논문출처 : https://arxiv.org/abs/1409.3215
Seq2Seq는 구글에서 Sequence를 input으로 새로운 Sequence를 잘 만들어내기 위해 고안된 모델이다. 시퀀스 데이터의 특징을 이해하고 이를 위한 모델인 RNN 계열 모델을 통해 단순히 이를 분류하거나 추론하는 task가 아닌 기계 번역, 질의응답 같은 전혀 새로운 시퀀스를 만들어내는 것이 목적이다.
1. Introduction
일반적으로 우리가 사용하던 DNN(Deep Neural Network)는 여러 task와 domain에서 훌륭한 성과를 보여줬다. 그러나 DNN은 input과 target이 fixed dimensionality를 가진 vector라는 분명한 한계를 가진다. 이 한계에 부딪히는 대표적인 예로 위에서 언급한 시퀀스 데이터가 있는 것이다. 시퀀스 데이터는 길이가 전부 가변적인 것이 DNN을 그냥 쓰기에 큰 문제라는 점을 언급하고 있고, 그래서 시퀀스를 다루는 모델의 필요성이 대두되는 것이다.
논문에서는 LSTM을 통해서 주어진 시퀀스 데이터에 대해 large fixed-dimensional vector를 얻고 이를 다른 LSTM을 통해 벡터를 다시 시퀀스 데이터로 변환하는 방향성을 제시하는 것이다. 후에 얘기하는 것이지만 이것이 바로 우리가 지속적으로 들어왔던 Encoder-Decoder 모델인 것이다.
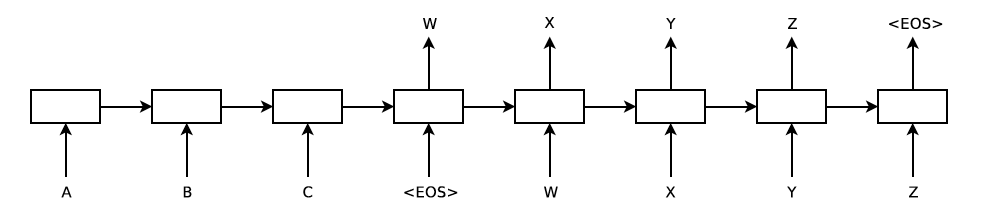
이 모델, 특히 LSTM으로 긴 문장을 다룰 때 겪었던 기존의 여러 단점들이 보이지 않았다는 점에서 큰 의미가 있다. 저자는 그 이유로 input 시퀀스만 reverse 시키는 방법론을 사용했기 때문이라고 했다(추후 설명).
2. The Model
일반적인 RNN 모델을 생각해보자. input Sequence와 output Sequence 간의 alignment(시퀀스 각 요소별 대응관계라고 생각하면 된다)가 명확하다면 특별한 고민 없이 RNN을 사용할 수 있다. 하지만 두 시퀀스간 관계가 길이도 다르고 관계가 complicated하며 non-monotonic 하다면 어떨까? 앞에서 언급한 기계 번역, 질의응답만 보더라도 output 시퀀스와 input 시퀀스는 분명 단순하게 표현할 수 있는 대응관계를 갖지는 않는다.
그 해답은 바로 두 개의 RNN 계열 모델을 사용하는 것이다. 첫 번째 모델에서 나온 hidden vector를 두 번째 모델의 첫 hidden vector로 제공한다면 쉽게 해결할 수 있는 것이다. 사실 조경현 교수님의 논문에서 이미 제시된 방법론이다. 하지만 RNN의 고질적인 문제인 long-term dependency 때문에 LSTM을 대신 사용하기로 결정하였다.
저자는 제시한 Seq2Seq 모델이 기존의 방법론과 다른 점을 크게 세 가지를 제시하였다. 첫 번째는 input용 하나와 output용 하나 총 2개의 다른 LSTM을 사용한다는 점, 두 번째는 LSTM을 위쪽으로 4개의 층을 쌓는 점, 세 번째로 input sequence를 뒤집어서 모델에 넣는 점이다. 각각에 대한 내용은 다음 장에서 더 자세하게 설명될 것이다.
3. Experiments
아무래도 모델의 제시 배경이 기계 번역이다 보니 실험 역시 기계번역 관련 데이터셋을 활용했고 이에 초점을 맞춘 몇 가지 포인트들을 확인해 보자.
(1) Decoding
모델의 학습과정에서 목적식은 다음과 같다. Source Sentence S와 올바른 번역 문장인 T에 대해 모아놓은 training set을 라고 할때, 다음 log probability를 최대화 하는 것이 목적이다.
학습이 끝나면 모델이 번역문 을 만들어 내게 된다. 이 Decoding 과정에서는 simple left-to-right beam search decoder를 사용하는데 이에 대한 내용은 이 글에서 Beam search에 대해 설명한 바 있다(추후 Beam search를 MT에 적용하는 논문도 리뷰할 예정이다).
(2) Reversing the Source Sentences
논문에서는 정확한 설명을 못하겠다고 한다. 다만, input 시퀀스를 뒤집게 되면 source sentence와 target sentence의 각 대응되는 단어의 평균 거리는 변함이 없지만 각 문장의 시작 부분의 거리가 매우 가까워진다. 이는 곧 decoder가 처음 작동할 때 source sentence의 앞부분을 더 정확히 캐치할 수 있어 성능이 더 올라간 것 같다고 해석하고 있다. 이는 곧 학습과정에서도 해당 부분에 대한 그레디언트가 거의 보존된 채로 전달되기 때문에 역전파과정에서 이득을 볼 수 있다고 언급하고 있다. 이는 심지어 더 긴 문장일 수록 좋은 성능을 보였다고 한다.
4. 마무리
추후 Encoder-Decoder 계열 모델의 바탕이 되는 논문이라고 할 수 있다. 이제 여기에 attention을 끼워넣는 논문으로 돌아오겠다.
