논문 출처 : https://arxiv.org/abs/1508.04025
이전 Seq2Seq를 소개한 논문에 대해 다룬 적이 있다(https://velog.io/@donggunseo/Seq2Seq). 여기에 요즘 핫하다고 하는 Attention 기법이 적용된 스탠포드 대학에서 낸 Seq2Seq with attention을 다뤄 볼 예정이다.
1. Introduction
기계번역의 관점에서 Seq2Seq 모델은 여러 한계를 이겨냈고 성능을 크게 끌어올렸다. 동시에 attention은 전혀 다른 modality(다른 타입의 데이터)를 가진 데이터 간, 예를 들어 speech와 text, video feature와 text 등을 학습하는 모델에게 큰 인기를 얻고 있는 기법이라고 하였다. MT에서는 Bahdanau의 논문에서 attention을 적용하여 공개한 바가 있고 그 후의 진전이 없었다. 저자는 이에 발전하여 attention을 적용할 두 가지 방법론을 소개한다. 첫 번째는 한 번에 모든 source sentence의 words에 대해 상관관계(attend)를 확인하는 global 방법이고, 두 번째는 매 time step 마다 source words의 subset에 대해서만 상관관계를 확인하는 local 방법이다. Global 방법의 경우 Bahdanau의 논문에서 제시된 방법과 비슷하지만 더 simple한 구조를 제시한다. Local의 경우 Xu의 image captioning 논문에서 적용한 hard attention과 soft attention의 블렌딩 버전이며, 연산량도 적고 모든 부분에서 미분이 가능하다는 장점을 가진다(이는 곧 학습이 더 용이하다는 점으로 이어진다).
2. Neural Machine Translation
우리가 봐왔던 Seq2Seq처럼 Encoder-Decoder 모델은 MT task에서 지속적으로 다루어졌었다. Encoder와 Decoder에 어떤 모델을 쓰며 Encoder가 source sentence로부터 representation, 혹은 vector를 어떻게 만들어 낼 것인지에 대한 여러 고민이 있었던 것으로 보인다. Seq2Seq의 배경이 되었던 KalChbrenner and Blunsom의 논문에서는 MT를 위해 Encoder에 CNN을, Decoder에 RNN을 사용했다. 여기서 발전해 RNN을 쌓아서 사용하기도 하고 LSTM이나 GRU를 사용하기도 했다. 어떤 방식이던 중요한 점은 source sentence로부터 나온 일명 "source representation" 이 Decoder의 hidden state initialization에 딱 한 번 쓰인다는 점은 모두 같았다는 것이다. 하지만 Bahdanau의 논문과 Jean의 논문, 그리고 이 논문에서는 Encoder의 한 개의 representation이 아닌 Encoder의 모든 과정에서 나오는 hidden states set을 사용하고 싶다는 목적에서 attention 기법을 고안해내게 되었다는 것이다.
추가적으로 이 논문에서는 아래 그림처럼 LSTM을 stack처럼 쌓아서 사용하였다고 언급하였다. 이전 Seq2Seq에서 말했다시피 RNN 계열 모델도 쌓아서 쓰는 것이 더 좋은 성능을 보였다고 언급한 바가 있다.
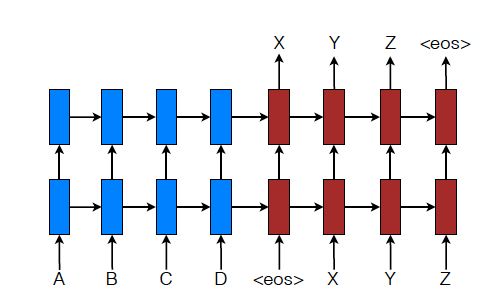
3. Attention-based Models
Introduction에서도 언급했지만 저자는 크게 Global attention과 local attention 두 가지를 고안해냈다. Attention의 영어 단어 의미를 생각해봤을 때, source 문장 전체에 관심을 가질 것인지, 아니면 특정 부분에만 가질 것인지가 두 approach의 차이점이라고 할 수 있다. 하지만 attention이라는 같은 이름을 갖고 있기 때문에 공동의 목적은 decoder의 매 time step마다 나오는 를 encoder의 모든, 혹은 일부 hidden state 들의 모음과의 어떤 연산을 통해 context vector 를 만들어 내고 이를 통해 현재 time step의 target word 를 predict하는 것이다. 이때 context vector에는 relevant한 source-side information, 즉 encoder단에서 연관된 정보들을 최대한 담아보겠다는 것이다. 여하튼, 마지막에는 context vector와 기존의 decoder의 hidden state인 를 concatenate하여 일반적인 linear layer with activation function를 거치고 softmax를 거쳐 최종적으로 predict를 하게 되는 것이다.
(1) Global Attention
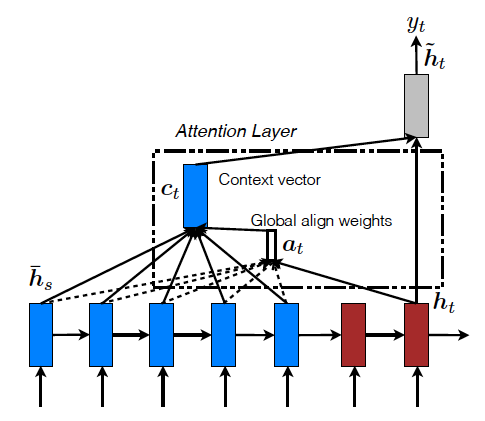
Global Attention은 Decoder의 매 time step마다 Encoder의 모든 hidden states를 통해 Context vector를 만들어 내는 approach이다. 가장 첫 단계는 attention vector 를 만드는 것이다. Encoder의 특정 time step을 라고 할 때, 해당 source hidden state 한개를 , target hidden state를 라 하면,
라는 스칼라값이 만들어지게 된다. 이 가 Encoder time step의 개수인 T만큼 모여 길이가 총 T인 가 만들어지고 이를 softmax연산을 거쳐 최종 attention 벡터가 만들어지게 되는 것이다.
다음으로 넘어가기전에 이 라는 식에 다양한 choice가 존재하는데 이에 대해 좀 더 알아보자.
여러 강의자료나 설명글에서는 보통 dot product를 많이 채택한다. 또한 이 Global attention이 우리가 일반적으로 Seq2Seq with attention의 개념을 배울 때 주로 접하게 되는 approach이다.
다시 돌아와서 이 정규화된 스칼라값으로 구성된 와 를 weighted sum을 통해 최종적으로 context vector 를 만들어낸다. 이 후의 과정은 위에서 언급한 대로 진행된다.
Bahdanau의 논문과 attention 방법을 좀 더 자세히 비교해보자. 먼저 현재 논문은 Encoder와 Decoder의 각 time step의 hidden state 출력을 사용하나 Bahdanau의 논문에서는 bi-directional Encoder의 양방향에서 나온 최종 hidden state 두 개를 concat한 것과 stack하지 않은 uni-directional decoder의 target hidden state를 사용한다. 두 번째로 현재 논문이 time step에서 출력된 hidden state를 사용하지만 Bahdanau의 논문에서는 이전 hidden state인 를 통해 context vector를 연산하고 이를 통해 해당 time step의 hidden state를 다시 구하는 계산 흐름을 가진다. 최종적으로 Bahdanau의 논문은 score 방법에 대해 concat 하나만 사용했지만 현재 논문에서는 여러 다른 방법을 사용하여 비교하였고 그 결과 다른 방법이 더 좋은 것을 확인하였다.
(2) Local Attention
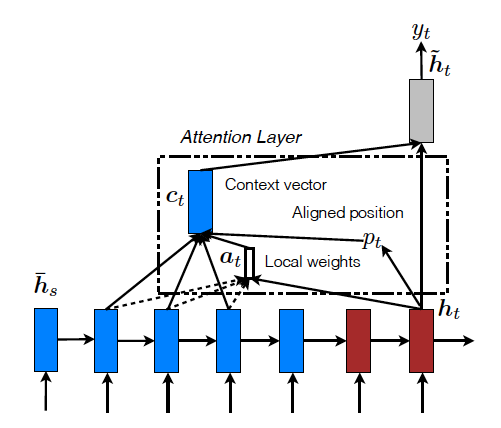
Global의 단점은 source sentence의 모든 단어에 대해 attention 연산을 진행하며 이는 문장이 길면 길수록 연산량이 많아지고 복잡하게 한다는 것이다. 이를 해결하기 위해 모든 source sentence의 단어를 확인하는 대신 각 target 단어마다 source sentence에서 word subset을 구성해 attention을 연산하는 방법인 Local Attention을 제시하였다.
Xu의 논문은 image caption generation task에서 soft attention과 hard attention라는 두 가지 approach를 제시했다. Soft Attention은 Source image의 모든 patch에 "softly"하게 weight를 줘서 각각 이미지에 적용한 뒤 합치는 방식으로 Global attention과 비슷하다. 반면 hard attention은 한 번에 한 개의 patch를 골라 이미지에 적용하는 방식이다. hard attention은 soft attention 대비 추론 과정에서 더 가볍다는 장점이 있지만 모델 자체가 미분 불가능하기 때문에 variation reduction이나 RL을 사용해야 하기 때문에 훨씬 복잡하다.
이 trade-off를 해결하고자 Luong은 small window of context(word subset)에만 신경쓰며 이때 미분가능하다는 것이 확인되었다. soft attention에서 문제가 되었던 expensive computation을 피할 수 있고 hard attention 대비 학습이 더 쉽다.
시작은 Aligned position 를 만드는 것에서 시작한다. 두 가지 방법이 있다.
1) Monotonic alignment(local-m)
Monotonic alignment(local-m) 은 단순히 로 설정하는 것이다. 이는 source sentence와 target sentence가 대충 monotonically 하게 aligned 되어있다는 가정에 따르는 것이다. 이렇게 정해진 에 대해 경험적으로 설정한 Window size 에 대해 source sentence에서 의 구간을 설정하여 해당 구간의 hidden states만을 모아 attention 연산에 사용한다. 이후의 연산은 global attention과 동일하다. 다만 attention vector가 라는 fixed-dimensionality를 가지는 점이 다르다.
2) Predictive alignment(local-p)
반면 Predictive alignment(local-p) 는 를 연산을 통해 예측하게 하는 것인데,
의 식을 따른다. 여기서 S는 source sentence의 길이이고 는 predict position을 학습하기 위한 model의 파라미터이다. local-p를 통해 나오는 는 sigmoid로 인해 의 값을 갖게 되므로 source sentence 안에서 window를 설정하기 위한 real-valued position 값임을 다시 한번 확인할 수 있다. 이는 local-m을 통한 가 integer 값임과 다른 점이다.
이후 attention vector를 얻기 위해 global attention과 동일하게 모든 encoder의 hidden states에 대해 softmax연산을 거친다. 그럼 무슨 의미가 있냐고 물어볼 수 있는데 결정적인 차이는 다음에서 발생한다.
최종 attention 벡터를 결정하기 전 중심이 인 Gaussian distribuiton의 식을 곱하게 된다. 이는 discrete하게 Context Window를 나누는 local-m 방법과 다르게, 이를 Gaussian 분포로 바꾸게 되면 의 위치 주변의 단어들은 더 높은 pdf값을 가지게 되고 멀리 있는 단어들은 아주 작은 pdf 값을 가지게 된다. local context window를 soft하게 구현했다고 할 수 있는 것이다.
softmax 연산을 거친, global attention에서 최종 output이던 의 각 element에 대해 를 곱해주게 된다(s는 각 단어의 encoder 내에서의 time step을 의미). Standard deviation 는 경험적으로 설정하는 하이퍼파라미터이며 논문에서는 로 설정하였다. Standard deviation을 조정함으로써 local-m에서 discrete하게 window size를 조정하던 것을 continuous하게 하는 것이라고 이해하면 된다.
(3) Input-feeding Approach
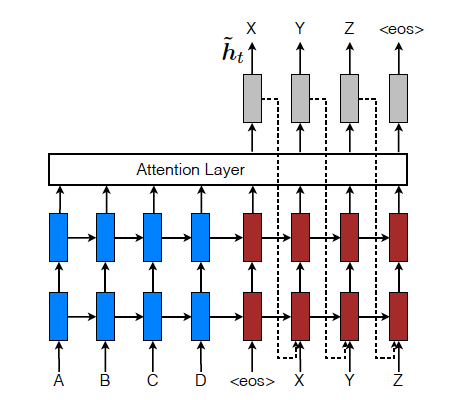
위의 global attention이든 local attention이든 각 단어에 대한 추론과정과 다음 time step으로 넘어가는 과정이 independent하게 이루어진다는 점을 주목하자. 실제로 저자는 attentional- NMT(Neural Machine Translation)에서는 past alignment information을 고려하여 다음 alignment를 결정해야 한다는 것을 언급하였다. 이를 위해 그림처럼 attention Layer를 거쳐 나온 context vector와 해당 time step의 hidden state를 concat한 벡터를 다음 time step의 input에 concat해서 넣어야 한다고 제시하였다. 이러한 과정을 input-feeding approach라고 한다. 이렇게 하였을 때 두 가지 장점을 가진다. 먼저 모델이 이전에 align 했던 choices를 인지하고 기억하도록 하는 것이고, 두 번째로 horizontal, vertical 방향 모두 깊은 network를 쌓을 수 있다.
4. 마무리
Experiment에서 input sequence reverse + dropout + local-p + input feed 가 제일 좋은 성능을 보여줬다. 단적으로 비교했을때 local-p가 global attention보다 더 좋은 성능을 보여줬다는 것이다. 또한 score function 선택에 있어 global attention의 경우 dot product가 좋은 성능을 보여줬고, local attention의 경우 general이 더 좋은 성능을 보여줬다고 한다. Transformer는 아마도 global attention을 개선하자는 방향성을 가진 모델이라는 생각이 든다.
