How to generate default boxes in SSD
- Anchor box의 개념에 대해선 다른 글에서 다루어보겠다. 원리적으로 보았을 때 Anchor box와 Default box의 개념은 거의 비슷하다 (SSD 저자도 이와 같이 설명). 본 글은 SSD 논문에 나와있는 Default box를 만드는 방법에 대해 알려주고 이를 임의의 사진에 적용해볼 수 있는 코드를 제공한다.
Anchor box는 각각의 grid(pixel)마다 만들어 놓은 정해진 크기의 box들이다. 이러한 box들을 가지고 우리는 사물의 bounding box를 예측한다. object의 모양이 여러가지이기 때문에 Anchor box들의 모양도 마찬가지로 여러가지이다 (옆으로 넓은 것, 위로 높은 것.. 반듯하게 네모난 것). 아래의 그림을 보면 이해하기 쉬울 것이다.
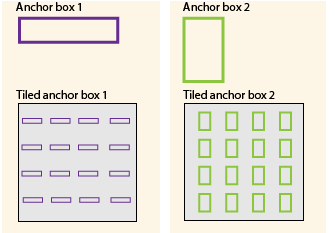
위의 그림에선 두 종류의 Anchor box가 보여진다.
Anchor box 의 기초적인 개념은 다음 Andrew Ng의 강의에서 볼 수 있다. https://www.youtube.com/watch?v=RTlwl2bv0Tg
Description of Default boxes in paper
At each feature map cell, we predict the offsets relative to the default box shapes in the cell, as well as the per-class scores that indicate the presence of a class instance in each of those boxes. Specifically, for each box out of k at a given location, we compute c class scores and the 4 offsets relative to the original default box shape. This results in a total of (c + 4)k filters that are applied around each location in the feature map, yielding (c + 4)kmn outputs for a m × n feature map.
하나의 default box당 c개의 클래스(Object classification)와 4개의 좌표 (Offset - cX, cY, W, H)에 대한 정보가 나온다. 이는 object의 분류와 bounding box의 예측이 한번에 이루어지고 있음을 말한다. (classification & bounding box regression)
[c개 클래스의 예시 (강아지, 고양이, 사람, 배경)/ 좌표 예시(정중앙 x, 정중앙 y, 폭, 높이) ] - 한 개의 box 당 C+4의 정보
한 grid 당 k개의 default boxes가 있다고 한다면 m x n feature map에선 (c+4) x k x (mxn) 만큼의 정보가 나온다. 위의 (c+4)Kmn output이 나오는 이유.
Previous works [10,11] have shown that using feature maps from the lower layers can improve semantic segmentation quality because the lower layers capture more fine details of the input objects.... we use both the lower and upper feature maps for detection.
convolutional layer들을 통과할수록 원본 이미지는 추상적으로 변한다. 따라서 convolutional layer들을 많이 통과하지 않은, 덜 추상적인 (feature maps from lower layer) 피쳐맵을 detection에 사용하는게 성능면에서 상대적으로 우수하다. SSD의 저자들은 lower layer 부터 higer layer들의 피쳐맵에 default box들을 모두 반영하기로 하였다.
We design the tiling of default boxes so that specific feature maps learn to be
responsive to particular scales of the objects. Suppose we want to use m feature maps
for prediction. The scale of the default boxes for each feature map is computed as:where smin is 0.2 and smax is 0.9, meaning the lowest layer has a scale of 0.2 and
the highest layer has a scale of 0.9, and all layers in between are regularly spaced.
m개의 피쳐맵을 사용한다고 가정하자. 마지막 m번째 피쳐맵은 이미지가 가장 왜곡된(추상화된) 피쳐맵일 것이다. SSD의 저자들은 각 피쳐맵들에 적용할 defualt boxes들의 비율을 위의 수식으로 지정해놓았다. 비율은 피쳐맵에 대한 default box의 상대적인 크기라고 보면 된다. 그렇기에 피쳐맵의 사이즈가 가장 작은 m번째 피쳐맵의 default box는 가장 큰 비율을 가진다. (Smax = 0.9)
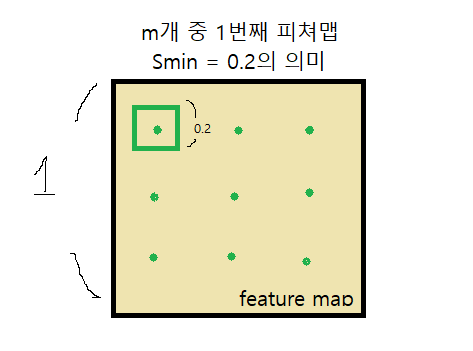
위의 그림을 보면 수식에서 도출된 비율이 무엇을 의미하는지 알 수 있을 것이다.
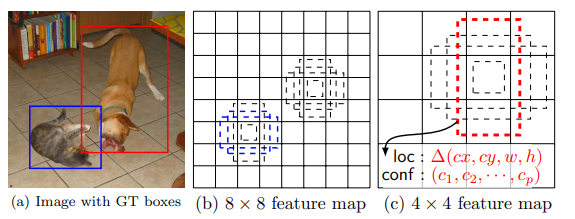
위의 그림에서 4x4 feature map (8x8 feature map보다 추상화된) 의 default box의 크기가 피쳐맵 대비 더 크다는 것을 볼 수 있는데, 이게 곧 S(8x8) < S(4x4) 를 의미한다.
아니 default boxes들의 모양이 한 종류가 아니라면서 이는 무슨 종류의 default box를 기준으로 둔 비율인가?
이러한 의문점이 생기는 것이 지극히 정상이다. 위의 비율은 기준이 되는 기본 정사각형 모양의default box의 비율이다. 바로 다음에 다양한 종류의 default box의 size를 구하는 식이 등장한다.
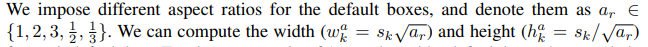
여기서 {1,2,3,1/2,1/3}은 서로다른 5개 종류의 default box를 말한다. 물론 이러한 5개 default box들이 각각의 grid 마다 그려져 있을 것이다. 각 종류의 width와 height를 구하는 식을 보면 1이 기본, 2와 3이 옆으로 뚱뚱한 default box, 그리고 1/2, 1/3이 위로 길쭉한 default box라는 것을 알 수 있다.
위의 내용을 추가하면 다음과 같다.
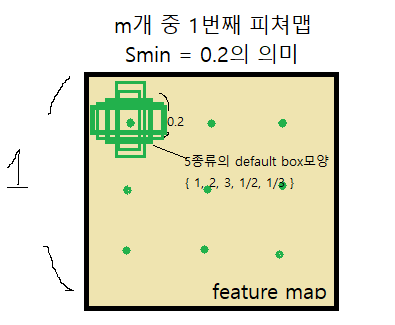

그런데 SSD의 저자들은 여기서 그치지 않고 한 종류의 default box를 추가한다. 위의 내용을 모두 종합하면 다음과 같다.
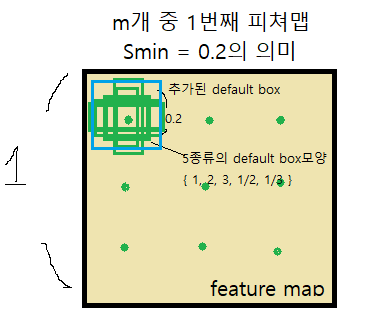
그 아래의 내용은 default box의 center에 대한 내용인데 이는 각 그리드( pixel ) 의 중심이라고 이해하면 된다. 마지막 저자의 말처럼, 이는 저자들의 방식일 뿐이지 누군가는 다른 비율과 크기의 default box를 사용할 수 있다.
