Papers
Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction, in Proc. ICLR 2022
Robust Self-Supervised Audio-Visual Speech Recognition, in Proc. Interspeech 2022 (blog)
Learning Lip-Based Audio-Visual Speaker Embeddings with AV-HuBERT, in Proc. Interspeech 2022
Practice of the Conformer Enhanced Audio-Visual Hubert on Mandarin and English, in Proc. ICASSP 2023
Overview: Hubert
- Published on arXiv on: 14 Jun 2021 by: FAIR
Pre-training
- HuBERT pre-training is very similar to BERT
- Mask some of the input tokens and train the model to retrieve these missing/masked tokens
- One key challenge for HuBERT is that speech is continuous, unlike text which is discrete.
- To overcome this challenge, Acoustic Unit Discover System was used (as shown in the following figure)
- to cluster continuous input speech into discrete units (or codebooks) that can be masked while pre-training
- Mask some of the input tokens and train the model to retrieve these missing/masked tokens
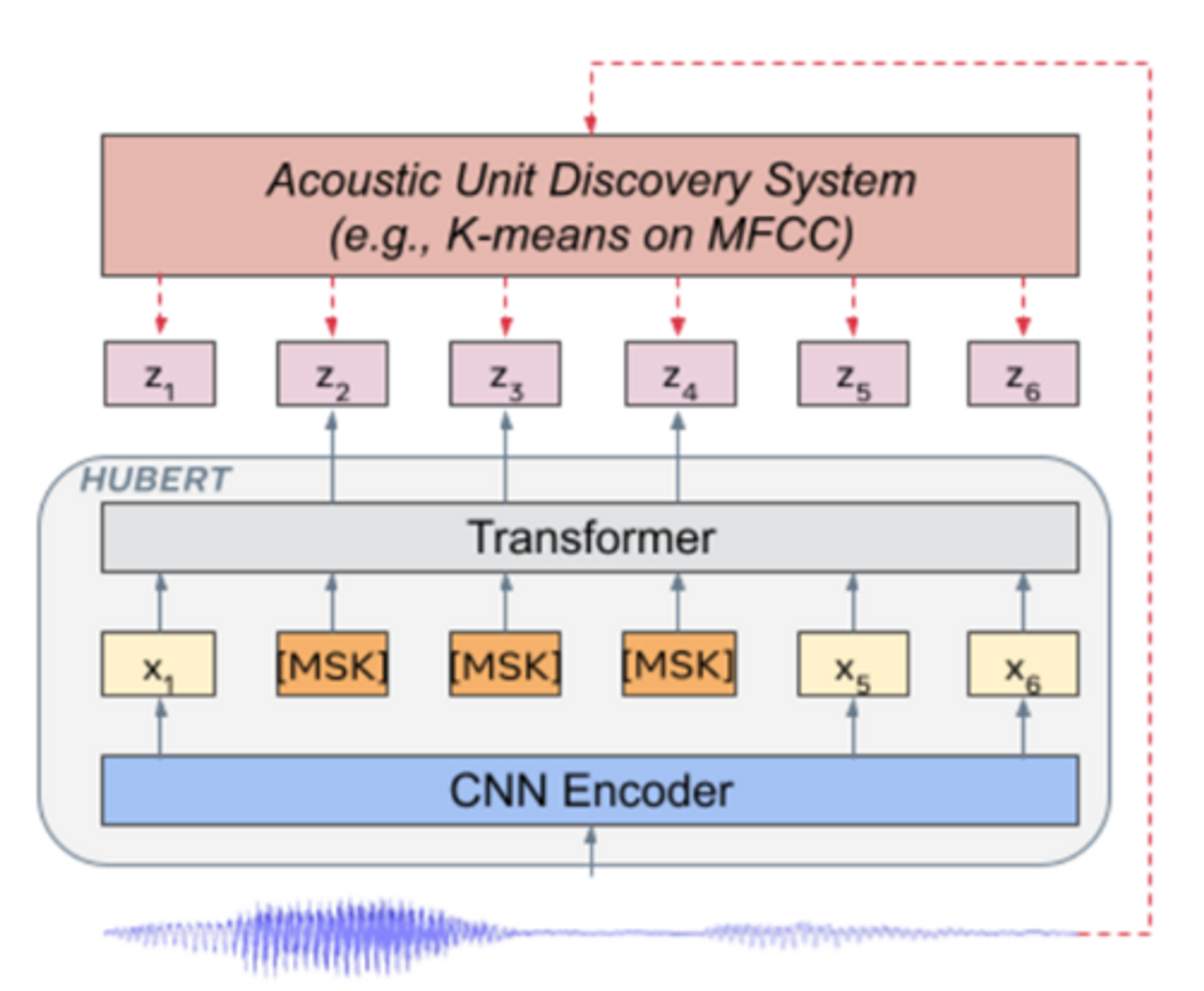
Acoustic Unit Discovery System
- Let denote a speech utterance of frames, the acoustic unit discovery system uses a clustering algorithm (e.g k-means) on this input features to cluster them into a predefined number of clusters
- The discovered hidden units are denoted with where as shown in the following figure
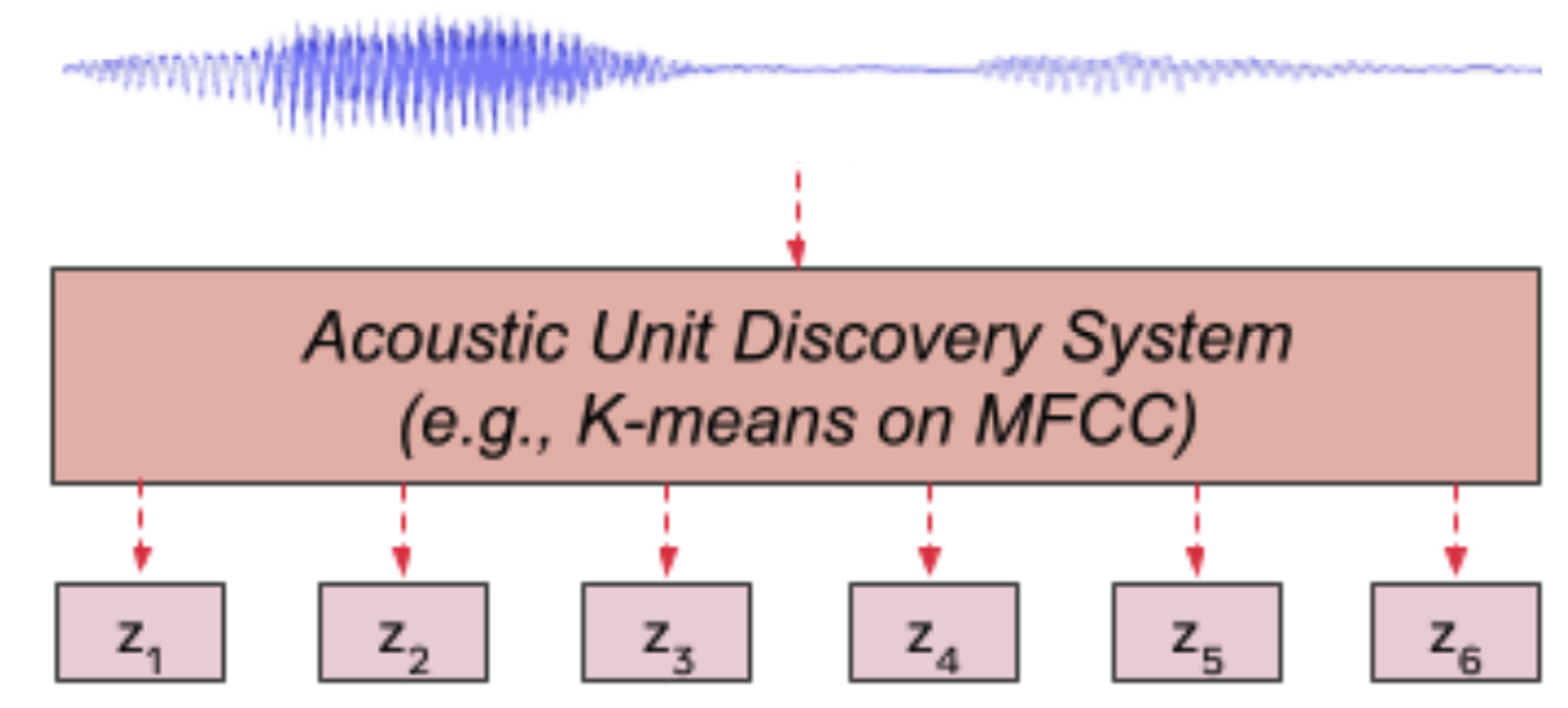
- To improve the clustering quality, they tried two different methods:
- Cluster Ensembles:
- An ensemble of clusters can provide complementary information to facilitate representation learning.
- For example, an ensemble of k-means models with different codebook sizes can create targets of different classes (vowel/consonant).
- Iterative Refinement of Cluster Assignments:
- A new generation of clusters can be created using the pre-trained model from the earlier generation.
- Cluster Ensembles:
HuBERT Model
HuBERT follows the same architecture as wav2vec 2.0 with two different parts:
-
CNN Encoder:
The convolutional waveform encoder generates a feature sequence at a 20ms framerate for audio sampled at 16kHz (CNN encoder down-sampling factor is 320x).
The audio encoded features are then randomly masked.
-
BERT:
The encoded features from the CNN Encoder get masked and sent to this model which can be considered as an acoustic BERT.
Regarding masking, they used the same strategy used for SpanBERT
where p% of the timesteps are randomly selected as start indices
And then BERT learns to predict the latent features of the unmasked and the masked input equally.
Objective
HuBERT is pre-trained to minimize the cross-entropy loss computed over masked and unmasked timesteps as and respectively.
The final loss is computed as a weighted sum of the two terms with a hyper-parameter
- Where is the projection matrix appended at the end of HuBERT during
pre-training;
- a different projection matrix is used for different cluster model. - is the embedding for code-word
- computes the cosine similarity between two vectors
- scales the logit, which is set to
AV-HuBERT
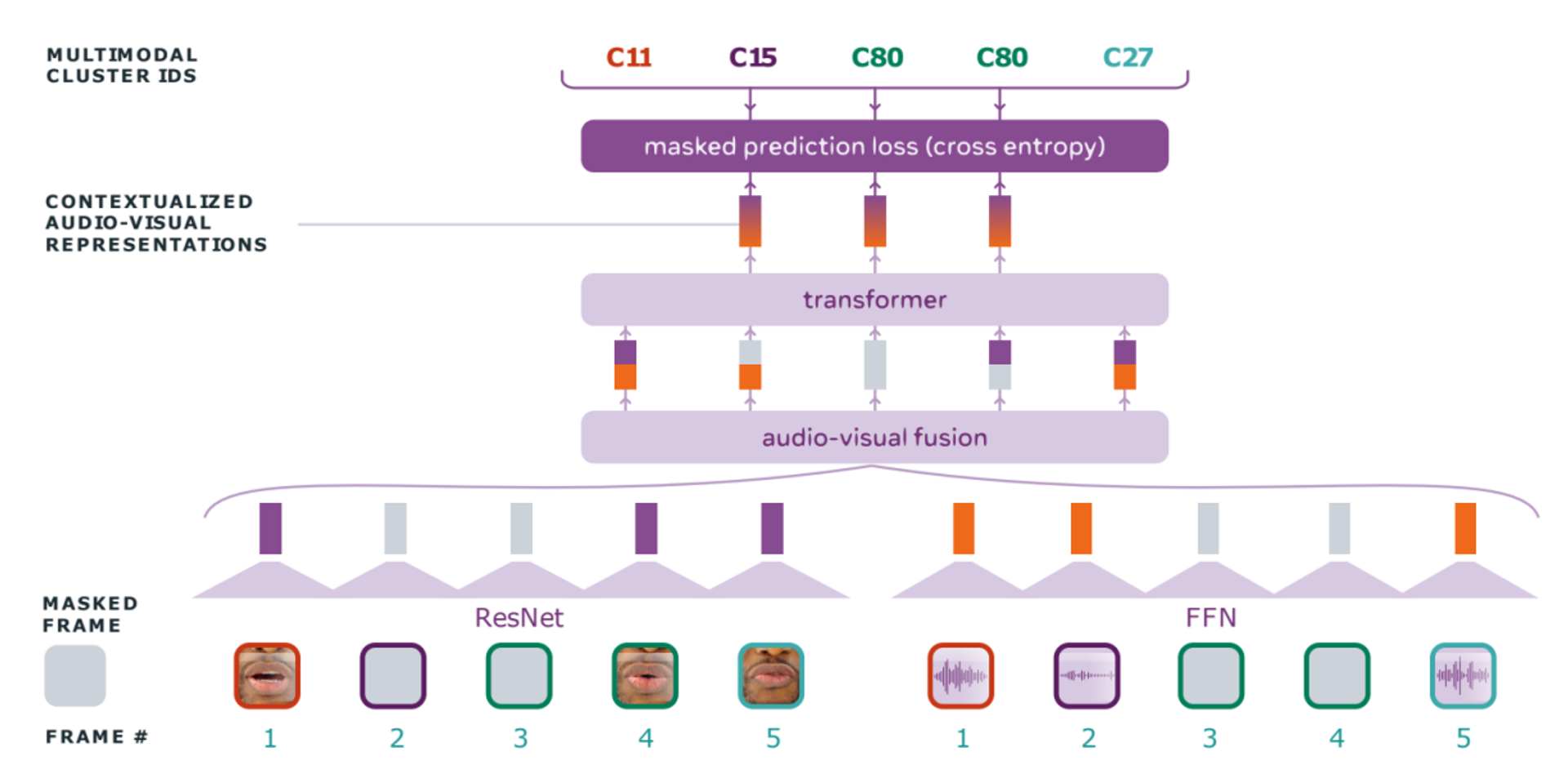
Audio-Visual HuBERT
The AV-HuBERT model is a multimodal learning approach that integrates both acoustic and visual frames for training
It uses light-weight encoders specific to each modality to generate intermediate features.
Audio-visual input
- AV-HuBERT is a model that combines audio features with the visual features
- More formally, given an audio stream and a visual stream aligned together
Masking
-
Both the input audio stream and the image stream are going to be masked independently using two different masking probabilities and
-
That’s because inferring the masked targets given the audio stream is more straightforward than using the visual stream stream
💡 So, setting a high masking probability for acoustic frames is essential to help the whole model capture the language characteristics
💡 On the contrary, setting a high masking probability for the visual input hurts its ability to learn meaningful features
-
-
The audio stream will be masked into by a binary masking .
-
Specifically, is replaced with a masked embedding following the same masking method as HuBERT
-
In parallel, the input image stream will be masked into by a novel masking strategy
Masking by substitution
- some segments in the visual stream will be substituted with random segments from the same video
- More formally, given an input video , an imposter segment taken from the original video will be used to corrupt the input video to
1. masking intervals
2. replacing them with the imposter video using an offset integer sampled from the interval , as shown in the following formula:
💡 To solve the task, the model needs to first identify the fake frames and then infer the labels belonging to the original frames
💡 the fake segment detection sub-task becomes less trivial compared to when using vanilla masking or substitution with non-consecutive frames.
-
-
Model
-
audio encoder
- a simple Fully-Forward Network (FFN) will be used to extract acoustic features from the masked audio stream
-
visual encoder
- modified ResNet-18, will be used to extract visual features from the visual stream
-
Then, these acoustic features will be concatenated with the visual features
- on the channel-dimension forming audio-visual features
- according to two random probabilities and useful for modality dropout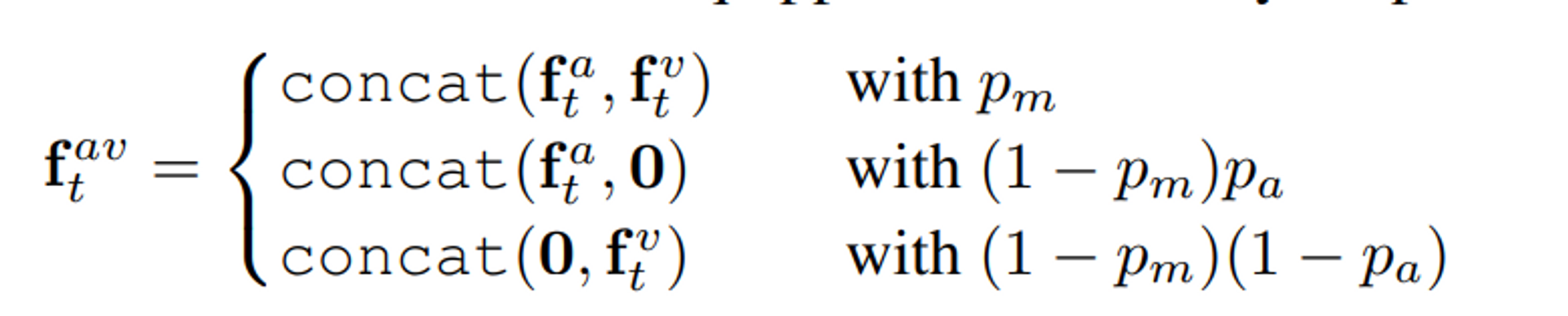
-
transformer encoder
- Then, the acoustic-visual features are encoded into a sequence of contextualized features
- followed by a linear projection layer which maps features into logits:
-
- Finally, AV-HuBERT is pre-trained to first identify the fake frames and then infer the labels belonging to the original frames according to the following loss function:
- Where is the clustered representations using clustering algorithm (e.g. k-means) such that each belongs to one of different clusters (codebooks).
- The input features to the clustering algorithm change based on the training iteration
- For the first iteration, MFCC acoustic features extracted from the input audio stream are used.
- For the other iterations, intermediate layers of the Visual HuBERT model are used.
- The input features to the clustering algorithm change based on the training iteration
- Where is the clustered representations using clustering algorithm (e.g. k-means) such that each belongs to one of different clusters (codebooks).
Experiment
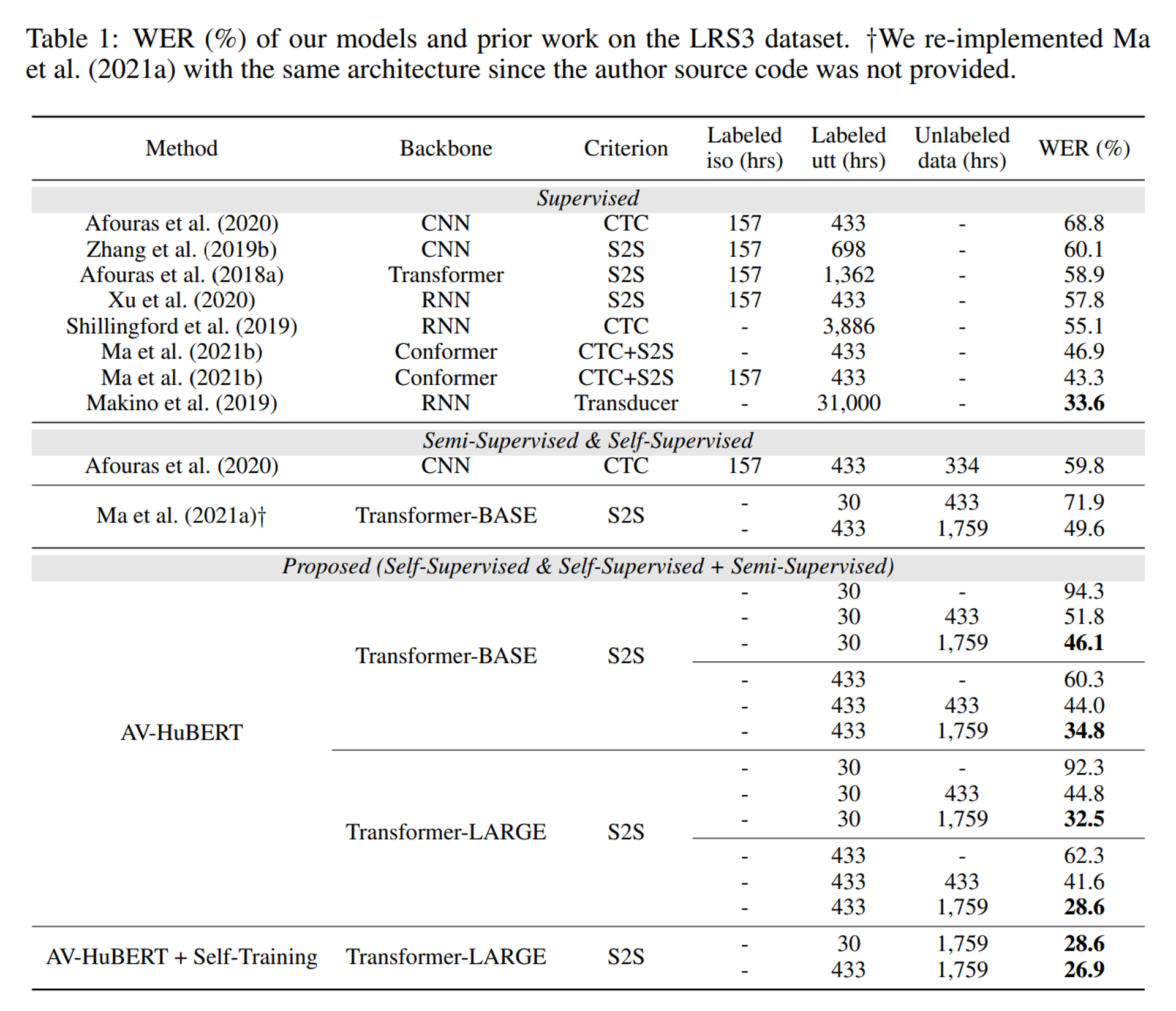
Lip Reading
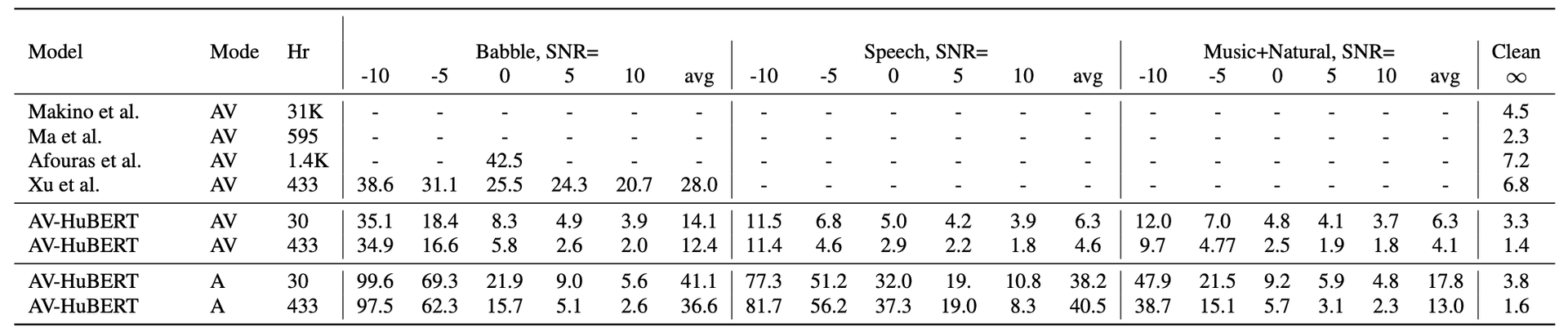
Speech Recognition (AVSR)
Reference blog
