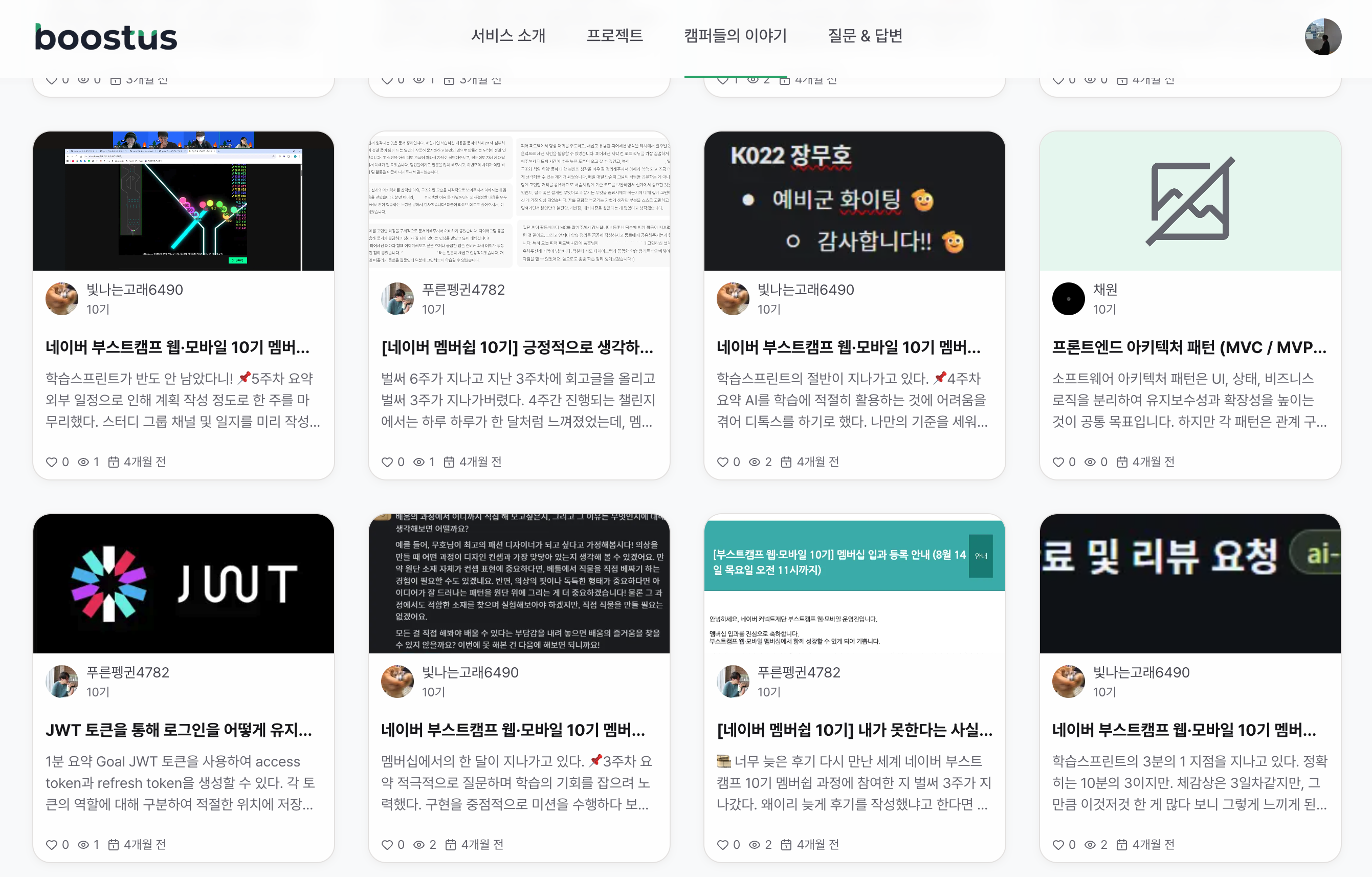
부스트캠프 커뮤니티 서비스 boostus에는 ‘캠퍼들의 이야기’라는 공간이 있습니다.
캠퍼들이 각자 운영하는 블로그 글을 모아 한 곳에 볼 수 있게 만든 피드인데
처음엔 그냥 글 목록 하나 뿌려주면 끝날 줄 알았습니다.
그런데 글이 쌓이고, 정렬 조건이 붙고, 무한 스크롤까지 지원하면서
단순한 조회 API가 점점 복잡한 문제로 변하기 시작했습니다. 🤯
그냥 다 가져오면 안 되나요?
커뮤니티 서비스에 올라오는 글들을 불러오는 가장 쉬운 방법은 뭘까요?
SELECT * FROM posts맞습니다. 그냥 전부 가져오면 됩니다.
개발 초반에는 이 방식이 가장 단순하고 빠릅니다. 데이터가 많지 않을 때는 문제도 거의 없습니다.
하지만 캠퍼들의 글이 늘어나면서 문제가 생기기 시작합니다.
- 게시물이 늘어날수록 한 번의 요청에 불러오는 데이터 양 증가
- 사용자가 보지도 않을 데이터까지 전송되는 네트워크 낭비
- 프론트 목록 페이지 로딩 속도 저하
- 서버 메모리 부하 증가
그래서 데이터를 ‘나눠서’ 가져오는 페이지네이션이 필요했습니다.
어떤 방식으로 나눠서 가져올까?
데이터를 나눠서 가져온다는 어떤 의미일까요?
전체 게시물이 10,000개라고 해서, 사용자에게 한 번에 10,000개를 모두 보여줄 필요는 없습니다.
대부분의 사용자는 첫 화면에서 10~20개의 글만 보고, 필요할 때 조금 더 내려서 다음 글을 확인합니다.
- “지금 사용자에게 필요한 만큼만 가져오자”
이를 구현하기 위해 필요한 개념이 바로 페이지네이션(Pagination) 입니다.
페이지네이션은 크게 두 가지 방식으로 나눌 수 있습니다.
- 몇 번째 페이지인지 기준으로 가져오는 방식
- 마지막으로 본 데이터 기준으로 가져오는 방식
저희 팀은 이 두 방식을 두고 어떤 방법이 더 적합할지 고민했습니다.
Offset 기반 페이지네이션
페이지네이션을 구현하는 가장 간단한 방법은 Offset 방식입니다.
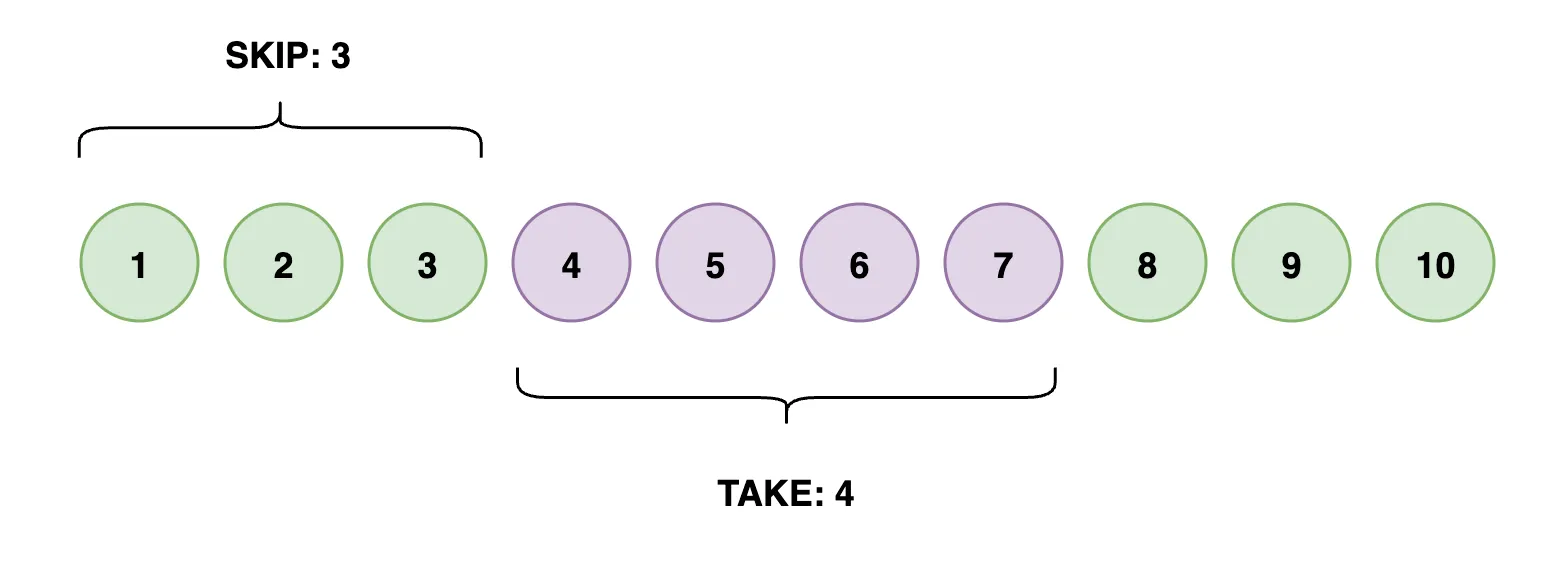
Offset 방식의 핵심은 앞의 N개를 건너뛰고 그 다음부터 읽는 것입니다.
이를 MySQL 기준으로 쿼리문을 작성해보면 다음과 같습니다.
SELECT *
FROM posts
ORDER BY published_at DESC
LIMIT 4
OFFSET 3;- 위 쿼리문은 3개의 행을 건너뛰고 그 다음부터 4개의 게시글을 가져온다 라는 의미입니다.

이를 조금 응용해서 하나의 페이지에 20개의 글을 보여주고, 6번째 페이지의 글을 보여주고 싶다면 아래와 같이 쿼리문을 작성할 수 있습니다.
SELECT *
FROM posts
ORDER BY published_at DESC
LIMIT 20
OFFSET 100;- OFFSET = (페이지 번호 - 1) x 페이지 크기
Offset 방식은 단순하고 직관적이지만, 서비스가 커질수록 몇 가지 문제점들을 만나게 됩니다.
문제점 1) 페이지가 뒤로 갈수록 느려진다
SELECT *
FROM posts
ORDER BY published_at DESC
LIMIT 20
OFFSET 100000;위 쿼리문은 겉보기에는 100,000개의 데이터를 건너뛰고 20개만 가져오는 효율적인 작업처럼 보입니다.
하지만 데이터베이스는 내부적으로 다음과 같이 동작합니다.
- 앞의 100,000개 행을 하나하나 확인한다
- 100,000번째 행에 도달했을 때 20개의 데이터를 읽는다
- 그 20개만 결과로 반환한다
즉, OFFSET의 값이 커질수록 DB가 실제로 읽어야 하는 데이터 양도 함께 증가합니다.
게시물이 수십만 건, 수백만 건으로 늘어나면 응답 속도가 급격히 느려질 수 밖에 없는 구조입니다.
그렇다면 데이터베이스는 왜 이런 방식으로 동작할 수 밖에 없을까요?
이유는 OFFSET이 “몇 번째 행인지”를 기준으로 동작하기 때문입니다.
데이터베이스 입장에서는 100,000번째 행이 어디인지 바로 알 수 있는 방법이 없습니다.
책으로 비유하면 페이지 번호가 없는 책에서 특정 페이지를 펴달라고 요청하는 것과 비슷합니다.
어떤 사람에게 두꺼운 책을 주고 정확히 “987번째 페이지를 펼쳐서 보여주세요”라고 하면,
한 장 한 장 넘기며 세어볼 수밖에 없겠죠. 🥲
문제점 2) 데이터 중복 또는 누락이 발생할 수 있다
Offset 방식의 또 다른 치명적인 단점은 페이지를 이동하는 사이에 데이터가 변하면 결과가 꼬일 수 있다는 점입니다.
예를 들어 이런 상황이 있을 수 있습니다.
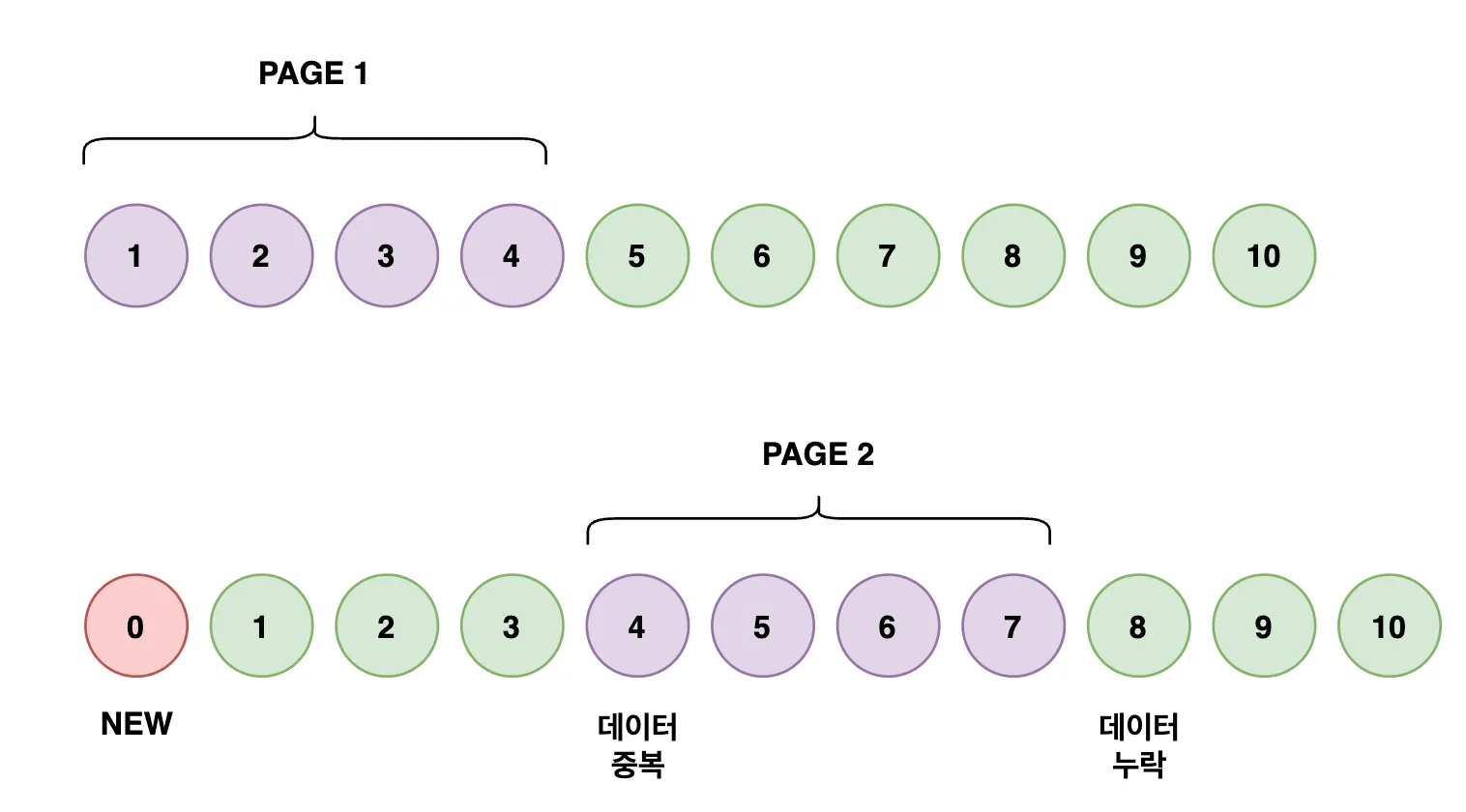
- 사용자가 1페이지를 조회한다. → (
1, 2, 3, 4) - 그 사이에
0번 게시글이 새로 추가된다. - 사용자가 2페이지를 조회한다. → (
4, 5, 6, 7)
우리가 원하는 2페이지의 결과값은 (5, 6, 7, 8) 인데, 실제로는 (4, 5, 6, 7) 이 반환됩니다.
즉, 4번 게시글은 1페이지에서도 보고 2페이지에서도 또 보게 되는 중복 현상이 발생합니다.
그리고 8번 게시글은 원래 2페이지에 있어야 하는데 사라져서 보지 못하는 누락 현상이 발생합니다.
Cursor 기반 페이지네이션
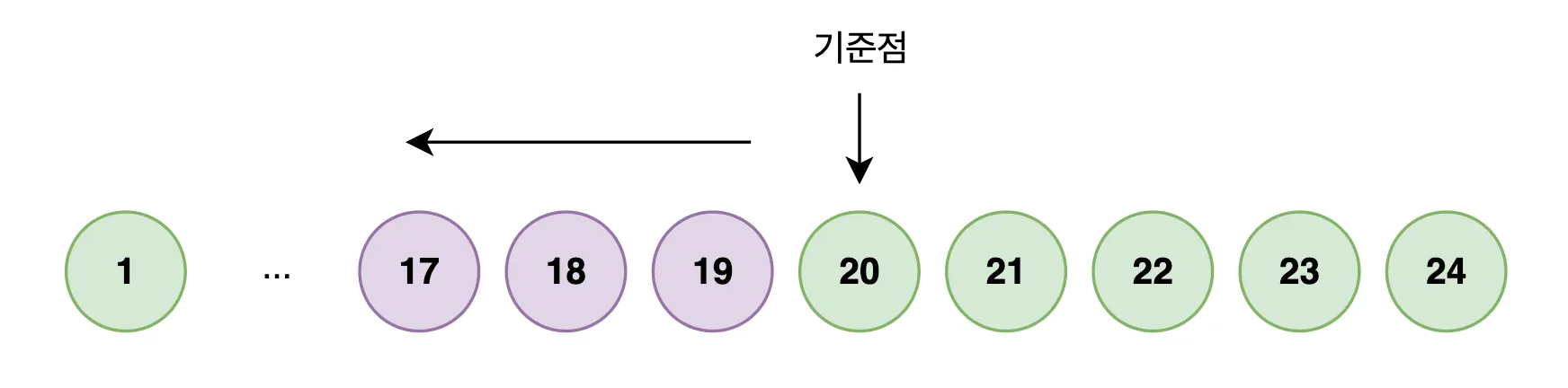
이 문제를 해결하기 위해서는 “몇 번째 행”이 아니라 “마지막으로 본 행”을 기준으로 그 다음 데이터를 가져오는 방식이 필요합니다.
이 개념이 바로 Cursor 기반 페이지네이션 입니다.
그렇다면 어떻게 “마지막으로 본 행”을 정확하게 특정할 수 있을까요?
바로 데이터베이스의 기본키(PK) 또는 유니크(Unique)한 값을 사용하는 것입니다.
예를 들어 id를 기준으로 최신순을 정렬하고 싶다면, 마지막으로 본 게시글의 id 값을 기억해두었다가 이렇게 조회할 수 있습니다.
SELECT *
FROM posts
WHERE id < 20
ORDER BY id DESC
LIMIT 10;만약 그 사이에 새로운 글이 추가된다면?
Offset 방식에서는 전체 행 번호가 밀려 중복이나 누락이 발생했지만,
Cursor 방식에서는 기준이 “위치”가 아니라 “값”이기 때문에 새로운 글이 올라와도 영향을 전혀 받지 않습니다.
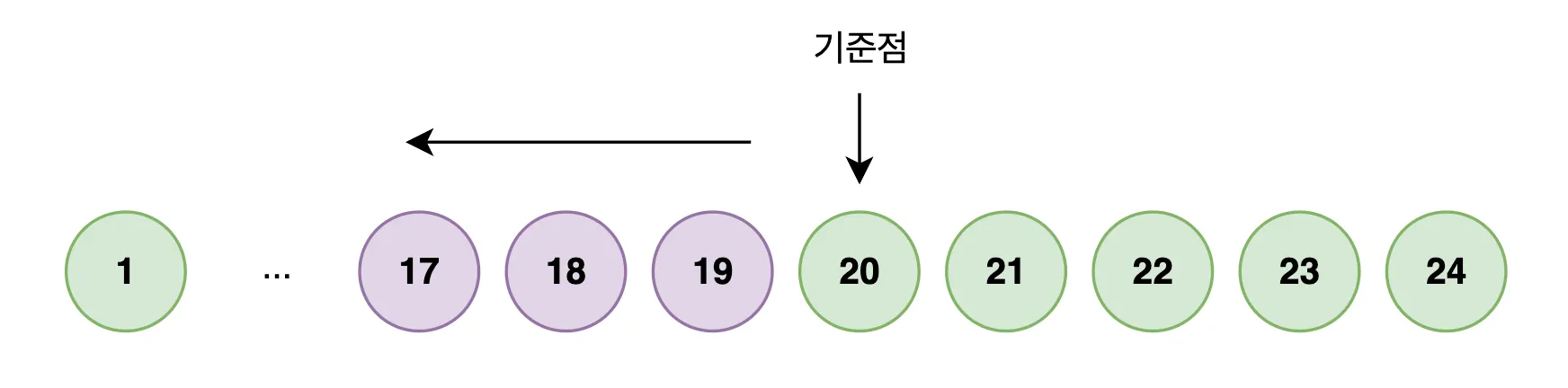
새 글이 추가되어도 id < 20 조건은 그대로이고, 중간 글이 삭제되어도 다음 조회 범위는 변하지 않습니다.
페이지가 뒤로 갈수록 느려질까?
그렇다면 Cursor 방식에서는 뒤쪽 페이지가 갈수록 성능이 느려지는 문제가 없을까요?
SELECT *
FROM posts
WHERE id < 1000
ORDER BY id DESC
LIMIT 10;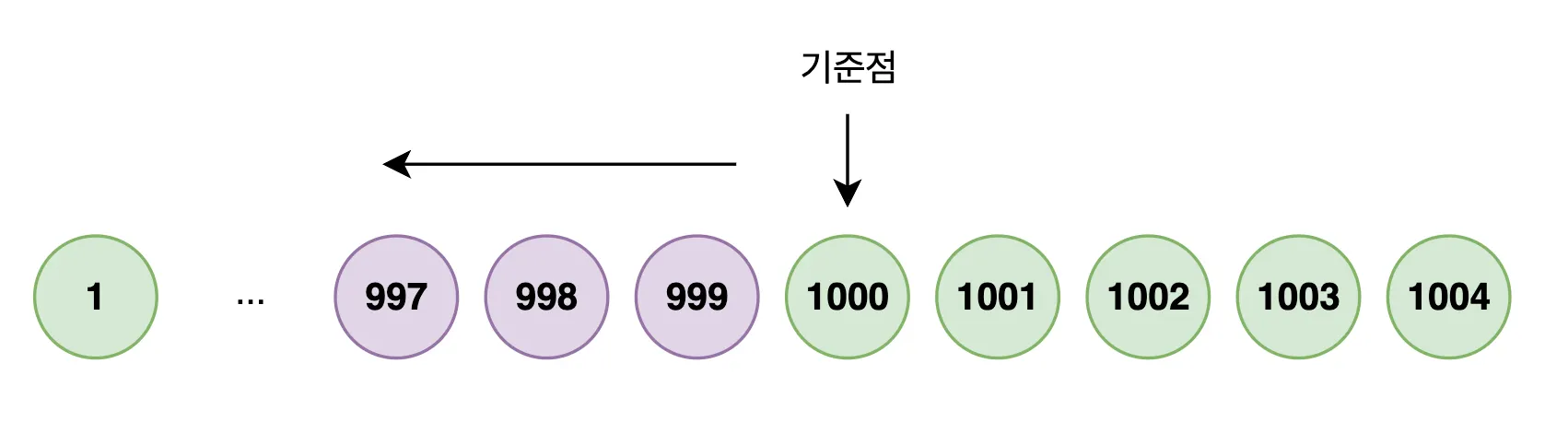
id가 PK라면 대부분의 RDBMS에서는 자동으로 인덱스가 생성되어 있습니다.
이 경우 데이터베이스는 테이블 전체를 훑는 것이 아니라 B-Tree 인덱스에서 조건에 맞는 위치를 바로 탐색합니다.
동작 과정을 풀어서 설명해보겠습니다.
- 인덱스에서
id = 1000이전 위치를 찾는다. - 그 지점부터 정렬된 순서대로 10개만 읽는다.
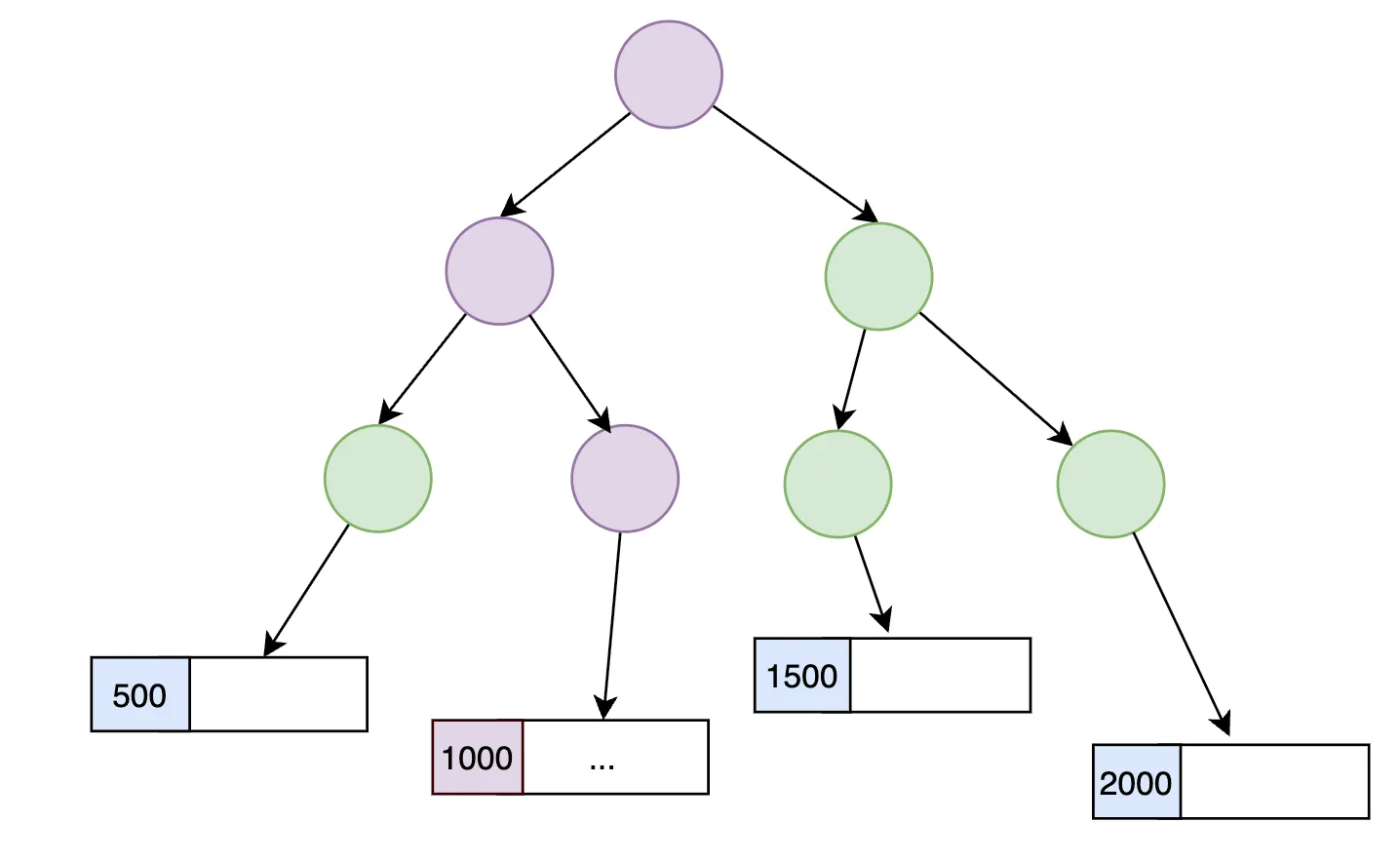
어떻게 id가 1000인 위치를 바로 찾을 수 있을까요?
인덱스는 단순히 값들을 쭉 나열해 둔 배열이 아니라, 책의 목차처럼 계층적인 구조로 정렬되어 있습니다.
그래서 전체 데이터를 처음부터 끝까지 보는 대신, 이진 탐색과 비슷한 방식으로 빠르게 위치를 찾아갈 수 있습니다.
그래서 데이터가 100만 개이든, 1000만 개이든, 1억 개이든 id가 1000인 값을 O(log N)의 시간만에 찾을 수 있습니다.
boostus 데이터 구조
이제 Cursor 기반 페이지네이션에 대해 어느 정도 알아보았으니,
실제로 boostus에 페이지네이션을 구현하면서 만났던 문제들을 정리해보겠습니다.
처음에는 “커서 = id 하나면 끝 아닌가?” 라고 생각했습니다.
근데 요구사항을 보니 전혀 아니었습니다. 🫠
게시글 테이블은 대략 다음과 같은 구조였습니다.
PK id는 auto increment를 사용했고, 등록일(published_at), 조회수(view_count), 좋아요(like_count)가 포함되어 있습니다.

그리고 지원해야 하는 정렬 조건은 크게 세 가지 였습니다.
- 최신순
- 조회수순
- 좋어요순
최신순 정렬
우선 최신순으로 정렬을 하기 위해 아래와 같이 쿼리문을 작성했습니다.
WHERE id < ?
ORDER BY id DESC
LIMIT 10;하지만 문제가 생겼습니다.
id가 최신순을 보장하지 않는 구조였기 때문입니다.
boostus의 ‘캠퍼들의 이야기’는 다른 도메인과 다르게,
캠퍼들의 블로그(외부)에서 데이터를 수집해오는 구조였기에 과거 글이 뒤늦게 추가되는 경우도 많았습니다.
즉, 글이 생성되는 시점(id 생성 시점)과 실제로 사용자가 글을 작성한 날짜(published_at)이 항상 일치하지 않았죠.
그래서 최신순의 기준을 id가 아닌 published_at 으로 잡기로 하고 쿼리문을 수정했습니다.
WHERE published_at < ?
ORDER BY published_at DESC
LIMIT 10;새로운 문제: published_at 가 같을 때
published_at 기준으로 바꾸고 나니 또 다른 문제가 보였습니다.
같은 시각에 발행된 글들이 존재할 수 있다는 점이었습니다.
예를 들어 아래와 같은 데이터가 있다고 가정하고 사용자가 1페이지에서 id=30을 마지막으로 봤다고 한다면

우리가 원하는 다음 데이터는 29이지만, 같은 시각의 행들은 전부 건너뛰어 버리고 28번 글부터 가져오게 됩니다.
WHERE published_at < '2024-03-02 14:00:00'
ORDER BY published_at DESC해결: 보조 키로 id를 함께 사용
그래서 정렬 기준에 id를 보조 키로 추가했습니다.
WHERE
published_at < ?
OR (published_at = ? AND id < ?)
ORDER BY published_at DESC, id DESC
LIMIT 10;이렇게 하면
published_at이 더 이전인 글- 같은
published_at이면 id가 더 작은 글
순서로 정확하게 다음 페이지 기준을 잡을 수 있습니다.
조회수/좋아요순 정렬
최신순은 그래도 published_at + id 조합으로 정리가 됐는데,
조회수순과 좋아요순은 한 단계 더 까다로웠습니다.
조회수와 좋아요순은 정렬 기준을 아래와 같이 잡았습니다.
view_count(혹은like_count)published_atid
그리고 커서 조건을 이런 구조로 만들었습니다. (조회수 예시)
WHERE
view_count < :cursorViewCount
OR (
view_count = :cursorViewCount
AND published_at < :cursorPublishedAt
)
OR (
view_count = :cursorViewCount
AND published_at = :cursorPublishedAt
AND id < :cursorId
)
ORDER BY view_count DESC, published_at DESC, id DESC
LIMIT 10;처음엔 조건이 너무 복잡해져서 과한 거 아닌가 싶었는데
조회수가 같고, 같은 시간에 발행된 글이 여러개여도 항상 다음 글 하나를 특정할 수 있었습니다.
새로운 문제: 데이터 Full Scan
커서 조건까지 정리하고 나니 이제 다 끝난 줄 알았는데요..
로컬에서 테스트할 때도 잘 동작하고, 페이지 넘길 때 중복과 누락도 발생하지 않았습니다.
하지만 갑자기 문득 이런 생각이 들었습니다.
“이렇게 복잡한 WHERE 조건이면 DB가 인덱스를 안 타고 다 뒤지는 거 아닐까?”
그래서 바로 실행 계획을 찍어보았습니다.
EXPLAIN
SELECT *
FROM stories
WHERE
view_count < 10
OR (
view_count = 10
AND published_at < '2026-02-03'
)
OR (
view_count = 10
AND published_at = '2026-02-03'
AND id < 200
)
ORDER BY view_count DESC, published_at DESC, id DESC
LIMIT 10;[실행 결과]
| id | type | possible_keys | key | rows | filtered | Extra |
|---|---|---|---|---|---|---|
| 1 | ALL | PRIMARY | NULL | 121 | 35.57 | Using where; Using filesort |
possible_keys: PRIMARY- 옵티마이저는 PRIMARY 인덱스를 사용할 수 있다는 걸 알고 있습니다.
- PRIMARY는 이 쿼리에서 사용할 수 있는 인덱스 후보입니다.
key: NULL- 그럼에도 불구하고 옵티마이저는 인덱스를 사용하지 않기로 결정했습니다.
type: ALL- 결국 옵티마이저는 풀 테이블 스캔을 선택했습니다.
filtered- 옵티마이저는 이 쿼리가 전체 데이터(121건)의 약 36%, 즉 44건 정도를 반환할 것이라고 예측했습니다.
Extra: Using where; Using filesort- WHERE로 필터링하고 정렬은 메모리로 처리한다는 뜻입니다.
- 즉, 데이터가 많아지면 정렬 단계에서 CPU와 메모리를 꽤 잡아먹을 가능성이 높습니다.
문제 해결: 복합 커서 인덱스 추가
그래서 인덱스를 추가해서 문제를 해결했습니다.
지금 조회수순 정렬 기준이 viewCount → publishedAt → id 순서였는데,
테이블에는 이 순서대로 만들어진 인덱스가 없었습니다.
그래서 아래처럼 복합 인덱스를 추가했습니다.
CREATE INDEX stories_view_count_published_at_id_idx
ON stories (view_count DESC, published_at DESC, id DESC);그리고 똑같은 쿼리문에 대해서 실행 계획을 돌려보았습니다.
[실행 결과]
| id | type | possible_keys | key | rows | filtered | Extra |
|---|---|---|---|---|---|---|
| 1 | range | PRIMARY, stories_view_count_published_at_id_idx | stories_view_count_published_at_id_idx | 137 | 100 | Using index condition; Backward index scan |
type: range- 옵티마이저는
stories_view_count_published_at_id_idx인덱스를 사용해 특정 범위만 스캔했습니다.
- 옵티마이저는
filtered: 100- 옵티마이저는 인덱스로 걸러낸 행들이 사실상 WHERE 조건을 거의 그대로 만족할 거라고 판단했습니다.
Extra: Using index condition; Backward index scan- 조건 비교가 테이블이 아니라 인덱스 레벨에서 처리되었습니다.
- 정렬도
view_count DESC, publishedAt DESC, id DESC순서 그대로 인덱스를 뒤에서부터 읽는 방식이라 별도의filesort가 발생하지 않았습니다.
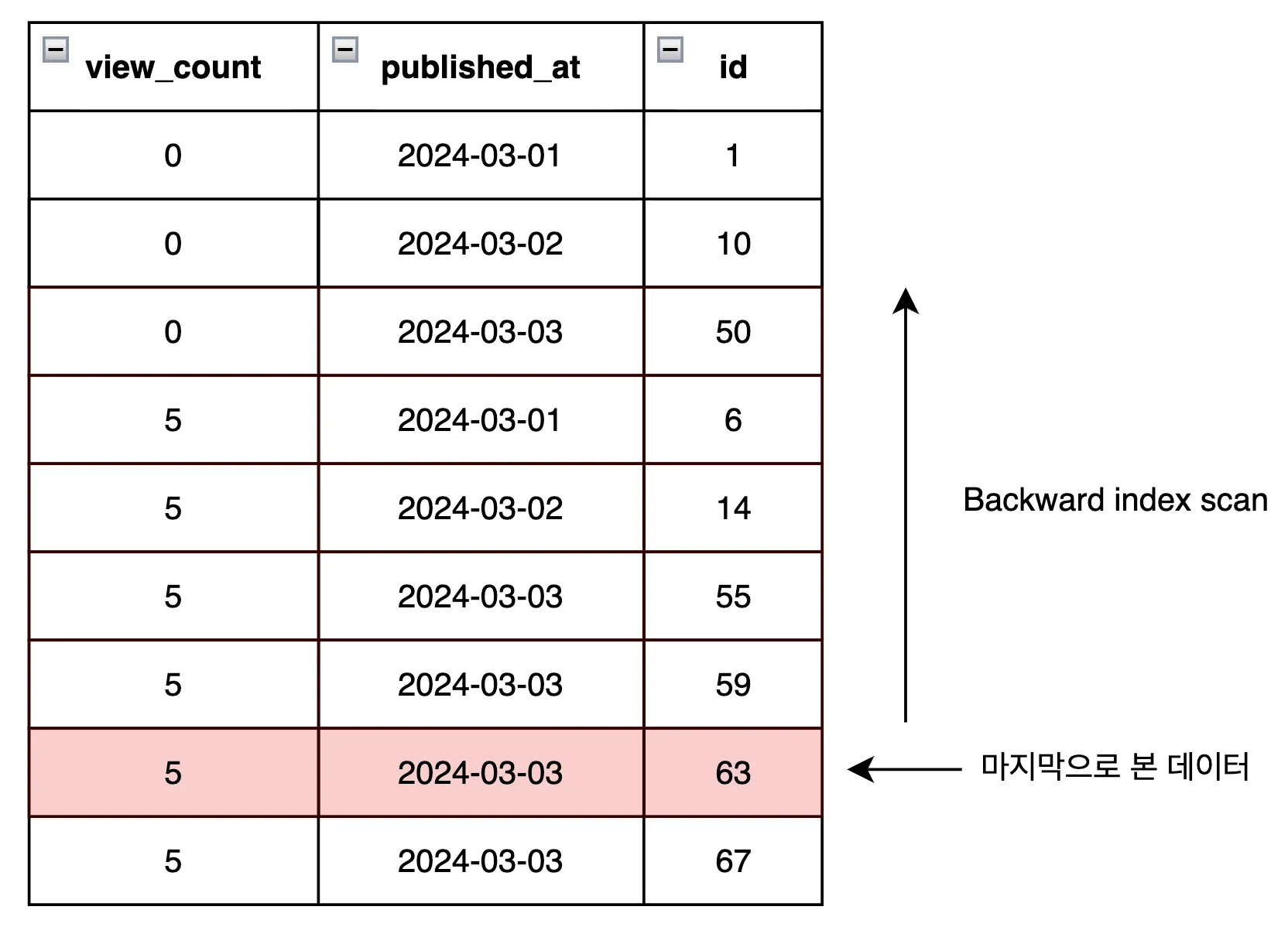
이해를 돕기 위해 인덱스를 그림으로 시각화 해보았습니다.
만약 마지막으로 본 데이터가 id=63 이라면 DB는 다음과 같이 동작합니다.
- 인덱스에서
view_count = 5, published_at = ‘2024-03-03’, id = 63****위치를 먼저 찾습니다. - 그 지점부터 정렬 기준(
view_count DESC → published_at DESC → id DESC) 방향으로 - 딱 10개만 순서대로 읽습니다. (
limit 10)
여기서 중요한 점은 index는 이미 우리가 원하는 정렬 순서대로 정돈되어 있다는 것입니다.
그래서 DB는 데이터를 전부 꺼내서 다시 정렬할 필요가 없기 때문에 데이터가 아무리 많아져도 일정한 성능을 유지할 수 있게 됩니다.
마무리하며
boostus 무한 스크롤을 구현하면서 DB 복습을 제대로한 것 같네요.
커서 기반 페이지네이션은 개념만 보면 단순한데,
실제 서비스 요구사항에 맞추려니 생각할 게 정말 많았네요.
아직 완벽한 구조라고는 못 하겠지만,
적어도 왜 이렇게 설계했는지는 설명할 수 있는 상태가 됐다는 점에서 뿌듯합니다.
그러면 이만 글을 마치겠습니다!
도움이 되셨다면 댓글, 좋아요 부탁드릴게요~ 👍🏻
