2020, ASC [CVPR]
What is the focused problem?
-
Figure
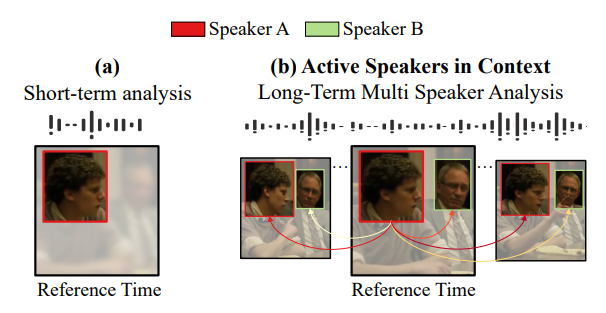
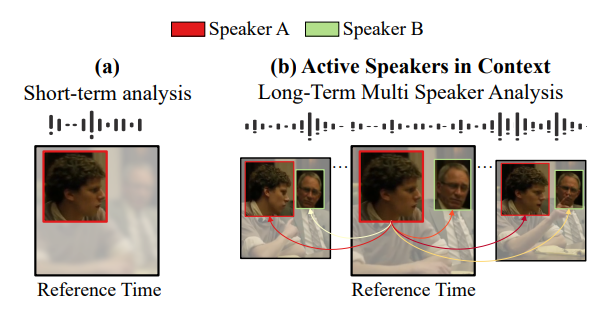
- Let us assume we only have access to a short audiovisual sample from a single speaker
- (a) Short-term analysis
- By looking at the lips of the speaker, it is hard to tell if he is talking,
- but the audio indicates that someone at that moment is talking.
- To increase our success prediction chances, let us leverage multi-speaker context
- By looking at the lips of the speaker, it is hard to tell if he is talking,
- (b) Active Speakers in Context
- Speaker B is not talking over the whole sequence, and instead, he is listening to Speaker A.
- Looking at Speaker A (e.g. his lips) for the long-term helps us to smooth out local uncertainties.
Architecture Summary
- Relationships between multiple speakers over long time horizons
- Two-stream architectures
- Refining the context representation with self-attention and sequence-to-sequence models
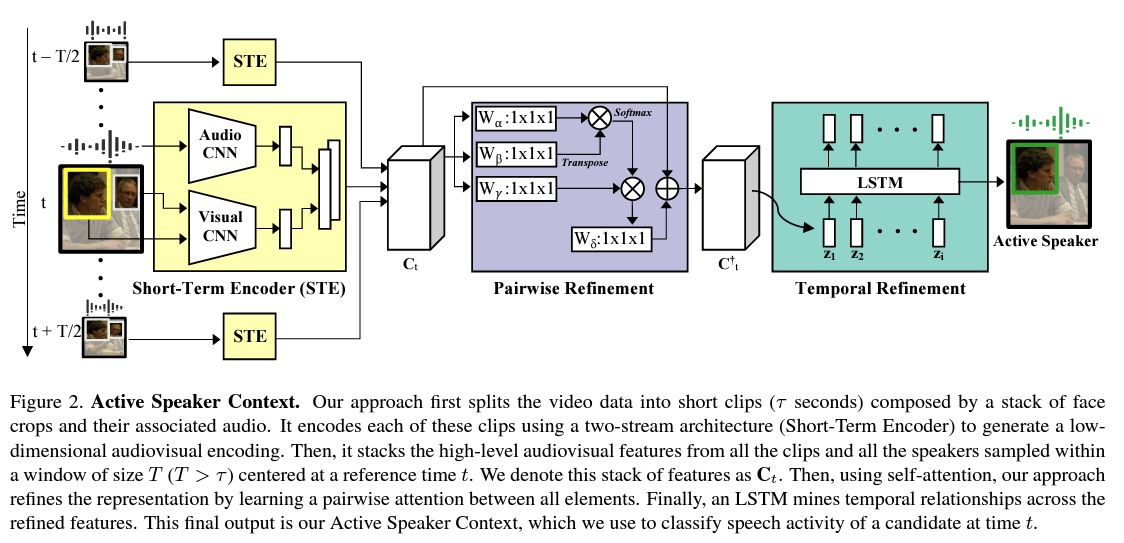
3. Active Speakers in Context
- Learning long-term and interspeaker relationships
- estimates an active speaker score for an individual face (target face)
- by analyzing the target itself, the current audio input,
- and multiple faces detected at the current timestamp
- estimates an active speaker score for an individual face (target face)
- Bottom-up strategy
- Holistically encoding long time horizons and multi-speaker interactions
- it first aggregates fine-grained observations (audiovisual clips)
- Active Speaker Ensemble
- context-rich representation
- Active Speaker Ensemble
- then maps these observations into an embedding that allows the analysis of global relations between clips
- Refined ensemble the Active Speaker Context
- refined to explicitly model pairwise relationships
- refined to explicitly model long-term structures over the clips
- Refined ensemble the Active Speaker Context
3.1 Aggregating Local Video Information
- The visual information
- stack of k consecutive face crops sampled from a time interval τ .
- The audio information
- raw wave-form sampled over the same τ interval.
- clip
- : crop stack of a speaker s
Short-Term Encoder (STE)
- Role
- it creates a low-dimensional representation that fuses the audiovisual information
- it ensures that the embedded representation is discriminative enough for the active speaker detection task
Strcutred Context Ensemble
-
The Active Speaker problem deals with identifying who is speaking at a given time in a multi-speaker environment.
-
Assemble clip features into a set for the problem
-
The method involves creating context tensors
- preserve the temporal order of the features while considering a reference speaker and context speakers.
-
Step-by-step explanation of the process
- Define a long interval centered at a reference time t.
- Designate one of the speakers present at time t as the reference speaker, and every other speaker as context speakers.
- Compute us,τ for every speaker s (s = 1, ..., S) present at time t over L different τ intervals throughout the temporal window T.
- The sampling scheme yields a tensor Ct with dimensions L×S×d, where S is the total number of speakers analyzed.
- Assemble Ct for every possible t in a video, preserving the temporal order of the sampled features.
- Locate the feature set of the reference speaker as the first element along the S axis of Ct.
- Context speakers are randomly stacked along the remaining positions on the S axis.
-
Figure
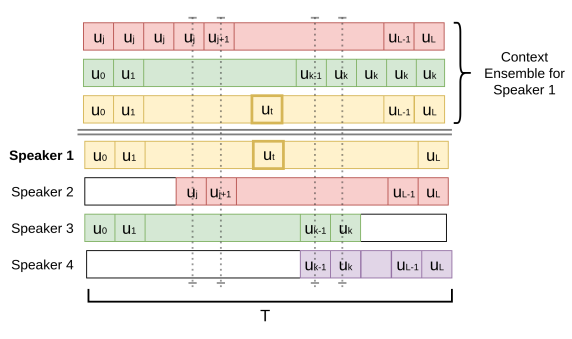
- Define a long-term sampling window T containing L + 1 clips centered at time
- Select context speakers that overlap with the reference speaker at time t (e.g., Speakers 2 and 3).
- Sample clip-level features ul throughout the whole sampling window T from the reference speaker and all context speakers.
- If the temporal span of a context speaker does not entirely match the interval T, pad it with the initial or final speaker features (e.g., pad left with ui for Speaker 2 and pad right with uk for Speaker 3).
- Note that Speakers 2 and 3 could switch positions, but Speaker 1 (the reference speaker) must remain at the bottom of the stack.
3.2 Context Refinement
Pairwise Refinement
Temporal Refinment
Training and Implementation Details
Training the STE
Training the ASC Model
Code
ReadMe
Before Training
- Download utility files with
./scripts/dowloads.sh. - Extract 16k .wav audio tracks from videos:
- Update
ava_video_dirandtarget_audiosin./data/extract_audio_tracks.py.
- Update
- Slice audio tracks by timestamp:
- Update
ava_audio_dir,output_dir, andcsvin./data/slice_audio_tracks.py.
- Update
- Extract face crops by timestamp:
- Update
ava_video_dir,csv_file, andoutput_dirin./data/extract_face_crops_time.py.
- Update
Note: Step 3 results in around 124GB of extra data, and full audio tracks from Step 1 won't be needed afterward.
Training
- Two stages
- Optimizing the Short-Term Encoder (STE)
- Context Ensemble Network
- Train the STE:
- Modify
STE_inputsin./core/config.py. - Run
STE_train.py clip_lenght cuda_device_number(use an odd clip length).
- Modify
- Forward STE:
- Run
STE_forward.py clip_lenght cuda_device_number(same clip length as training). - Process both training and validation sets.
- Run
- Train the ASC Module:
- Update
ASC_inputsin./core/config.py. - Run
./ASC_train.py clip_lenght skip_frames speakers cuda_device_number(same clip length as STE training).
- Update
- Forward ASC:
- Run
./ASC_forward.py clips time_stride speakers cuda_device_number(same clip and stride configurations). - Use
ASC_predcition_postprocessing.pyfor evaluation.
- Run
DataLoader
ContextualDataset
class ContextualDataset(data.Dataset):
def get_speaker_context(self, ts_to_entity, video_id, target_entity_id,
center_ts, candidate_speakers):
context_entities = list(ts_to_entity[video_id][center_ts])
random.shuffle(context_entities)
context_entities.remove(target_entity_id)
if not context_entities: # nos mamamos la lista
context_entities.insert(0, target_entity_id) # make sure is at 0
while len(context_entities) < candidate_speakers:
context_entities.append(random.choice(context_entities))
elif len(context_entities) < candidate_speakers:
context_entities.insert(0, target_entity_id) # make sure is at 0
while len(context_entities) < candidate_speakers:
context_entities.append(random.choice(context_entities[1:]))
else:
context_entities.insert(0, target_entity_id) # make sure is at 0
context_entities = context_entities[:candidate_speakers]
return context_entitiesget_speaker_context- Finds a list of candidate speaker entity IDs around a target entity ID for a given video and timestamp.
- 4-5. Initialize list of context entities and shuffle them.
- Remove target entity ID from the list.
- 7-12. If no context entities left, insert target entity ID and fill the list with traget entity duplicates.
- 13-18. If not enough context entities, insert target entity ID and fill the list with duplicates.
- 19-21. If enough context entities, insert target entity ID and trim the list.
- Return context entities list.
def _decode_feature_data_from_csv(self, feature_data):
feature_data = feature_data[1:-1]
feature_data = feature_data.split(',')
return np.asarray([float(fd) for fd in feature_data])_decode_feature_data_from_csv- Converts a CSV row into a NumPy array of feature data.
- Remove brackets from feature data string.
- Split feature data string into a list of values.
- Convert the list of values into a NumPy array.
def get_time_context(self, entity_data, video_id, target_entity_id,
center_ts, half_time_length, stride):
all_ts = list(entity_data[video_id][target_entity_id].keys())
center_ts_idx = all_ts.index(str(center_ts))
start = center_ts_idx-(half_time_length*stride)
end = center_ts_idx+((half_time_length+1)*stride)
selected_ts_idx = list(range(start, end, stride))
selected_ts = []
for idx in selected_ts_idx:
if idx < 0:
idx = 0
if idx >= len(all_ts):
idx = len(all_ts)-1
selected_ts.append(all_ts[idx])
return selected_tsget_time_context- Determines selected timestamps around a center timestamp based on the stride for a target entity in a video
- 1-3. Determine the range of selected timestamps around the center timestamp.
- 4-11. Loop through timestamp indices and clamp them to valid values.
- Return the list of selected timestamps.
def get_time_indexed_feature(self, video_id, entity_id, selectd_ts):
time_features = []
for ts in selectd_ts:
time_features.append(self.entity_data[video_id][entity_id][ts][0])
return np.asarray(time_features)get_time_indexed_feature- Retrieves the time-indexed features for a given entity in a video.
- Loop through selected timestamps and append the corresponding features to a list.
def _cache_feature_file(self, csv_file):
entity_data = {}
feature_list = []
ts_to_entity = {}
print('load feature data', csv_file)
csv_data = io.csv_to_list(csv_file)
for csv_row in csv_data:
video_id = csv_row[0]
ts = csv_row[1]
entity_id = csv_row[2]
features = self._decode_feature_data_from_csv(csv_row[-1])
label = int(float(csv_row[3]))
# entity_data
if video_id not in entity_data.keys():
entity_data[video_id] = {}
if entity_id not in entity_data[video_id].keys():
entity_data[video_id][entity_id] = {}
if ts not in entity_data[video_id][entity_id].keys():
entity_data[video_id][entity_id][ts] = []
entity_data[video_id][entity_id][ts] = (features, label)
feature_list.append((video_id, entity_id, ts))
# ts_to_entity
if video_id not in ts_to_entity.keys():
ts_to_entity[video_id] = {}
if ts not in ts_to_entity[video_id].keys():
ts_to_entity[video_id][ts] = []
ts_to_entity[video_id][ts].append(entity_id)
print('loaded ', len(feature_list), ' features')
return entity_data, feature_list, ts_to_entity_cache_feature_file- Reads CSV files containing features and organizes them into dictionaries to enable easy access.
- 42-45. Initialize dictionaries to store entity data and timestamp-to-entity mappings.
- Load CSV data into a list.
- 47-70. Loop through CSV rows and populate entity data and timestamp-to-entity dictionaries.
- Print the number of loaded features.
- Return entity data, feature list, and timestamp-to-entity dictionaries.
ASCFeaturesDataset
class ASCFeaturesDataset(ContextualDataset):
def __init__(self, csv_file_path, time_lenght, time_stride,
candidate_speakers):
# Space config
self.time_lenght = time_lenght
self.time_stride = time_stride
self.candidate_speakers = candidate_speakers
self.half_time_length = math.floor(self.time_lenght/2)
# In memory data
self.feature_list = []
self.ts_to_entity = {}
self.entity_data = {}
# Load metadata
self._cache_feature_data(csv_file_path)- Configure time length, time stride, candidate speakers, and calculate half_time_length.
- Initialize in-memory data structures.
- Call
_cache_feature_datato load metadata.
- Call
# Parallel load of feature files
def _cache_feature_data(self, dataset_dir):
pool = mp.Pool(int(mp.cpu_count()/2))
files = glob.glob(dataset_dir)
results = pool.map(self._cache_feature_file, files)
pool.close()
for r_set in results:
e_data, f_list, ts_ent = r_set
print('unpack ', len(f_list))
self.entity_data.update(e_data)
self.feature_list.extend(f_list)
self.ts_to_entity.update(ts_ent)- Create a multiprocessing pool to parallelize feature file loading.
- Get all files in the dataset directory.
- Load feature files in parallel.
- Close the multiprocessing pool.
- 10-13. Combine and update the results from parallel loading.
def __getitem__(self, index):
video_id, target_entity_id, center_ts = self.feature_list[index]
entity_context = self.get_speaker_context(self.ts_to_entity, video_id,
target_entity_id, center_ts,
self.candidate_speakers)
target = self.entity_data[video_id][target_entity_id][center_ts][1]
feature_set = np.zeros((self.candidate_speakers, self.time_lenght, 1024))
for idx, ctx_entity in enumerate(entity_context):
time_context = self.get_time_context(self.entity_data,
video_id,
ctx_entity, center_ts,
self.half_time_length,
self.time_stride)
features = self.get_time_indexed_feature(video_id, ctx_entity,
time_context)
feature_set[idx, ...] = features
feature_set = np.asarray(feature_set)
feature_set = np.swapaxes(feature_set, 0, 2)
return np.float32(feature_set), target- Get video_id, target_entity_id, and center_ts from the feature list using the index.
- 3-4. Get the speaker context.
- Get the target label.
- Initialize a feature_set array.
- 9-16 Loop through the entity_context to populate the feature_set array with time-indexed features.
- Convert feature_set to a NumPy array.
- Swap the axes of the feature_set array.
- Return the feature_set array and the target label.![]

Currently pursuing my Ph.D. in GIST, I am deeply intrigued by the field of speaker diarization and committed to making meaningful contributions to it.