Published on ACM.MMSP 2021
https://github.com/TaoRuijie/TalkNet-ASD
Active Speaker Detection (ASD)
- Active speaker detection (ASD)
- detect who is speaking in a visual scene of one or more speakers
- humans judge whether a person is speaking (cognitive finding)
- 1) Does the audio of interest belong to human voice?
- 2) Are the lips of the person of interest moving?
- 3) If the above are true\, is the voice synchronized with the lip movement?
- Challenging Problem
- Predict at a fine granularity in time\, (i.e.\, at video frame level)
- the temporal dynamics of audio and visual flow
- and the interaction between audio and visual signals
Active Speaker Detection (ASD)
- Problem of previous work: short segment
- Focused on segment level information\, e.g.\, a video segment of 200 to 600 ms
- Figure 1(a)\, it is hard to judge the speaking activity from a video segment of 200 ms
- doesn’t even cover a complete word
- Figure 1(b)\, longer 2-second video would be more evident of the speaking episode

-
Problem of previous work: Single modal
- not reliable in some challenging scenarios.
-
Ex.
- Off-screen
- laughing\, eating\, and yawning\, that are not related to speaking
- the inter-modality synchronization
-
For video signals
- the minimum unit is a video frame\, i.e.\, a static image
- temporal network
- to encode the temporal context over multiple video frames.
-
For audio signals
- the minimum unit is an audio frame of tens of milliseconds
- an audio temporal encoder
- to encode the temporal context over multiple audio frames
-
backend classifier
- audio-visual cross-attention
- capture inter-modality evidence
- self-attention
* capture long-term speaking evidence

- audio-visual cross-attention
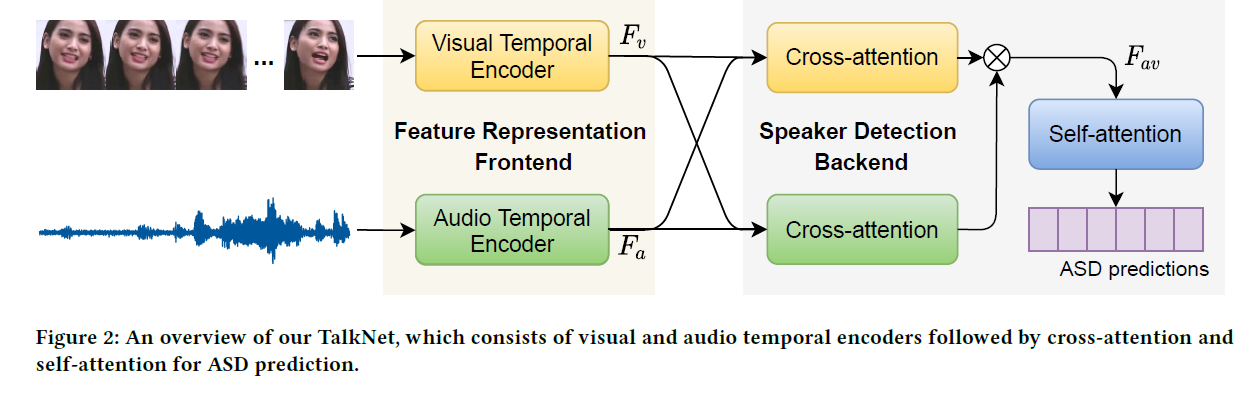
TalkNet
- TalkNet
- end-to-end pipeline
- takes the cropped face video and corresponding audio as input
-
Visual Temporal Encoder
- learn the long-term representation of facial expression dynamic
-
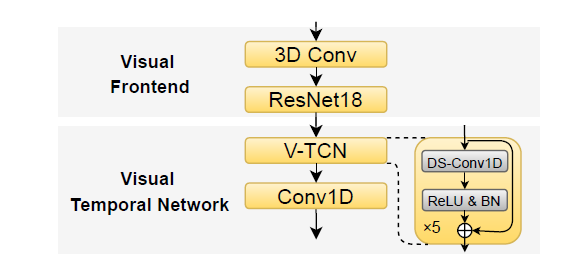
The visual frontend: 3D Conv
- the video frame stream into a sequence of frame-based embedding
-
The visual temporal network
- represent the temporal content in a long-term visual spatio -temporal structure
- Video temporal convolutional block (V-TCN)
- has five residual connected ReLU\, BN and depth-wise separable
- convolutional layers (DS Conv1D) followed by a Conv1D layer
- reduce the feature dimension
-
Receptive Field
- 21 video frames => 840ms (when 25fps)
-
Audio Temporal Encoder: ResNet34 with dilated convolutions
- 2D ResNet34 network with squeeze-and-excitation (SE) module [13]
- Input: MFCCs
- dilated convolutions
- time resolution of audio embeddings matches that of the visual embeddings
- 2D ResNet34 network with squeeze-and-excitation (SE) module [13]
-
receptive field
- 189 audio frames => segment of 1\,890 ms to encode (when MFCC window step is 10 ms)
-
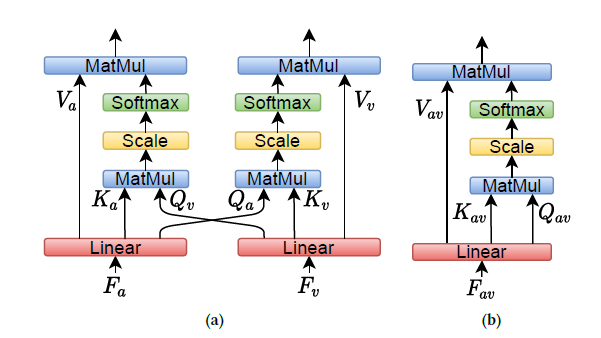
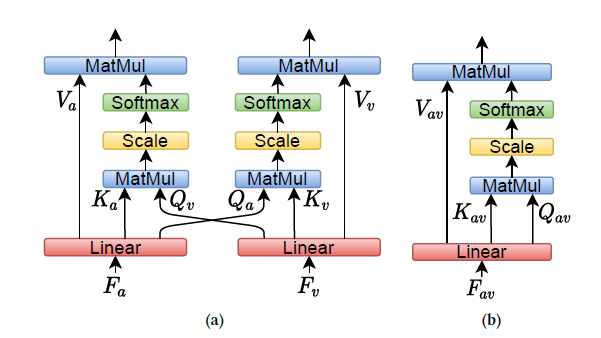
Audio-visual Cross-Attention
- Audio-visual synchronization is an informative cue for speaking activities
- not exactly time aligned
- audio-visual alignment may depend on the instantaneous phonetic content and the speaking behavior of the speakers
- cross-attention networks along the temporal dimension to dynamically describe such audio-visual interaction
- outputs are concatenated together along the temporal direction
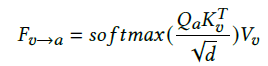
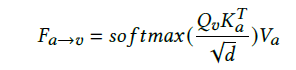
- Self-Attention and Classifier
- model the audio-visual utterance-level temporal information
- to distinguish the speaking and non-speaking frames
- Loss Function
- frame-level classification => cross-entropy loss
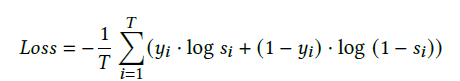
- frame-level classification => cross-entropy loss
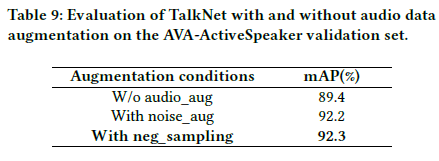
Audio Augmentation
- One traditional audio augmentation method: a large noise dataset
- it is not straightforward to find such acoustic data that matches the video scenes
- negative sampling method
- simple yet effective solution.
- randomly select the audio track from another video in the same batch as the noise
- Pros
- involves the in-domain noise and interference speakers from the training set itself.
- does not require data outside
Experiments



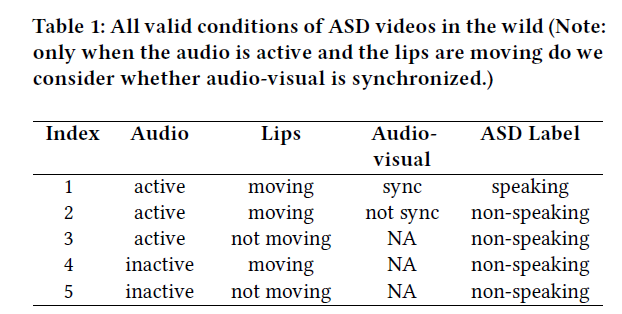
- humans detect active speakers cues
- 1) On audio signal\, is there an active voice?
- 2) For visual signal\, are the lips of someone moving?
- 3) When there is an active voice and the lips of someone are moving\, is the voice synchronized with the lips movement?
- Five valid conditions

Implementation Details
- Config
- The initial learning rate is 10−4\, decrease it by 5% for every epoch
- Dimension
- The dimension of MFCC is 13
- All the faces are reshaped into 112 × 112
- dimensions of the audio and visual feature as 128
- Both cross-attention and self-attention network contain one transformer layer with eight attention heads .
- visual augmentation
- We randomly flip\, rotate and crop the original images to perform
- Columbia ASD dataset
- additional sources from RIRs data [25] and the MUSAN dataset [42] to perform audio augmentation
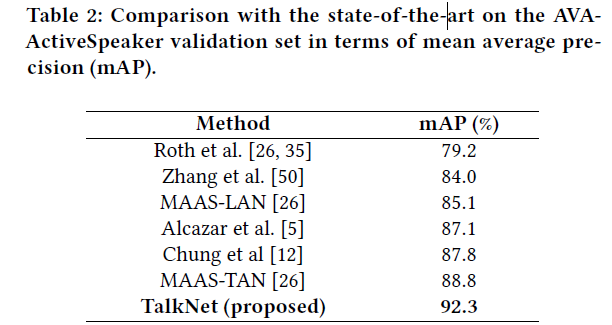
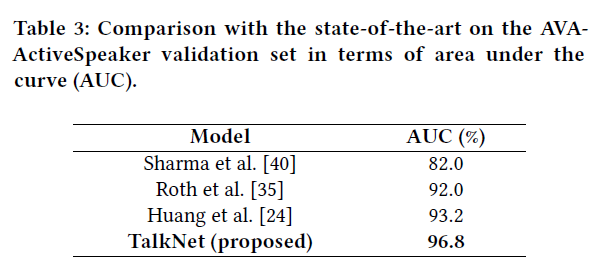
Comparison with the SOTA
- ground truth labels of the AVA-ActiveSpeaker test set with the assistance of the organizer .
- Others [12\, 50] used the pre-trained model in another large-scale dataset
- TalkNet only uses the single face videos from scratch without any additional post-processing.
- We believe that pre-training and other advanced techniques will further improve TalkNet\, which is beyond the scope of this paper.

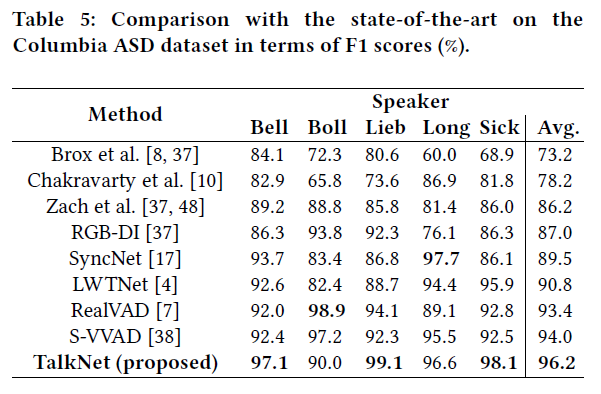
Comparison with the SOTA
- Columbia Active Speaker Detection dataset
- proposed TalkNet\, which is 96.2% for the average result that has an improvement over the best existing system by 2.2%.
- For all the five speakers\, TalkNet provides the best performance for three of them (Bell\, Lieb and Sick)
- It is noted that Columbia ASD is an open-training dataset \, so the methods in Table 5 are tr ained on different dat a\, so we only claim that our TalkNet is efficient on the Columbia ASD dataset.
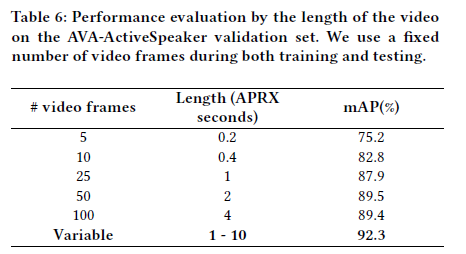
- Analyze the contributions of individual techniques
- Long-term sequence-level temporal context
- Prior studies usually use short-term features of 5 to 13 video frames
- we use a fixed number of 𝑁 frames instead of the entire video sequence
5\,10\,25\,50\,100 that amounts to 0.2\, 0.4\, 1\, 2 and 4 second.
confirms our hypothesis that the long-term sequence-level information is a major source
- Short-term vs long-term features.
- first reproduce the system in [5] to obtain 78.2% mAP for 11 video frames input
- Active speakers in context\, 2020 CVPR\, https://github.com/fuankarion/active-speakers-context
- similar to TalkNet except that there is neither temporal encoder to increase the receptive fields\, and nor attention mechanism.
- longer video duration doesn’t help without the long audio and visual receptive fields and an adequate attention mechanism

- first reproduce the system in [5] to obtain 78.2% mAP for 11 video frames input
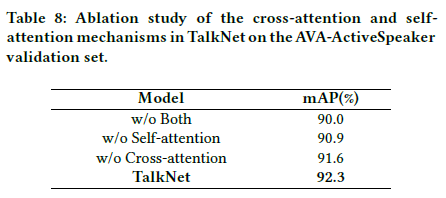
Ablation study of TalkNet attention mechanism
Audio augmentation
Qualitative Analysis
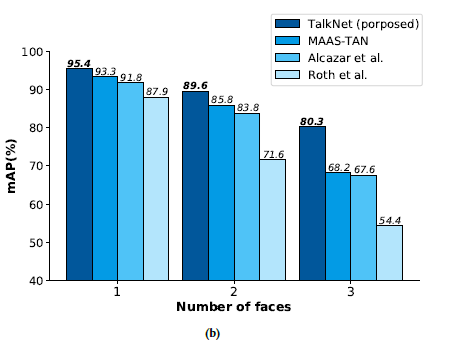
effect of the number of visible faces
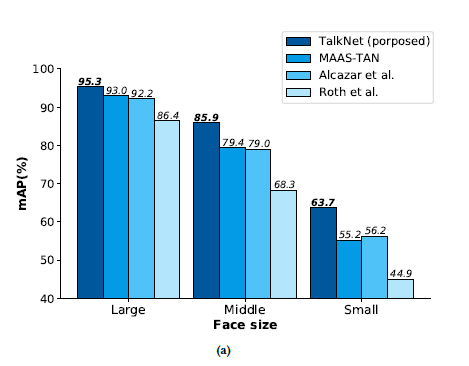
different face sizes

Currently pursuing my Ph.D. in GIST, I am deeply intrigued by the field of speaker diarization and committed to making meaningful contributions to it.