1. 삽입정렬 (Insertion Sort)
삽입 정렬은 가장 간단한 정렬 방식으로 이미 순서화된 파일에 새로운 하나의 레코드를 순서에 맞게 삽입시켜 정렬한다.
-
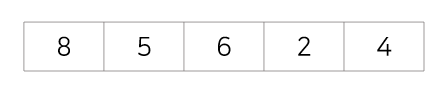
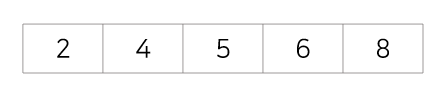
초기상태: 아래의 8,5,6,2,4를 삽입정렬을 사용해 정렬시키면 아래와 같은 과정을 거치게 된다.
-
1회전 : 두번째 값을 첫번째 값과 비교해 첫번째 자리에 삽입, 8을 뒤로 한칸 이동
-
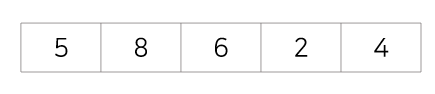
2회전 : 세번째 값을 5,6과 비교해 삽입, 8을 뒤로 한칸 이동
-
3회전 : 네번째 값을 5,6,8과 비교해 삽입, 5,6,8을 뒤로 한칸 이동
-
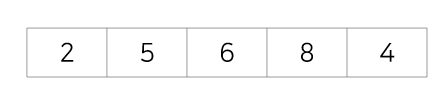
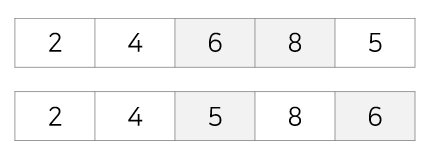
4회전 : 다섯번째 값을 2,5,6,8과 비교해 삽입, 5,6,8을 뒤로 한칸 이동

2. 쉘 정렬 (Shell Sort)
삽입 정렬을 확장한 개념이다.
- 입력 파일을 어떤 매개변수의 값으로 서브파일을 구성하고, 각 서브파일을 삽입 정렬 방식으로 순서 배열하는 과정을 반복하는 정렬 방식이다. 즉 임의의 레코드 키와 매개변수 값 만ㄴ큼 떨어진 곳의 레코드 키를 비교하여 순서화되어 있지 않으면 서로 교환하는 것을 반복하는 정렬 방식이다.
3. 선택 정렬 (Selection Sort)
선택 정렬은 n개의 레코드 중에서 최소값을 찾아 첫 번째 레코드 위치에 놓고, 나머지 (n-1)개 중에서 다시 최소값을 찾아 두 번째 레코드 위치에 놓는 방식을 반복하여 정렬하는 방식이다.
-
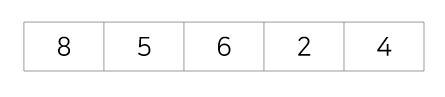
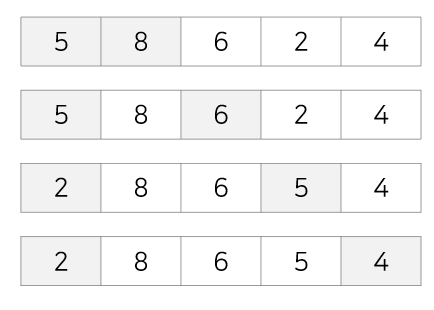
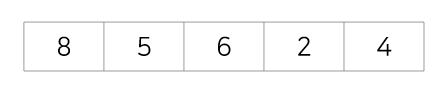
초기상태 : 아래의 8,5,6,2,4를 버블정렬을 사용해 정렬시키면 아래와 같은 과정을 거치게 된다.
-
1회전 : 첫번째 값 8을 두번째 값 5과 비교해 교환, 첫번째 값 5를 세번째 값 6과 비교해 교환X, 첫번째 값 5를 네번째 값 2와 비교해 교환, 첫번째 값 2를 다섯번째 값 4와 비교해 교환X
-
2회전 : 두번째 값 8을 세번째 값 6과 비교해 교환, 두번째 값 6을 네번째 값 5와 비교해 교환, 두번째 값 5를 다섯번째 값 4와 비교해 교환
-
3회전 : 세번째 값 8을 네번째 값 6과 비교해 교환, 세번째 값 6을 다섯번째 값 5와 비교해 교환
-
4회전 : 네번째 값 8을 다섯번째 값 6과 비교해 교환

4. 버블정렬 (Bubble Sort)
버블 정렬은 주어진 파일에서 인접한 두 개의 레코드 키 값을 비교하여 그 크기에 따라 레코드 위치를 서로 교환하는 정렬 방식이다.
-
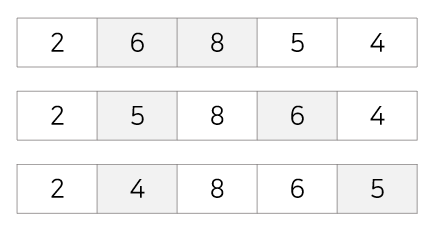
초기상태 : 아래의 8,5,6,2,4를 버블정렬을 사용해 정렬시키면 아래와 같은 과정을 거치게 된다.
-
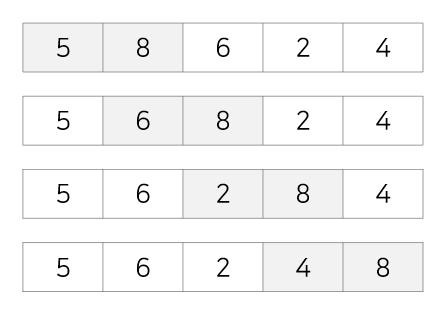
1회전 : 첫번째 값 8을 두번째 값인 5와 비교해 교환, 두번째 값 8을 세번째 값인 6과 비교해 교환, 세번째 값 8을 네번째 값인 2와 비교해 교환, 다섯번째 값인 4를 네번째 값인 8과 비교해 교환 (가장 큰 값이 가장 끝으로 가게 되므로 다음 회전부터는 맨 끝 값은 비교할 필요 없음)
-
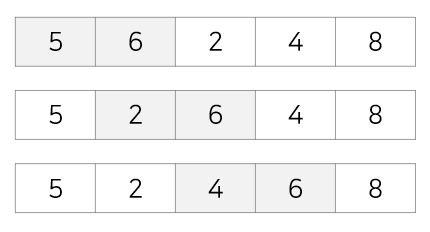
2회전 : 첫번째 값 5를 두번째 값인 6과 비교해 교환X, 두번째 값인 6을 세번째 값 2와 비교해 교환, 세번째 값인 6을 네번째 값인 4와 비교해 교환
-
3회전 : 첫번째 값 5를 두번째 값인 2와 비교해 교환, 두번째 값인 5를 세번째 값 4와 비교해 교환
-
4회전 : 첫번째 값 2를 두번째 값인 4와 비교해 교환X

5. 퀵 정렬 (Quick Sort)
레코드의 많은 자료 이동을 없애고 하나의 파일을 부분적으로 나누어 가면서 정렬하는 방법으로 키를 기준으로 작은 값은 왼쪽에, 큰 값은 오른쪽 서브파일로 분해시키는 방식으로 정렬한다.
- 분할과 정복을 통해 자료를 정렬한다.
- 분할 : 기준값인 피봇을 중심으로 정렬할 자료들을 2개의 부분집합으로 나눈다.
- 정복 : 부분집합의 원소들 중 피봇보다 작은 원소들은 왼쪽, 피봇보다 큰 원소들은 오른쪽 부분집합으로 정렬한다.
- 부분집합의 크기가 더 이상 나누어 질 수 없을 때까지 분할과 정복을 반복 수행한다.
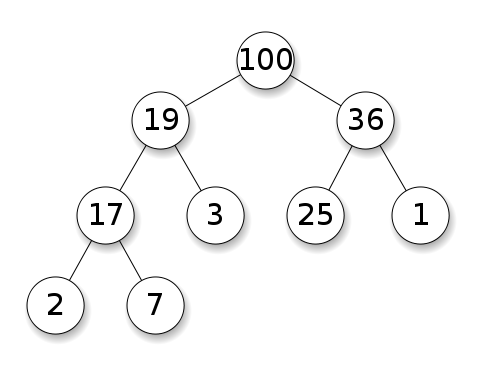
6. 힙 정렬 (Heap Sort)
힙은 큰 키(우선 순위)에 자주 액세스하거나 키(우선 순위) 중심으로 정렬된 시퀀스를 활용해야 할 때 유용한 자료구조입니다.
-
힙은 한 노드(node)가 최대 두 개의 자식노드(child node)를 가지면서, 마지막 레벨을 제외한 모든 레벨에서 노드들이 꽉 채워진 완전이진트리(complete binary tree)를 기본으로 합니다.
-
heap order property : 각 노드의 값은 자신의 자식노드가 가진 값보다 크거나 같다(최대 힙, Max heap). 각 노드의 값은 자신의 자식노드가 가진 값보다 작거나 같다(최소 힙, Min heap).
-
heap shape property : 모양은 완전이진트리이다. 즉 마지막 레벨의 모든 노드는 왼쪽에 쏠려 있다. (이진트리에 대해서 자세한 내용은 이곳을 참고하시면 좋을 것 같습니다)
-
최대 힙 정렬
7. 2-WAY 합병 정렬(Merge Sort)
이미 정렬되어 있는 두 개의 파일을 한 개의 파일로 합병하는 정렬 방식이다.
- 두 개의 키들을 한 쌍으로 각 쌍에 대하여 순서를 정한다.
- 순서대로 정렬된 각 쌍의 키들을 합병하여 하나의 정렬된 서브리스트로 만든다.
- 위 과정에서 정렬된 서브리스트들을 하나의 정렬된 파일이 될 때까지 반복한다.