
RSS (Really Simple Syndication) 이란?
RSS는 웹사이트의 최신 콘텐츠를 기계가 읽기 쉬운 형태인 XML로 제공하는 표준 포맷입니다.
RSS의 등장 배경은 “사람이 직접 사이트를 방문하지 않아도 새로운 글을 받아볼 수 있게 하자”는 요구가 많아지며 생긴 기술입니다. 과거에는 사용자가 여러 사이트를 일일이 방문해야 했지만, RSS를 사용하면 프로그램이 피드를 구독해 새 글을 자동으로 수집할 수 있습니다.
RSS가 없다면 글을 어떻게 수집할까?
RSS가 없는 시절에는 개발자가 직접 HTML 구조를 분석해 원하는 데이터를 추출해야 했습니다.
이렇게 되면 사이트마다 구조가 제각각이기 때문에, 파싱 로직을 내가 추출하고자 하는 사이트와 1대1로 대응시켜 작성할 수밖에 없습니다.
결국 사이트가 10개면 10개의 크롤링 코드가 필요했고, 사이트의 HTML 구조가 조금만 바뀌어도 로직 전체를 수정해야 했습니다.
RSS의 등장
이러한 불편함을 해결하기 위해 등장한 것이 RSS입니다. RSS는 콘텐츠 제공자가 직접 정해진 규격에 맞춰 글 정보를 노출하도록 만들어졌습니다. 덕분에 콘텐츠를 수집하는 쪽(프로그램)에서는 더 이상 사이트별로 HTML 구조를 분석할 필요 없이, 표준화된 XML 형식만 처리하면 되었습니다.
RSS가 도입되면서 콘텐츠 수집 방식은 크게 달라졌습니다.
- HTML 구조 의존 → 표준 데이터 의존
- 사이트별 전용 크롤러 → 공통 파서 사용
- 잦은 깨짐 → 비교적 안정적인 수집
RSS의 구조
위에서 RSS는 콘텐츠 제공자가 정해진 규격에 맞춰 글 정보를 노출하도록 만들어졌다고 했는데요.
그렇다면 이 정해진 규격은 어떻게 생겼을까요?
RSS는 기본적으로 XML 기반 문서이며, 크게 두 영역으로 구성됩니다.
channel: 피드 전체에 대한 정보item: 개별 게시글 정보
예를 들어 RSS 2.0을 기준으로 item은 다음과 가은 형태를 가집니다.
<item>
<title>게시글 제목</title>
<link>https://...</link>
<pubDate>...</pubDate>
<description>...</description>
</item>RSS는 누가 제공하는걸까?
RSS는 콘텐츠를 만드는 쪽에서 직접 제공합니다.
대부분의 국내 블로그 플랫폼이나 뉴스 사이트는 자체적으로 RSS 피드를 생성해 공개하고 있습니다.
예를 들면 이런 곳들이죠.
이들은 새로운 글이 발행될 때마다 RSS 문서를 함께 갱신합니다.
따라서 수집 프로그램은 사이트의 화면을 긁어오는 대신, 공식적으로 제공되는 피드 주소만 구독하면 됩니다.
이 점이 RSS의 가장 중요한 특징입니다.
HTML 크롤링은 “외부에서 몰래 긁어오는 방식”에 가깝다면, RSS는 콘텐츠 제공자가 허용한 공식 창구를 이용하는 방식입니다.
그 덕분에 비교적 안정적이고 예의 바른 데이터 수집이 가능합니다.
엥? 그러면 콘텐츠 제공자가 RSS 피드를 제공해주지 않을 수도 있겠네요?
맞습니다.. 모든 사이트가 RSS 피드를 제공해주면 좋겠지만 그렇지 않은 사이트들도 있습니다.
사실 RSS 피드는 콘텐츠 제공자의 입장에서 신경 써야 할 또 하나의 골칫거리가 됩니다.
글을 작성할 때마다 피드가 정상적으로 갱신되는지 관리해야 하고, 어떤 정보를 어디까지 공개할지도 고민해야합니다.
그리고 콘텐츠 제공자는 광고 노출이나 페이지 체류 시간을 통해 수익을 얻는 경우가 많은데, RSS를 지원하게 되면 제공자의 입장에서는 손해이겠죠?
그래서 일부 플랫폼은 그래서 RSS에 본문 전체가 아닌 요약만 제공하거나, 아예 RSS 기능을 제공하지 않습니다.
boostus 요구사항
RSS에 대해 어느 정도 알아보았으니, 이제 이 기술을 boostus에서 어떤 문제를 해결하는 데 활용하려 했는지 정리해보겠습니다.
boostus의 목표는 여러 캠퍼들의 블로그에 흩어져 있는 개발 글을 한곳에서 모아 보여주는 것이었습니다.
이렇게 모인 글들이 캠퍼들의 성장 기록이 되고, 부스트캠프에 관심 있는 예비 지원자들에게는 좋은 학습 자료가 되길 바랐습니다.
블로그 플랫폼 조사
개발에 들어가기 앞서 캠퍼들이 개발 글을 주로 어디에 작성하고 있는지부터 살펴보았습니다.
대표적으로 다음과 같은 공간들이 사용되고 있었습니다.
- Velog
- Tistory
- GitHub Pages
- 개인 블로그 (React, Next.js 등으로 자체 제작)
RSS 지원 현황
| 블로그명 | RSS URL | 지원 여부 |
|---|---|---|
| Tistory | https://dongho-dev.tistory.com/rss | ✅ (rss 2.0) |
| Velog | https://v2.velog.io/rss/dongho18 | ✅ (rss 2.0) |
| Github Pages (jekyll) | https://jangdongho.github.io/feed.xml | ✅ (Atom) |
| 개인 블로그 (자체 제작) | - | ⚠️ optional |
캠퍼들이 사용하는 블로그 플랫폼에 따라 RSS 제공 방식이 완전히 달랐습니다.
어떤 곳은 RSS를 기본적으로 지원 했고, 아예 RSS가 없는 경우도 있었습니다.
플랫폼별 RSS 구조 분석
Tistory와 Velog의 RSS item을 분석해보니, 구조가 비슷하면서도 세부 포맷에는 차이가 있었습니다.
| 필드 | 설명 | 예시 |
|---|---|---|
<title> | 게시글 또는 항목의 제목 | [Troubleshooting] Jenkins에서 docker-compose 명령 수행 시 Permission denied 에러 |
<link> | 게시글/항목 URL | https://dongho-dev.tistory.com/58 |
<description> | 게시글/항목 상세 내용, HTML 가능 | Jenkins 컨테이너에서 docker-compose 사용 시 Permission denied 발생 |
<category> | 항목이 속한 카테고리, 여러 개 가능 | docker-compose |
<author> | 작성자 | dongho_dev |
<guid> | 항목 고유 ID, 영구 링크 여부 표시 가능 | https://dongho-dev.tistory.com/58 |
<comments> | 댓글 URL | https://dongho-dev.tistory.com/58#entry58comment |
<pubDate> | 작성일/게시일 | Fri, 12 Apr 2024 17:31:44 +0900 |
먼저 Tistory RSS item을 살펴보면, 제목, URL, 상세 내용, 카테고리, 작성자, 고유 ID, 댓글 URL, 작성일 등 필요한 데이터를 알차게 담아서 보내주고 있었습니다.
| 필드 | 설명 | 예시 |
|---|---|---|
<title> | 게시글 또는 항목의 제목 | [트러블슈팅] Supabase Max client connections reached |
<link> | 게시글/항목 URL | https://velog.io/@dongho18/트러블슈팅-Supabase-Max-client-connections-reached |
<guid> | 항목 고유 ID, 영구 링크 여부 가능 | https://velog.io/@dongho18/트러블슈팅-Supabase-Max-client-connections-reached |
<description> | 게시글/항목 상세 내용, HTML 및 CDATA 가능 | Supabase Max client connections reached 오류 발생 원인과 해결 방법, DB Connection Pool과 HikariCP 관련 설명 및 설정 방법 |
<pubDate> | 게시일/작성일 | Fri, 24 May 2024 15:19:20 GMT |
반면에 Velog의 경우, 제공하는 필드가 Tistory보다 단순했습니다.
주요 차이점은 다음과 같습니다.
category와author필드가 없음description에 CDATA가 포함되어 HTML과 특수문자가 섞여 있음- 작성일(pubDate) 표준이 Tistory는 KST(+0900)인 반면, Velog는 GMT 기준
플랫폼 선정 기준
Github Pages (jekyll)도 분석을 진행했었지만, RSS 대신 Atom 피드를 제공하고 있었기 때문에 boostus에서는 우선 Tistory와 Velog RSS만을 대상으로 수집을 진행하기로 결정했습니다.
선정 이유는 다음과 같습니다.
- Atom과 RSS는 구조가 비슷하지만, 파싱 로직을 단순화하기 위해 RSS에 집중
- 모든 플랫폼을 한 번에 대응하기보다는, RSS 구조가 표준에 가깝고 사용자 비중이 높은 곳부터 안정적으로 처리하는 것이 먼저라고 판단
RSS 공통 모델 설계
Velog와 Tistory는 둘 다 RSS 표준을 따르지만, 세부 필드 구성과 형식에는 차이가 있음을 확인했습니다.
그래서 boostus에서 사용할 RSS 공통 모델을 설계했습니다.
설계 기준은 다음과 같습니다.
- Tistory와 Velog에서 모두 제공하는 필드인가?
- 우리 서비스에 꼭 필요한 필드인가?
최종적으로 선정된 공통 필드는 다음과 같습니다.
| 필드 | 설명 | 예시 |
|---|---|---|
guid | 글 고유 ID | https://dongho-dev.tistory.com/58 |
title | 게시글 제목 | 글 제목입니다!! |
link | 게시글 URL | https://dongho-dev.tistory.com/58 |
description | 게시글 상세 내용 | 글 내용은 블라블라블라 입니다. |
pubDate | 게시일 | Fri, 12 Apr 2024 17:31:44 +0900 |
각 필드별 특징과 처리 방향은 다음과 같습니다.
guid (글 고유 ID)
- 글마다 유일하게 부여된 ID로, 중복 글을 걸러낼 때 사용됩니다.
- Tistory와 Velog는 이
guid가link와 동일했지만, 다른 블로그 플랫폼들은 항상 그렇지 않을 수 있어 별도 필드로 관리합니다.
description (게시글 상세 내용)
- Tistory와 Velog는 블로그 글 내용 전문을 HTML(CDATA) 형태로 제공합니다.
- 이 HTML 본문에서 썸네일 이미지와 요약 텍스트를 추출해야 합니다.
pubDate (게시일)
- Tistory는 KST(+0900), Velog는 GMT를 기준으로 제공되기 때문에 통일된 시간대 변환이 필요합니다.
- 데이터 수집 단계에서 UTC 기준으로 변환한 뒤, 서비스에서 글을 보여줄 때는 KST로 다시 변환하여 표시합니다.
엔티티 설계
이렇게 정의한 RSS 공통 모델을 기반으로, 이제 실제 데이터베이스에 저장할 엔티티를 설계해보겠습니다.
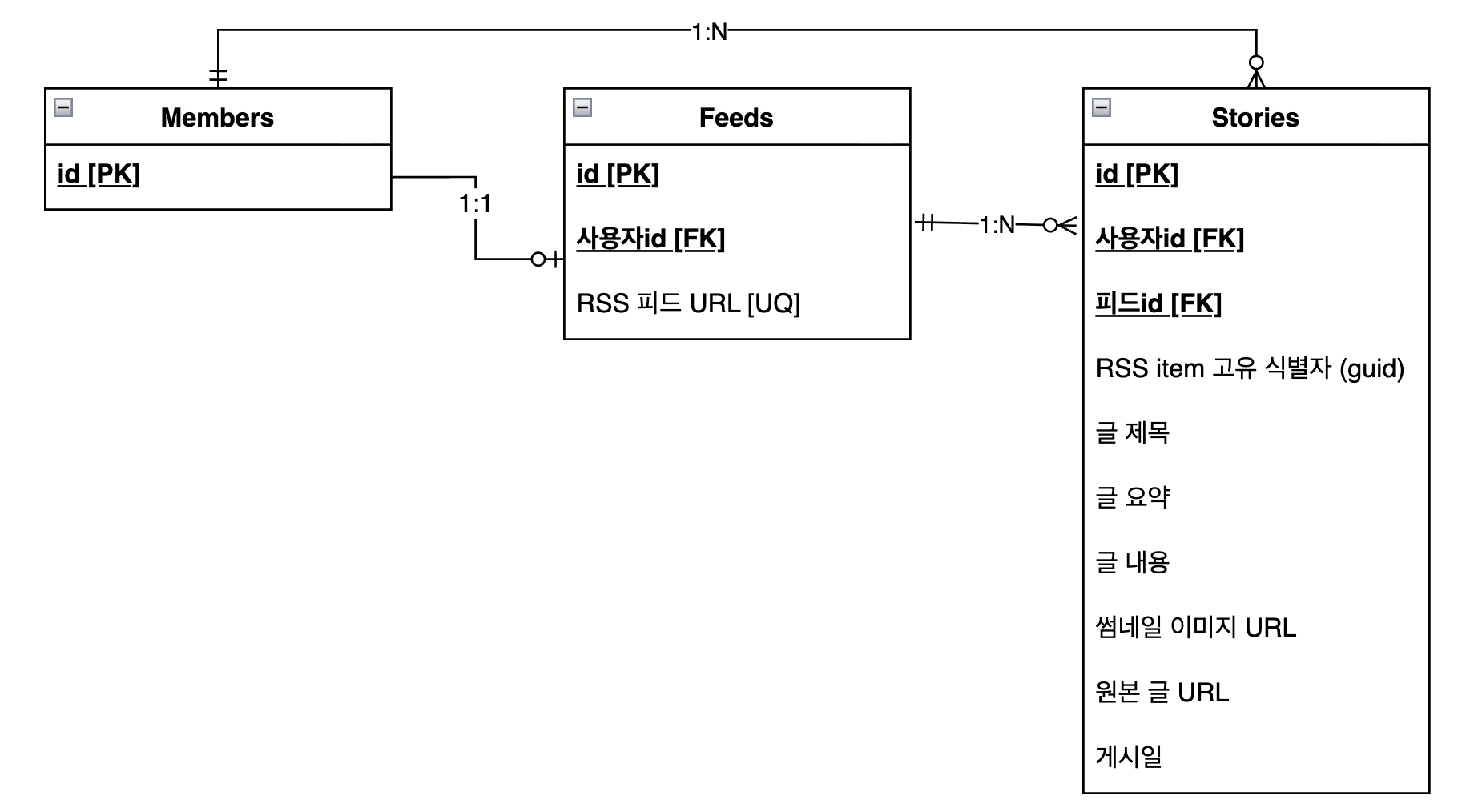
설명을 위해 ERD를 간소화했습니다.
Feed 엔티티 설계
먼저 어떤 블로그에서 글을 수집할 것인가를 정의하는 Feed 엔티티부터 살펴보겠습니다.
Feed 엔티티는 회원과 RSS 피드 URL을 연결하는 역할을 담당합니다.
각 회원이 자신의 블로그 RSS URL을 등록하면, 크롤러는 이 Feed 정보를 기반으로 주기적으로 새 글을 수집합니다.
Feed 엔티티 구조
class Feed {
id: bigint; // DB에서 자동 생성되는 고유 ID
memberId: string; // 회원 ID (Member 엔티티와 1:1 관계)
feedUrl: string; // RSS 피드 URL
}주요 필드 설명
- memberId
- Feed와 Member는 1:1 관계입니다.
- 유니크 제약 조건으로 한 회원당 하나의 피드만 등록 가능하도록 하기 위함입니다.
- 한 회원이 여러 블로그를 운영하는 경우는 초기 요구사항에 없어 단순하게 설계했습니다.
- feedUrl (RSS 피드 URL)
- RSS 피드의 실제 URL입니다. (예:
https://dongho-dev.tistory.com/rss) - 유니크 제약 조건으로 동일한 RSS URL이 중복 등록되는 것을 방지합니다.
- RSS 피드의 실제 URL입니다. (예:
Story 엔티티 설계
RSS 공통 모델에서 정의한 필드들을 바탕으로, 실제 서비스에서 사용할 Story 엔티티를 설계했습니다.
Story 엔티티는 단순히 RSS 데이터를 그대로 저장하는 것이 아니라, 서비스에서 필요한 추가 정보를 함께 담고 있습니다.
Story 엔티티 구조
class Story {
id: bigint; // DB에서 자동 생성되는 고유 ID
feedId: string; // 어느 피드에서 수집했는지 (Feed 엔티티와 관계)
// RSS 공통 모델에서 가져온 필드들
guid: string; // RSS 아이템 고유 식별자
title: string; // 글 제목
contents: string; // 본문 HTML (description에서 가져옴)
originalUrl: string; // 원문 링크 (link에서 가져옴)
publishedAt: Date; // 발행일 (pubDate를 UTC로 변환)
// 서비스를 위해 추가 가공한 필드들
summary: string; // 요약 (contents에서 slice해서 추출)
thumbnailUrl?: string; // 썸네일 이미지 URL (contents에서 추출)
}주요 필드 설명
- feedId
- Feed와 Story는 1:N 관계로, 하나의 Feed에서 여러 Story가 수집됩니다.
- Story는 Feed를 참조하여 “이 글이 어느 블로그에서 수집되었는지” 추적합니다.
- guid (글 고유 ID)
- RSS 피드에서 제공하는 각 글의 고유 식별자입니다.
- 중복 수집을 방지하는 데 사용됩니다. 같은
guid를 가진 글은 이미 수집된 것으로 판단합니다. - Tistory와 Velog는
guid가 글 URL과 동일하지만, 다른 플랫폼은 다를 수 있어 별도 필드로 관리합니다.
- title (글 제목)
- RSS의 태그에서 가져온 글 제목입니다.
- HTML 엔티티(
&,"등)를 디코딩하여 저장합니다.
- contents (본문 HTML)
- RSS의
<description>태그에서 가져온 글의 전체 내용입니다. - HTML 형식으로 저장됩니다.
- 이 필드에서 썸네일과 요약을 추출합니다.
- RSS의
- originalUrl (원문 링크)
- RSS의
<link>태그에서 가져온 글의 원본 URL 입니다. - 사용자가 글 상세를 보려 할 때 원본 블로그로 이동하는 링크로 사용됩니다.
- RSS의
- publishedAt (발행일)
- RSS의
<pubDate>태그에서 가져온 글의 작성 시각입니다. - 블로그마다 시간대가 다르므로(KST, GTM 등) UTC로 통일하여 저장합니다.
- 글 목록을 최신순으로 정렬할 때 사용됩니다.
- RSS의
- summary (요약)
- RSS에서 직접 제공하지 않는 필드로,
contents에서 추출하여 생성합니다. - HTMl 태그를 제거하고 본문 앞부분의 텍스트만 추출합니다. (150~200자)
- 글 목록 화면에서 미리보기 텍스트로 사용됩니다.
- RSS에서 직접 제공하지 않는 필드로,
- thumbnailUrl (썸네일 이미지 URL)
- RSS에서 직접 제공하지 않는 필드로,
contents의 HTML에서 첫 번째<img>태그를 찾아 추출합니다. - 이미지가 없는 글은
null값을 가집니다. - 글 목록 화면에서 썸네일로 표시됩니다.
- RSS에서 직접 제공하지 않는 필드로,
CreateStoryRequest DTO 설계
Story 엔티티를 설계했으니, 이제 RSS 데이터를 Story로 변환하기 위한 중간 계층인 CreateStoryRequest DTO를 살펴보겠습니다.
DTO 구조
interface CreateStoryRequest {
feedId: string; // 어느 피드에서 수집했는지
guid: string; // RSS 아이템 고유 식별자
title: string; // 글 제목
summary: string; // 요약 (HTML 태그 제거 후 생성)
contents: string; // 본문 HTML
thumbnailUrl?: string; // 썸네일 이미지 URL (선택)
originalUrl: string; // 원문 링크
publishedAt: string; // 발행일 (ISO 8601)
}이제 이 DTO를 활용해 실제 RSS 수집 파이프라인이 어떻게 동작하는지 살펴보겠습니다.
RSS 수집 파이프라인
파이프 라인 구조
수집 파이프라인은 크게 3단계로 구성되어 있습니다.
- RSS 피드 다운로드(Download)
- RSS 파싱(Parse)
- DB 저장(Store)
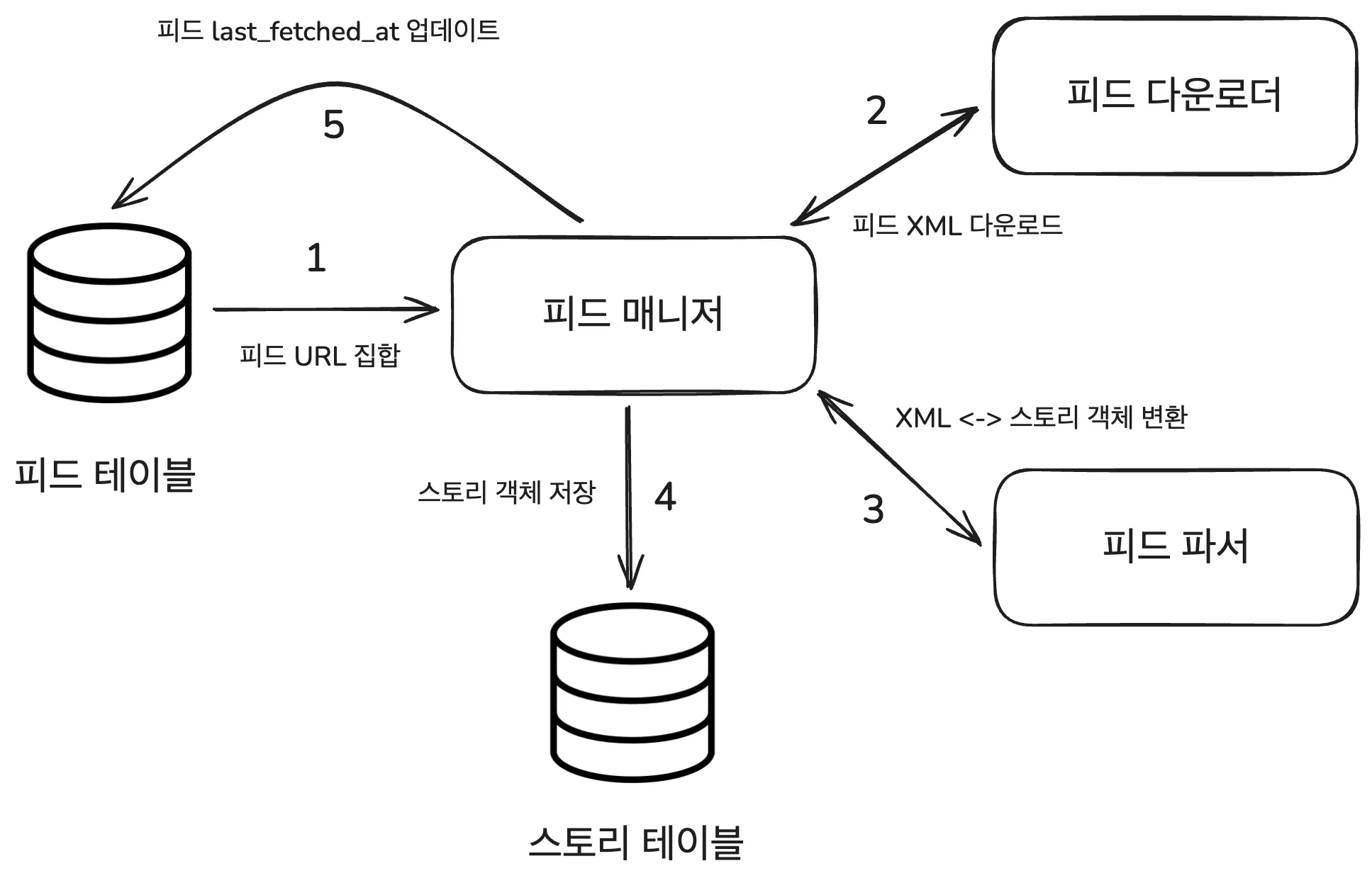
그리고 각 파이프라인 단계에 맞춰 컴포넌트를 분리했습니다.
- 피드 다운로더: 캠퍼 블로그의 RSS URL에 HTTP 요청을 보내 최신 글 데이터(XML)를 가져오는 역할
- 피드 파서: 다운로드한 RSS XML을
<item>단위로 파싱하고 CreateStoryRequest DTO로 변환하는 역할 - 피드 매니저: 다운로드와 파서의 중간 다리 역할
크롤러의 동작 과정을 정리하면 다음과 같습니다.
- 피드 테이블에서 피드 URL들을 조회합니다.
- 피드 URL들을 순회하며 피드 XML을 다운로드합니다.
- 다운로드 한 XML을
<item>단위로 파싱하고, CreateStoryRequest DTO로 정규화합니다. - DTO를 Story 엔티티로 변환하여 DB에 저장합니다.
- 정해진 시간마다 1~4번 과정을 반복합니다.
위 구조를 바탕으로, 이제 각 컴포넌트가 어떤 책임을 가지고 있고 어떤 기준으로 분리되었는지 하나씩 살펴보겠습니다.
피드 매니저 (Feed Manager)
피드 매니저는 수집 파이프라인의 오케스트레이터 역할을 담당하는 컴포넌트입니다.
다운로드와 파서를 직접 호출하며, 전체 수집 흐름을 제어하는 역할을 합니다.
동작 과정
피드 매니저는 다음과 같은 흐름으로 동작합니다.
- DB에서 활성화된 피드 URL 목록을 조회
- 각 URL을 다운로더에 전달해 XML 데이터 다운로드
- 파서에게 XML을 전달해 CreateStoryRequest DTO로 변환
- DTO를 Story 엔티티로 변환하고 저장소에 전달하여 저장
for (const feed of feeds) {
try {
const xml = await downloader.download(feed.feedUrl);
const stories = await parser.parse(xml, feed.id);
await this.createStories(stories);
} catch {
continue;
}
}위 스니펫은 피드 매니저의 핵심 흐름만 표현한 코드입니다.
다운로더 → 파서 → 저장으로 이어지는 파이프라인을 순차적으로 실행하며,
개별 피드에서 발생한 예외가 전체 수집을 중단하지 않도록 했습니다.
피드 다운로더 (Feed Donwloader)
피드 다운로더는 RSS URL로 HTTP 요청을 보내 원본 XML 데이터를 안정적으로 가져오는 역할을 담당합니다.
동작 과정
피드 다운로더는 다음과 같은 흐름으로 동작합니다.
- 전달받은 피드 URL로 HTTP GET 요청을 보냅니다.
- User-Agent 헤더를 명시해 크롤러 요청임을 알립니다. (예의 바른 크롤러)
- 30초 타임아웃을 설정해 무한 대기 상태를 방지합니다.
- 응답 상태 코드를 검증해 정상 응답(200)인지 확인합니다.
- 문제가 없다면 XML 원문을 반환합니다.
async download(feedUrl: string): Promise<string> {
const response = await axios.get(feedUrl, {
headers: { 'User-Agent': 'BoostUs-RSS-Crawler' },
timeout: 30000,
});
if (response.status !== 200) {
throw new Error(`HTTP ${response.status}`);
}
return response.data;
}이 과정에서 다운로더는 네트워크 통신에만 집중하고,
파싱이나 저장과 같은 이후 단계의 로직은 담당하지 않도록 분리했습니다.
피드 파서 (Feed Parser)
피드 파서는 다운로드된 XML 데이터를 분석해 CreateStoryRequest DTO로 변환하는 역할을 담당합니다.
초기에는 직접 XML을 파싱하는 방식을 고려했지만, 파싱 로직을 직접 구현하기에는 시간이 부족하다고 판단해서 rss-parser 라이브러리를 활용하는 방식을 선택했습니다.
선택 이유
- RSS 표준의 다양성
- RSS 2.0, Atom 등 여러 변형 존재
- 블로그마다 태그 구조가 미묘하게 다름
- 직접 구현 시 예외 케이스 처리 비용이 큼
- 안정성과 유지보수
- 이미 검증된 파서 로직 재사용
- 핵심 로직 집중
- “XML 해석”보다 “데이터 정규화”에 집중
- 서비스에 필요한 필드 가공 로직을 중심으로 구현
동작 과정
피드 다운로더는 다음과 같은 흐름으로 동작합니다.
- rss-parser를 이용해 XML 문자열을 Feed 객체로 변환합니다.
- Feed 객체의
items배열에서 개별 글 정보를 순회합니다. - 각 RSS Item을 CreateStoryRequest DTO 형식으로 변환합니다.
- 유효한 DTO 목록을 반환합니다.
async parse(xmlContent: string, feedId: string) {
const feed = await this.parser.parseString(xmlContent);
return feed.items
.map(item => this.convertToStory(item, feedId))
.filter(story => story !== null);
}전체 흐름을 파악했으니, convertToStory 메소드를 자세히 살펴보겠습니다.
DTO 변환 로직
convertToStory 메소드는 RSS 파서가 읽어 온 원본 Item을 CreateStoryRequest DTO로 변환하는 단계입니다.
private convertToStory(
item: RssItem,
feedId: string
): CreateStoryRequest | null {
// 1. 필수 필드 검증
if (!item.guid || !item.title) return null;
// 2. 본문 확보
const contents = item.content ?? '';
if (!contents) return null;
// 3. 데이터 정제 및 표준화
const summary = this.extractSummary(contents);
const publishedAt = item.pubDate
? new Date(item.pubDate).toISOString()
: new Date().toISOString();
// 4. 내부 DTO로 변환
return {
feedId,
guid: item.guid,
title: this.decodeHtmlEntities(item.title),
summary,
contents,
thumbnailUrl: this.extractImageUrl(contents),
originalUrl: item.link,
publishedAt,
};
}변환 과정을 단계별로 살펴보겠습니다.
- 필수 필드 검증:
guid,title,contents는 CreateStoryRequest를 구성하기 위한 최소 조건입니다.- 세 값 중 하나라도 누락된 데이터는 저장 가치가 없다고 판단해 변환 대상에서 제외합니다.
- 요약 추출:
- 원문 HTML(
contents)에서 불필요한 태그를 제거한 뒤, 본문 초반의 의미 있는 텍스트를 요약으로 생성합니다. - 이 요약은 서비스에서 글 목록 화면에서 사용됩니다.
- 원문 HTML(
- 발행일 표준화(UTC):
- RSS 피드의
pubDate는 블로그마다 형식이 제각각이어서 그대로 사용하기 어렵습니다. - 파싱 후 ISO 형식의 UTC 시간으로 변환해 저장함으로써 일관성을 확보했습니다.
- 발행일이 없는 경우에는 수집 시점을 기준으로 대체합니다.
- RSS 피드의
- CreateStoryRequest DTO로 변환:
- 검증과 가공이 끝난 데이터는 CreateStoryRequest DTO 형태로 변환됩니다.
- 이 DTO는 이후 Story 엔티티로 변환되어 DB에 저장됩니다.
RSS 크롤러에서 데이터베이스 접근은 어떻게 할까?
이제 남은 것은 변환된 CreateStoryRequest DTO를 Story 엔티티로 바꾸고 데이터베이스에 저장하는 과정이었습니다.
여기서 한 가지 고민이 생겼습니다.
“RSS 크롤러가 데이터베이스에 어떻게 접근하는 게 맞을까?”
boostus에서는 원래 API 서버에서만 데이터베이스 접근을 담당하고 있었고,
크롤러는 단순히 RSS를 수집하는 별도 모듈로 분리되어 있었습니다.
처음에는 크롤러 안에서 바로 Story 엔티티를 만들어 DB에 넣는 방식도 생각했습니다.
하지만 그렇게 하면 DB에 접근하는 코드가 두 곳으로 늘어나면서 구조가 복잡해질 것 같았습니다.
- 중복 글 체크 로직이 두 군데에 생길 수 있고
- 저장 규칙이 달라질 위험도 있고
- 나중에 구조를 바꿀 때 수정 범위가 커질 것 같았습니다.
그래서 저는 크롤러는 저장까지 책임지지 않는 게 맞다고 판단했습니다.
데이터 접근 방식은?
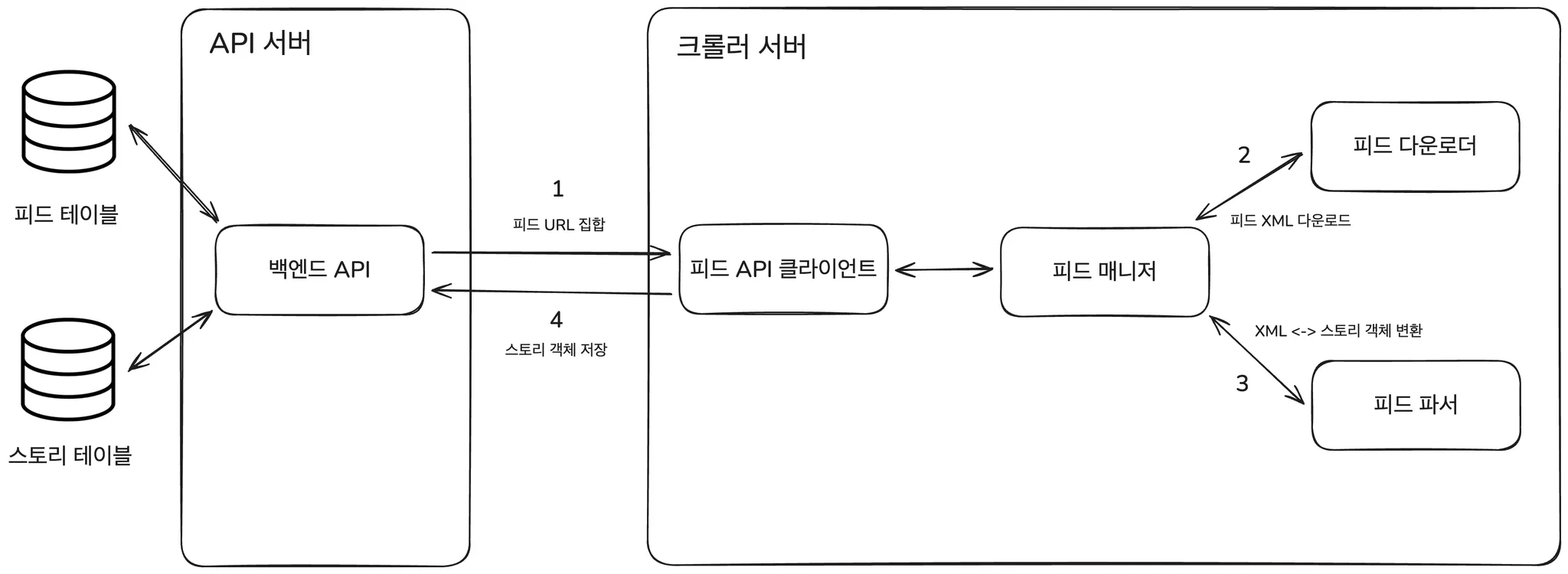
크롤러는 DB를 직접 건드리지 않고, 이미 존재하는 API 서버의 기능을 그대로 사용하기 위해
BE REST API를 통한 통신 방식을 선택했습니다.
GET /api/feeds: 수집 대상 피드 조회POST /api/stories: 수집된 스토리 저장
구체적으로는 크롤러 쪽에 피드 API 클라이언트를 추가해서,
- 크롤러는 RSS를 파싱해
CreateStoryRequest DTO까지만 만든다. - 그 DTO를 POST /api/stories로 API 서버로 보낸다.
- 실제 검증과 DB 저장은 기존 StoryService가 담당한다.
이렇게 하니 DB 스키마도 한 곳에서 관리할 수 있어서 구조가 깔끔해졌습니다.
중복 데이터는 어떻게 방지할까?
RSS 크롤러를 만들면서 생겼던 또 다른 고민은 중복 수집을 어떻게 막을지 였습니다.
RSS는 최신 글을 계속해서 다시 내려주는 구조라, 같은 글이 여러 번 데이터베이스에 저장될 가능성이 높았습니다.
그래서 “어떤 기준으로 같은 글이라고 판단할 것인가?”를 정의해야 했습니다.
1. guid 기준 upsert
Tistory와 Velog의 RSS에는 글을 식별할 수 있는 guid 필드가 있었습니다.
이 값은 바로 블로그 글의 원문 URL이었습니다.
| 플랫폼명 | guid 예제 |
|---|---|
| Tistory | https://dongho-dev.tistory.com/58 |
| Velog | https://velog.io/@dongho18/글-제목 |
그래서 동일한 guid가 있으면 기존 글을 업데이트하고, 존재하지 않으면 새로운 글을 생성하는 upsert 전략을 적용했습니다.
하지만 설계를 하면서 한 가지 의문이 들었습니다.
“정말 guid 값만으로 모든 경우를 구분할 수 있을까?”
guid 필드는 같은 플랫폼 내에서는 유일하게 식별이 될 수 있지만, 다른 블로그 플랫폼으로 확장이 될 경우 전역적으로 유일하다고 보장할 수 없었습니다.
2. feedId + guid 기준 upsert
설명을 위해 ERD를 간소화했습니다.
그래서 guid 하나만으로는 안전하지 않다고 판단해서, feedId를 추가해서 upsert를 하는 전략으로 변경했습니다.
이렇게 하면 동일한 피드 안에서는 guid로 글을 구분하고, 서로 다른 피드의 동일 guid는 다른 글로 취급할 수 있습니다.
그리고 DB에는 feedId + guid에 UNIQUE 제약 조건을 걸어 데이터 무결성을 보장했습니다.
전체 흐름 정리
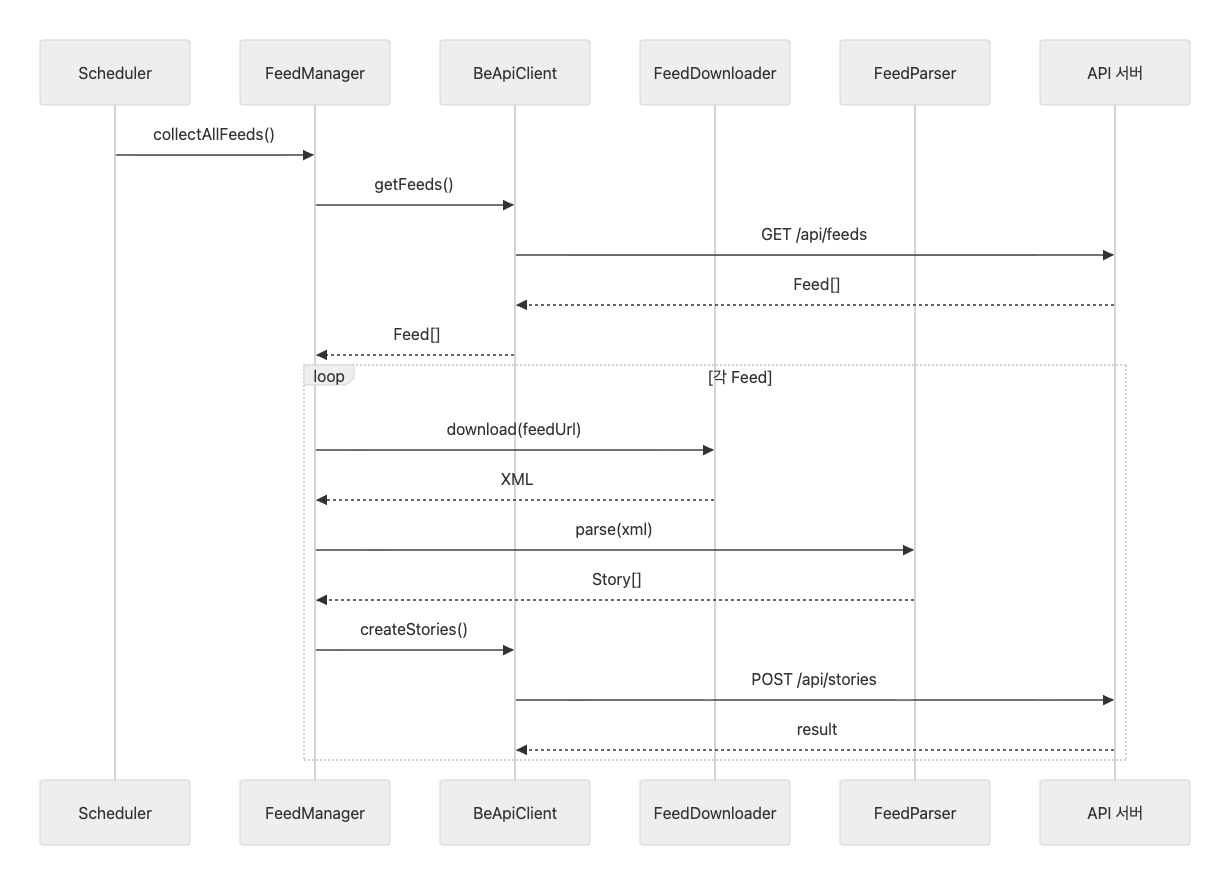
내용이 길었는데 전체 흐름을 정리해보겠습니다.
- BE API로부터 수집 대상 피드 목록 조회
- 크롤러는 DB를 직접 보지 않고,
GET /api/feedsAPI를 통해 어떤 블로그를 수집해야 하는지 받아옵니다.
- 크롤러는 DB를 직접 보지 않고,
- 각 피드 URL에서 RSS 다운로드
- 받아온 URL에 HTTP GET 요청을 보내 RSS XML을 가져옵니다.
- RSS 파싱 및 도메인 변환
- RSS 2.0 형식을 기준으로 XML을 파싱하고,
- 각
<item>을CreateStoryRequest DTO로 변환해 Story 배열을 생성합니다.
- BE API로 저장 요청
- 변환된 Story 배열을 순회하며
POST /api/stories로 전송합니다. - 이때
feedId + guid기준 upsert 전략으로 중복 저장을 방지합니다.
- 변환된 Story 배열을 순회하며
남은 도전 과제
기본 기능은 동작하지만, 실제 운영을 생각하면 보완할 점이 많이 남아 있습니다.
1. 무례하지 않은 크롤러 만들기
지금은 하나의 블로그에 연속된 요청을 보내는 구조라, 블로그 서버에 부담을 줄 가능성이 있습니다.
캠퍼들의 블로그 게시 주기에 따라서 우선순위를 다르게 설정해서,
자주 글을 올리는 블로그는 조금 더 자주 확인하고 활동이 적은 블로그는 수집 주기를 길게 가져가는 방식도 고려할 수 있습니다.
2. 불필요한 업데이트 줄이기
현재 upsert 방식은 feedId + guid만 같으면 실제 변경이 없어도 업데이트가 발생해, DB 자원을 불필요하게 사용한다는 문제가 있습니다.
이를 개선하기 위해, 변경 감지 처리 방식을 고려해볼 수 있을 것 같습니다.
글의 제목이나 본문 내용을 해시 값으로 만들어 저장하고, 이전 해시와 다를 떄만 업데이트를 진행하는 식으로 개선해볼 수 있을 것 같습니다.
3. 재시도 전략
네트워크는 언제든 실패할 수 있기 때문에 안정적인 수집 구조가 필요합니다.
지금은 하나의 크롤러에서 파이프라인이 순차적으로 동작하다 보니,
중간 단계에서 오류가 발생한 실패한 피드는 다시 처음 단계부터 수집을 해야한다는 비효율이 존재합니다.
이를 개선하기 위해, exponential backoff와 재시도 횟수 제한을 둬서 일시적 네트워크 장애에 대응하고,
각 파이프라인 과정 사이에 메시지큐를 둬서 단계별로 분리된 구조를 고려할 수 있습니다.
4. 로깅 및 모니터링
문제가 생겼을 때 원인을 빠르게 찾기 위한 장치도 부족합니다.
현재는 각 파이프라인의 성공/실패 과정을 console.log 혹은 console.error 로만 남기고 있어서,
서버가 재시작 되면 이전 실행 기록이 모두 사라진다는 문제가 있습니다.
이를 개선하기 위해, 피드 단위로 수집 이력을 저장하고 문제가 발생했을 때 어느 단계에서 어떤 이유로 실패했는지 바로 확인할 수 있는 구조를 고려하고 있습니다.
5. 플랫폼 확장
마지막으로 Tistory와 Velog 외에 Github Pages나 자체 제작 블로그까지 지원 범위를 넓히는 것도 고려하고 있습니다.
하지만 Github Pages나 자체 제작 블로그들은 개발자가 RSS 표준을 따르지 않아 RSS 필드 구성이 제각각일 가능성이 높습니다.
따라서 RSS 피드 URL을 등록하기 전에, 우리 서비스가 요구하는 공통 스펙을 만족하는지 검증하는 단계가 필요하다고 판단했습니다.
참고 자료
