Bias-Variance Tradeoff
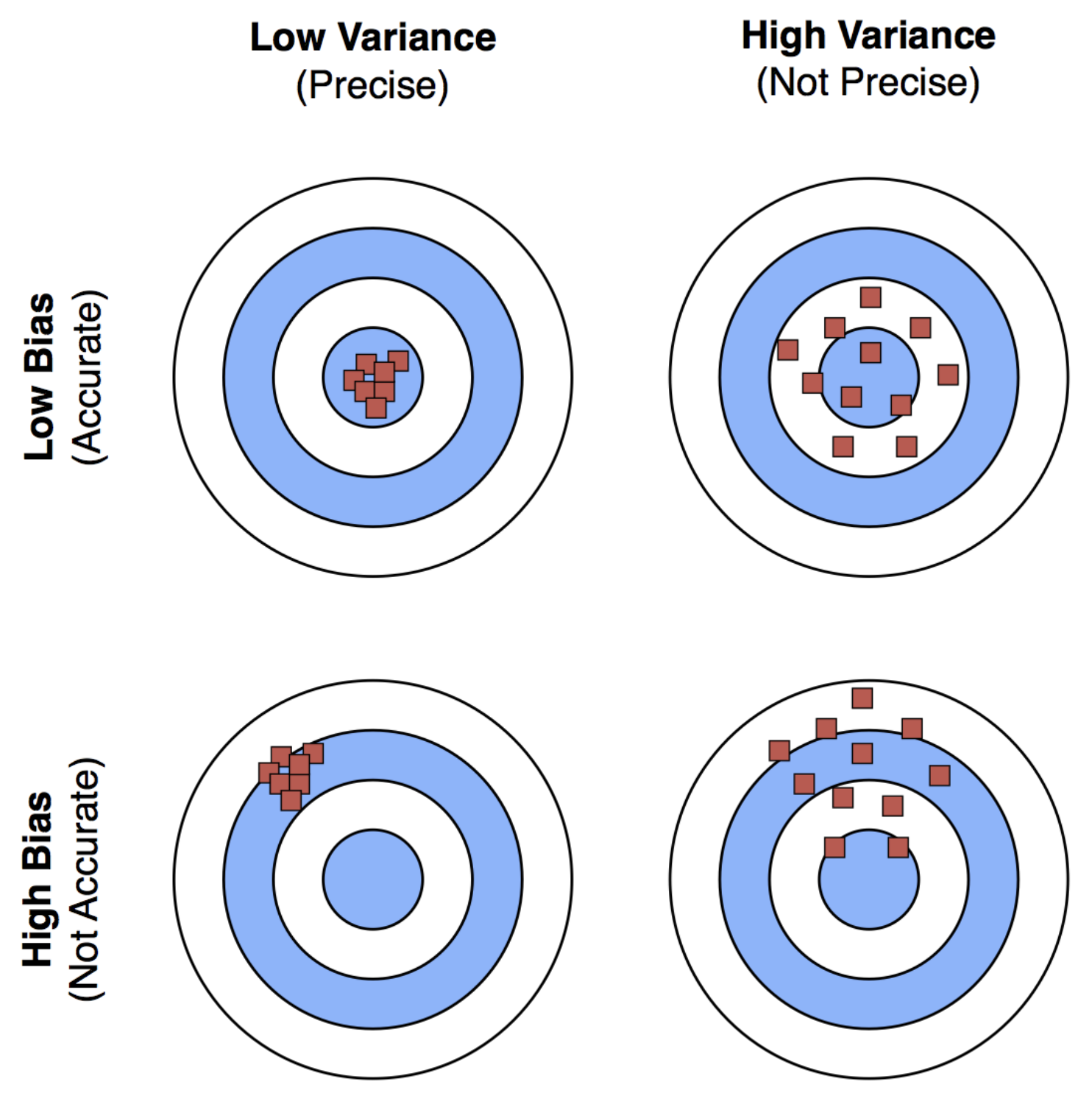
Bias and Variance
모델에서의 샘플에서 추정된 파라미터의 분산(variance)을 감소시키는 것이 추정된 파라미터의 편향을 증가시킴으로써 이뤄지는 것을 말한다. 이 두 값을 동시에 최소화시키는 상충되는 상황을 Bias-variance dilemma라고도 한다.
Bias Error
편향에러(bias error)는 알고리즘을 학습하는데에 잘못된 가정을 한 경우이다. 높은 편향은 피쳐와 타깃 아웃풋간의 주요한 상대적 관계에 대해서 놓치게 된다. 따라서 편향이 높은 모델은 과적합이 없는 단순하지만 데이터간 관계성을 놓치는 과소적합(underfitting) 모델을 만드는 결과를 낳는다.
Variance Error
분산에러/변동에러(variance error)는 훈련셋 데이터에서의 작은 변동에도 민감하게 반응함에 따라 발생할 수 있는 오차인데, 랜덤 노이즈가 많은 데이터를 학습할 경우 발생할 수 있다. 즉 분산이 높은 모델은 훈련데이터를 잘 표현하는 복잡한 모델이며, 랜덤노이즈를 일일히 민감하게 학습하는 과정에서 잘못된 노이즈까지 포함할 수 있고 과적합(overfitting)의 문제를 일으킬 수 있다.
정확도와 정밀도
정확도(正確度, accuracy)는 과학, 산업, 공업, 통계학 분야에서 측정하거나 계산된 양이 실제값과 얼만큼 가까운지를 나타내는 기준이며, 관측의 정교성이나 균질성과는 무관하다. 그러나 착오와 정오차가 제거된 경우, 정밀도를 정확도의 척도로 사용할 수 있다. 왜냐하면 현실적으로는 실제값을 정확하게 알 수 없기 때문이다.정확도와 밀접한 관계가 있는 정밀도(精密度, precision)는 여러 번 측정하거나 계산하여 그 결과가 서로 얼만큼 가까운지를 나타내는 기준이다. 관측의 균질성을 나타내며, 관측된 값의 편차가 적을수록 정밀하다. 정밀도는 관측 과정과 우연 오차와 밀접한 관계를 가지며, 관측장비와 관측방법에 크게 영향을 받는다. 여기서 우연 오차는 까닭이 뚜렷하지 않은 오차이며 최소 제곱법에 따른 확률 법칙에 따라 추정할 수 있다. -Wikepedia-
