Discriminative Neural Clustering (DNC)
2019, SLT conference (Best paper)
Abstract
- Data clustering with maximum number of clustering
- Supervised seq2seq
- No explicit definition of similarity measure
- 기존 traditional 방법에서는 cosine similarity 사용
- Transformer arch
- Data scarcity (AMI dataset only 147 complete meetings)
- Three Data augmentation
- Sub-sequence randomization
- Input vector randomization
- Diaconis augmentation
- Generate new samples by rotating L_2 normalized speaker embedding
- Assumption
- Maximum number of speaker
- VAD
- Non-overlap
- Using extracted d-vector
Introduction
-
Clustering 특징
- Audio stream => speaker-homogeneous segments (d-vector) => speaker identities
- 기존 agglomerative clustering\, k-means\, spectral
- Unsupervised & model-free
- Leveraging pre-defined distance & similarity
-
이전 연구와 비교
- Clustering 어려운 점
- Ambiguous when not well separated in feature space
- K-means & spectral clustering 단점
- iterative process with multiple sets of randomly initialized value (& related hyper-parameters)
- 기존 해결방법: Various loss function[6\, 15\, 16] & model structure [14\, 17]
- Assumption
- Clustering related to underlying data distribution & distance measure
- 이런 관점에서\, parametric model is more desirable (위의 가정을 안하므로)
- Assumption
- 기존 parametric model 문제점
- SD assigned to speakers with unknown identities
- Should not be associating a target with a particular speaker
- Relative speaker identities that are interest\, rather tan absolute speaker identity as in a speaker classification
- Clustering 어려운 점
-
Discriminative Neural Clustering (DNC)
- Model
- Seq2seq using Transformer
- Input sequence
- 몇 10초 되는 E2E ASR 과 다르게 SD에서는 10분 길게는 몇 시간도 된다 (AMI meeting dataset)
- To avoid dealing with overly-long sequence
- -> DNC의 input sequence 안에서 각 feature vector는 frame이 아닌 speaker embedding of a speaker-homogeneous segments
- Three Data Augmentation
- Augmented Multi-party Interaction (AMI) dataset
- Widely used for SD\, only 147 meeting exist
- Data scarcity Problem
- 1. Sub-sequence randomization
- 2. Input vector randomization
- 3. Diac-Aug
- Effect: Learn the importance of relative speaker identities rather than absolute identities
- Augmented Multi-party Interaction (AMI) dataset
- Loss function
- Simple cross-entropy
- Model
Related Work
-
Unsupervised clustering
- Agglomerative clustering\, K-means\, spectral clustering
- Assumption
- data distribution: Gaussian
- Measure distance between speaker embeddings: cosine similarity
- DNC no assumption to data distribution\, measurement
-
Supervised clustering (UIS-RNN)
- Handling an unlimited # speakers
- 문제점 1. Assumption ddCRP
- Occurrence of speakers follows the same distance-dependent Chinese restaurant process
- 문제점 2. Worked well in Callhome dataset
- Callhome is relatively special\, 2명의 speaker 가 90% 차지하고있고 평균 대화는 약 2분
- AMI dataset은 more general\, more difficult
- 4 or more #spk
- More than 30 min on avg\, not suitable ddCRP
- 문제점 3. speaker embedding
- Noramal distribution with identity covariance matrix and mean given by RNN
- DNC는 위와 같은 가정은 하지 않았지만 maximum speaker는 가정
DNC
-
Assumption
- the maximum number of clusters is know
-
As long as each cluster is associated with a unique identify label, permutating the cluster labels should not affect the clustering outcome
-
Task of Clustering can be considered as a special seq2seq classification problem
-
Input sequence is has an underlying identity
-
Attempts to assign 𝑥𝑖 to a clustering label 𝑦𝑖
Same identity 𝑧𝑖 are assigned the same cluster label 𝑦𝑖

- Instead of the absolute identities assigned to each , the relative cluster labels across 𝑿
- Multiple data samples (𝑋, 𝑧_(1:𝑁)) have to be available for training
Data Augmentation DNC
Two objective
- Generate as many training sequence (𝑿,𝑦_(1:𝑁) ) => sub-sequence randomization
- Match the true data distribution 𝑃(𝑿, 𝑦_(1:𝑁) ) as closely as possible => input vector randomization
Sub-sequence randomization
- Multiple sub-sequence (𝑿(𝑠:𝑒), 𝑦(𝑠:𝑒)) , random starting, ending indexes
- DNC 에서는 input sequence 가 많아 질 수록 같은 x_i 가 다른 y_i로 맵핑될 수 있게 한다
이를 통해 x_i 가 fixed cluster label 가지는 것을 막아준다
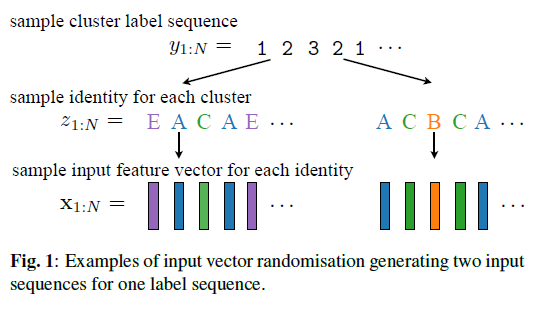
Input vectors randomization
- Preserving its cluster label sequence
- reassign to an identity randomly chosen from the training set 𝑧_(1:𝑁)
- for each a feature vector is randomly chosen as
이때 하나의 미팅에서 sampling 도 가능하고, 전체 training set 에서도 sampling 이 가능함
따라서 global 과 meeting 으로 나눠서 실험
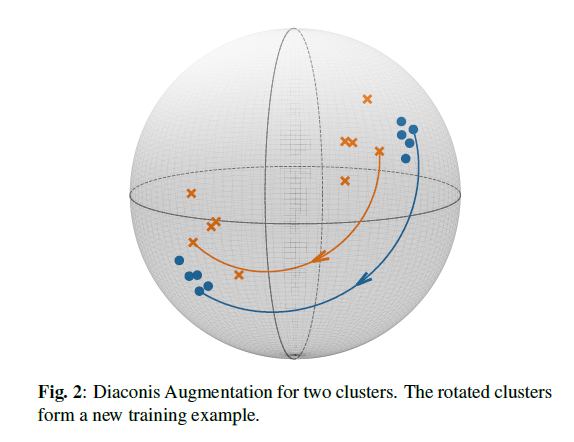
Diaconis Augmentation (Diac-Aug)
- Applicable are 𝐿_2-normalized
- Forming clusters on the surface of a hypersphere whose radius is the L2 norm
- Rotate entire input sequence to different region of the hypersphere
- Effect: unseen 𝒙𝒊^′⇒(𝑿^′,𝑦(1:𝑁) ),
- Random oration matrix 𝑹∈(𝐷,𝐷), 𝑿^′=𝑿𝑹
- prevent the model from overfitting
5.1. Data and Segmentation
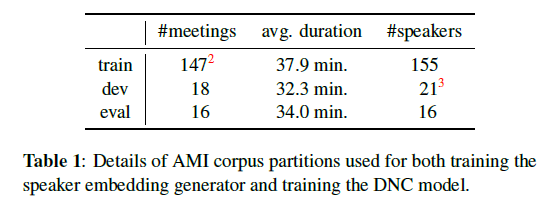
- AMI meeting corpus
- Official train\, dev\, eval
- BeformIt[32]를 통해 8-channel => 1 channel
- Assumption: perfect VAD
- Manual segmentation & stripping silence at both end of each utterance (silence 제거했다는 의미??)
- Spectral clustering 과 성능을 비교하기위해서
- Short segment 들은 Enclosed 되어있어서 제거 (output 을 generation 하기에 unrepresentative)
5.2. Segment-level Spk emb
Segment-level embedding (Clustering is performed)
- 𝑥_𝑖 is obtained by averaging the window-level speaker embedding
- 𝐿_2-normalization
- Both before and after averaging
Window-level embedding generator
- Both before and after averaging
- Using TDNN: 2 seconds (215 frames, [-107, 106])
- TDNN 각 DNN에서는 [-7, 7]
- Combine TDNN output vectors (like [14])
- Resemble x-vector
- Train on AMI training data with angular Softmax (Asoftmax)
DNC model
- Transformer (using ESPNet)
- 4 encoder & 4 Decoder (7.3M)
- Head is 4
- Adam (rasmps up learning 0 to 12 in the first 40\,00) and decrease
- Dropout 10%
- Diagonal local attention
- Input-to-output alignment
- Strictly one-to-one and monotonic
- Source attention can be restricted to an identity matrix
- Attention matrix masked to be a tri-diagonal matrix
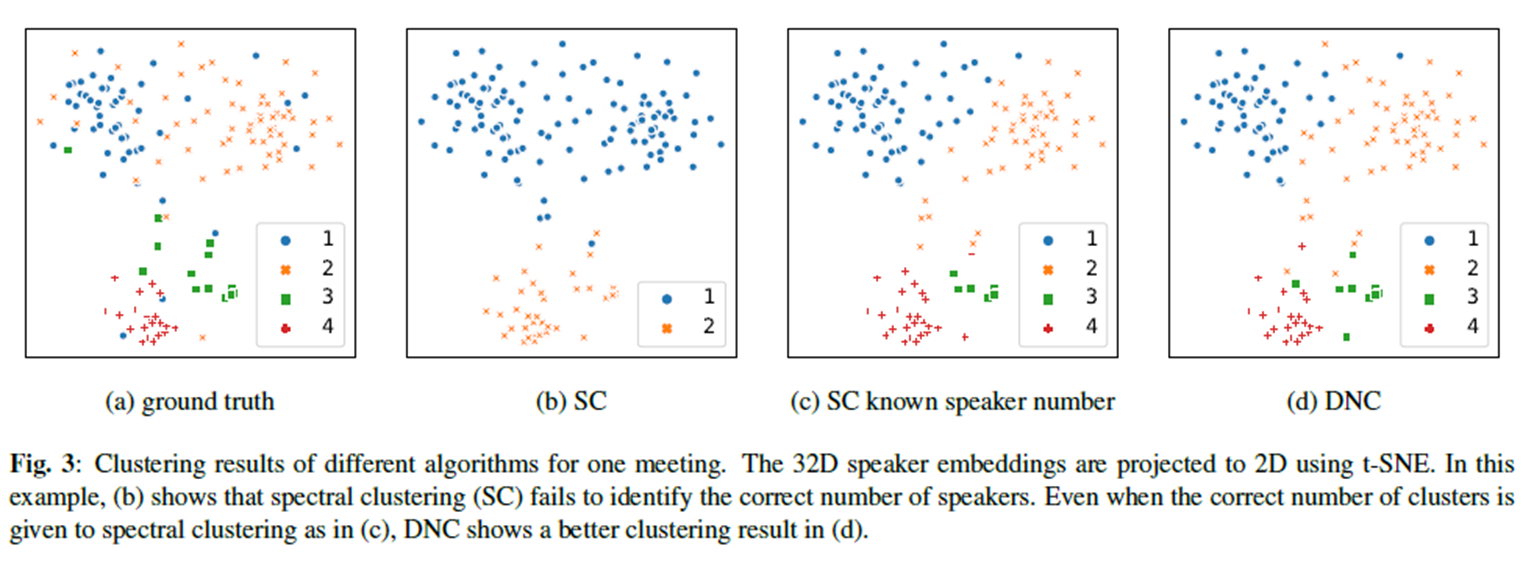
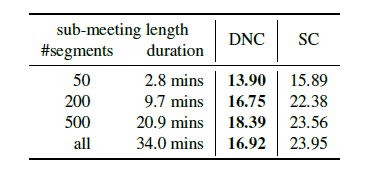
Experiments

Currently pursuing my Ph.D. in GIST, I am deeply intrigued by the field of speaker diarization and committed to making meaningful contributions to it.