentence prediction을 masked language modeling과 함께 수행한다. BERT에서 NSP는 매우 중요하다고 언급하며 이를 제거하는 것은 성능을 크게 해친다고 말한다. 그러나 몇몇 이후 연구 (XLM, XLNet, SpanBERT) 에서 NSP loss의 필요성에 대해 의문을 제기해왔으며 본 연구도 몇가지 옵션을 두고 실험해보고자 한다.
SEGMENT-PAIR + NSP
기존 BERT의 방식 그대로이며 각 input은 여러개의 문장으로 된 segment 두 개가 concatenate 된 형태이다. 총 길이는 반드시 512 tokens보다 작아야 한다.
SENTENCE-PAIR + NSP
pair 구성을 단일 문장으로 한다. 확실히 512 token보다 적을 것이기 때문에 배치 사이즈를 늘려 전체 토큰수를 비슷하게 맞추었다.
FULL-SENTENCES
완전한 문장들만 이어서 구성한다. 이때 하나 혹은 그 이상의 문서에서 가져올 수 있고 전체 길이가 512가 넘지 않도록 문장 수를 조절한다. 한 문서의 끝에 도달하면 다음 문서의 문장을 가져오고 그 사이에 [SEP] 토큰을 집어 넣는다. NSP loss를 제거한다.
DOC-SENTENCES
위 FULL-SENTENCES와 비슷하지만 document boundary를 넘어가지 않는다. Document 끝부분에서 sample된 input은 다른 input 대비 토큰수가 부족할 것이므로 batch size를 늘려서 위 옵션과 전체 토큰 수를 맞췄다. NSP loss를 제거한다.
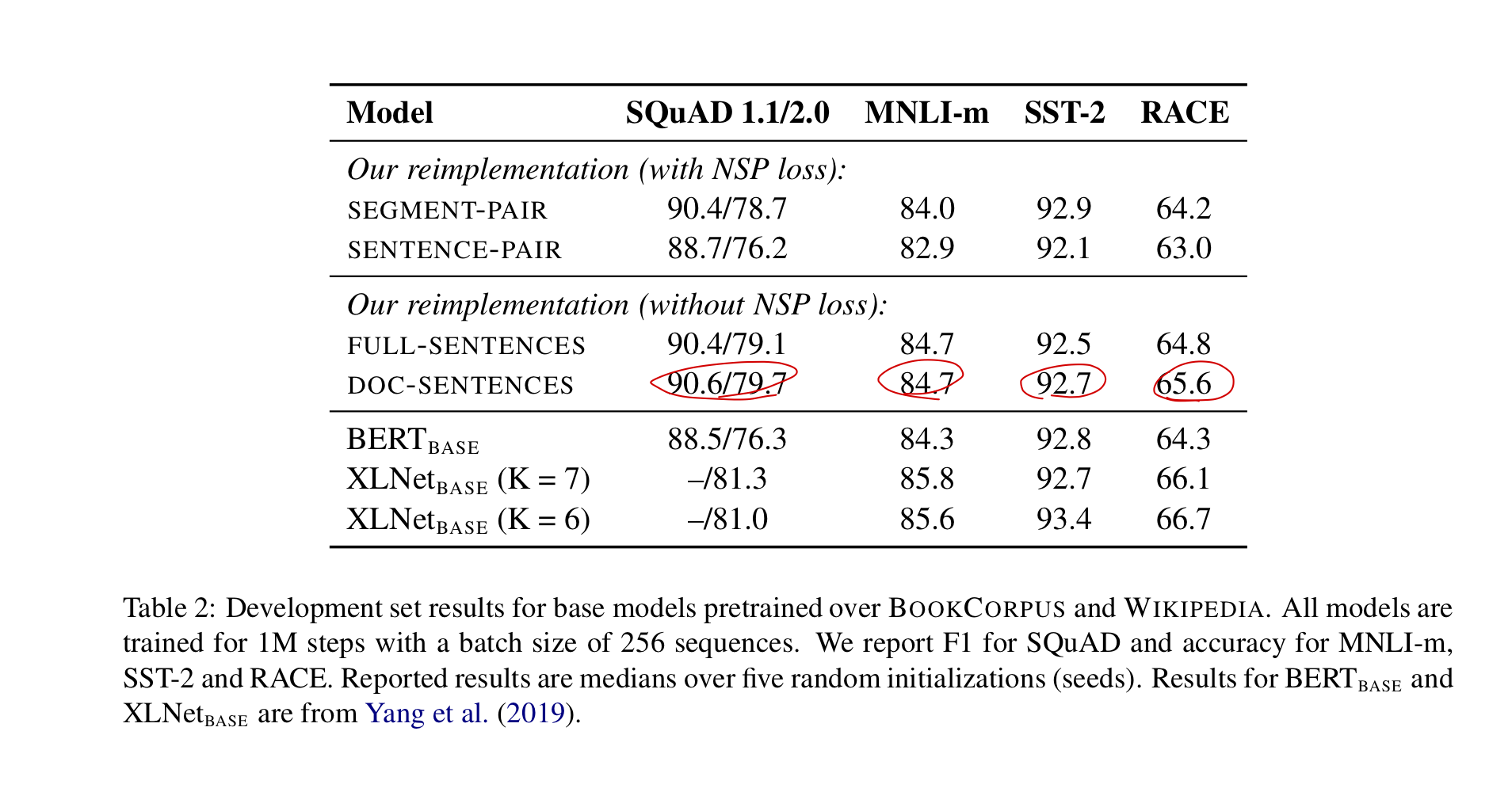
아래 결과를 확인해보면 우선 NSP loss를 두었을때 Sentence-pair가 더 낮은 성능을 보였다. 이는 모델이 long-range dependencies를 학습하지 못하기 때문이라고 판단하였다. Doc-sentences의 경우 기존의 BERT 성능을 outperform하였다. 따라서 기존 주장과 달리 NSP loss를 제거하는 것이 더 나은 성능을 얻을 수 있다고 보는 것이다. 또한 Full-sentence보다 Doc-sentence보다 나은 성능을 보여준다. 그러나 Doc-sentence의 경우 배치사이즈의 변화에 따라 결과가 많이 달라지고 조정이 불편하므로 이후 실험에서는 Full-sentence만을 사용하기로 하였다.
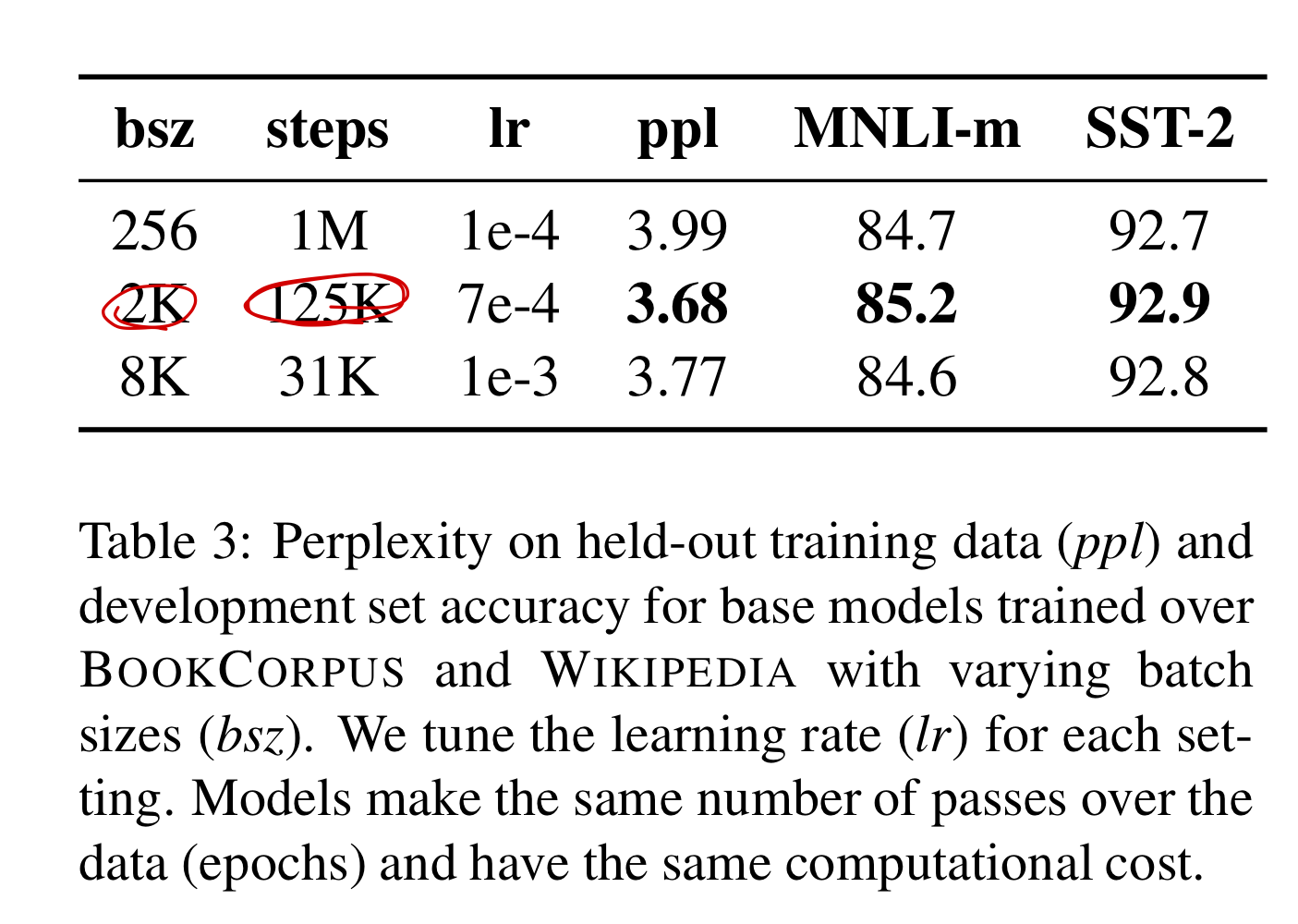
4.3 Training with large batches
기계 번역의 이전 연구들에서 큰 배치사이즈와 그에 합당한 learning rate로 훈련시키는 것이 optimization speed와 end-task performance를 향상시킬 수 있다는 것을 입증하였다. BERT 역시 이것이 효과있다는 연구도 발표되었다.
BERT는 256의 배치 사이즈로 1M steps동안 학습되었다. 이것은 computational cost 관점에서 gradient accumulation을 적용시켰을 때, 2k의 배치 사이즈로 125k step동안 학습시킨 것과 같고 8k의 배치 사이즈로 31k step동안 학습시킨 것과 같다.
4.4 Text Encoding
Byte-Pair Encoding (BPE)는 character-level representation과 word-level representation의 hybrid버전으로 큰 corpus 내에서 통계적 분석을 통해 subword unit을 찾아 사전으로 구축하는 방법이다. 일반적으로 10k~100k의 subword unit으로 사전이 구축되지만 크고 다양한 corpora를 다룰 수록 subword unit을 표현하는 unicode character가 사전에서 차지하는 비중이 매우 커진다. GPT에서는 unicode character 대신 byte를 기본 subword unit으로 사용하였고 이는 50k의 vocab size로 [UNK] token 없이도 어떤 텍스트든 처리할 수 있다는 장점을 가진다.
기존 BERT는 character-level BPE를 사용하여 30k size의 vocab을 heuristic tokenization rule로 처리하여 구축하였다. 본 연구에서는 GPT를 따라 BERT에 byte-level BPE로 50k size의 vocab을 구축하였으며 어떤 추가적인 전처리나 토크나이징이 필요없게 하였다. 이 vocab size의 증가는 기존 BERT모델에 약 15M~20M의 parameter 추가를 요구한다.
이전 몇몇 실험들에서 두 encoding (character-level BPE vs byte-level BPE) 의 차이가 크진 않지만 byte-level BPE (GPT ver)이 end-task 성능이 살짝 더 안좋다는 것을 밝혔다. 그럼에도 불구하고 byte-level BPE이 universial한 encoding scheme (추가적인 전처리가 필요없다는 점, UNK가 발생하지 않는다는 점)이라는 장점이 성능이 살짝 부족하다는 단점을 outweight하기 때문에 byte-level BPE를 사용한다고 한다.
5. RoBERTa
위에서 설명한 변경사항들을 모아 RoBERTa라는 새로운 configuration을 제시한다. 엄밀히 말하면 BERT 모델의 구조가 바뀐게 아니라 기존 구조에 학습시키는 여러 요소들을 변경한 것이기 때문에 configuration이라는 표현이 좀 더 맞다. 하지만 어쨌든 새로운 configuration으로 학습시킨 새로운 모델이 나오기 때문에 RoBERTa를 모델로 지칭하겠다. 즉, BERT 모델을 dynamic masking, Full-sentences without NSP loss, large mini-batches, larger byte-level BPE 로 바꿔서 학습시킨 모델이 바로 RoBERTa이다.
사실 위에서 데이터의 양과 배치사이즈, 학습 step 수에 대해서도 언급하였는데 이부분에 대한 정량적인 비교가 필요하다고 언급하고 있다. 따라서 RoBERTa를 BERT-Large (L=24, H = 1024, A =16, 355M params) 의 architecture를 채택해서 결과를 비교한다.
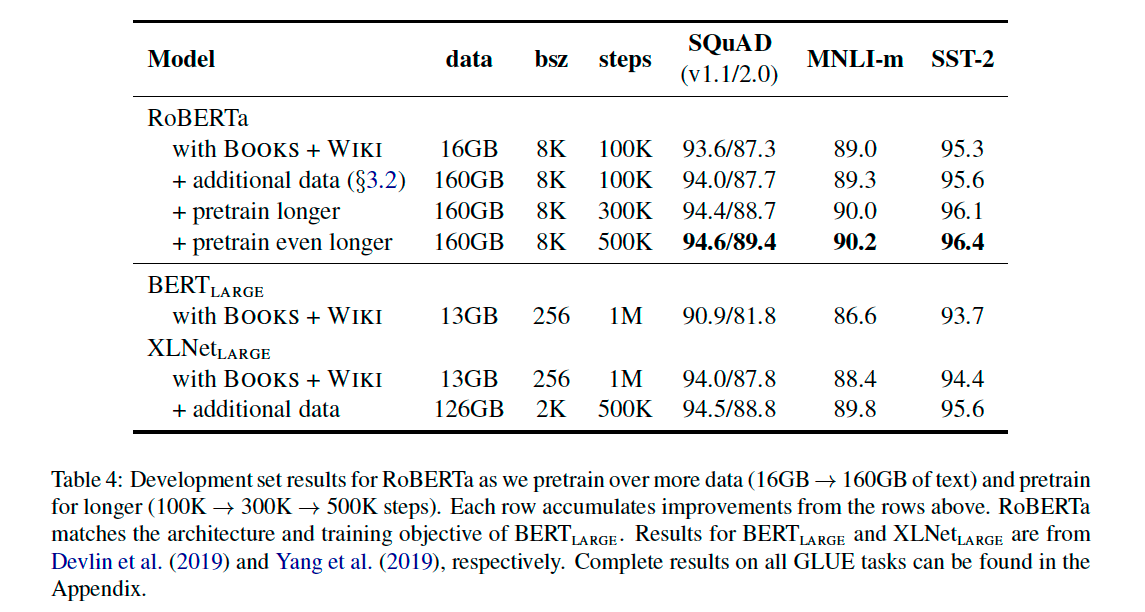
결과를 확인해보면 BERT와 같은 데이터량으로 학습시켰을 때도 RoBERTa가 end-task에서 더 우수한 성능을 보인다. 또한 더 많은 데이터를 추가했을때도 성능이 올라가며 더 오래 학습시킬 수록 성능이 더욱 올라가는 것을 확인할 수 있었다. 가장 성능이 좋은 500k step으로 학습시킨 RoBERTa 모델을 기준으로 GLUE, SQuAD, RACE 세 가지 데이터셋의 결과를 확인해보자.
5.1 GLUE Results
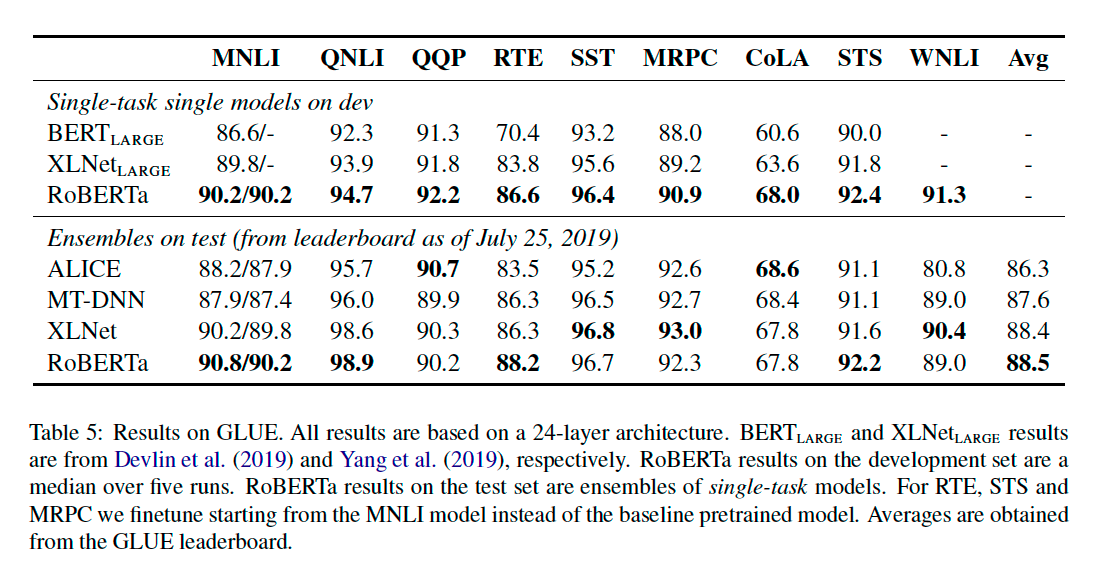
5.2 SQuAD Results
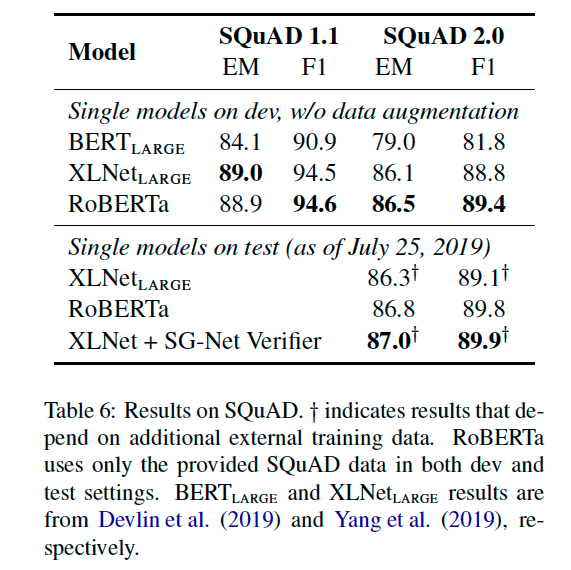
5.3 RACE Results
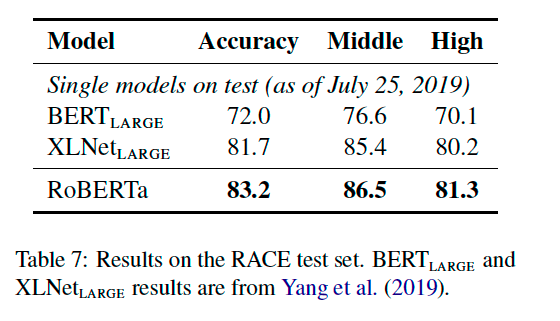
결론
RoBERTa가 결론적으로 BERT보다 훨씬 성능이 뛰어난 모델인 것은 분명하나 BERT의 impact가 큰 나머지 연구 비교의 공정성을 위해서 BERT를 사용하는 것을 아직도 논문에서 많이 확인할 수가 있다. 성능을 위해서라면 RoBERTa를 사용하는 것을 적극적극 추천한다.
