Self-Supervised Learning (SSL)
1.2022, AV-HuBERT [ICLR]
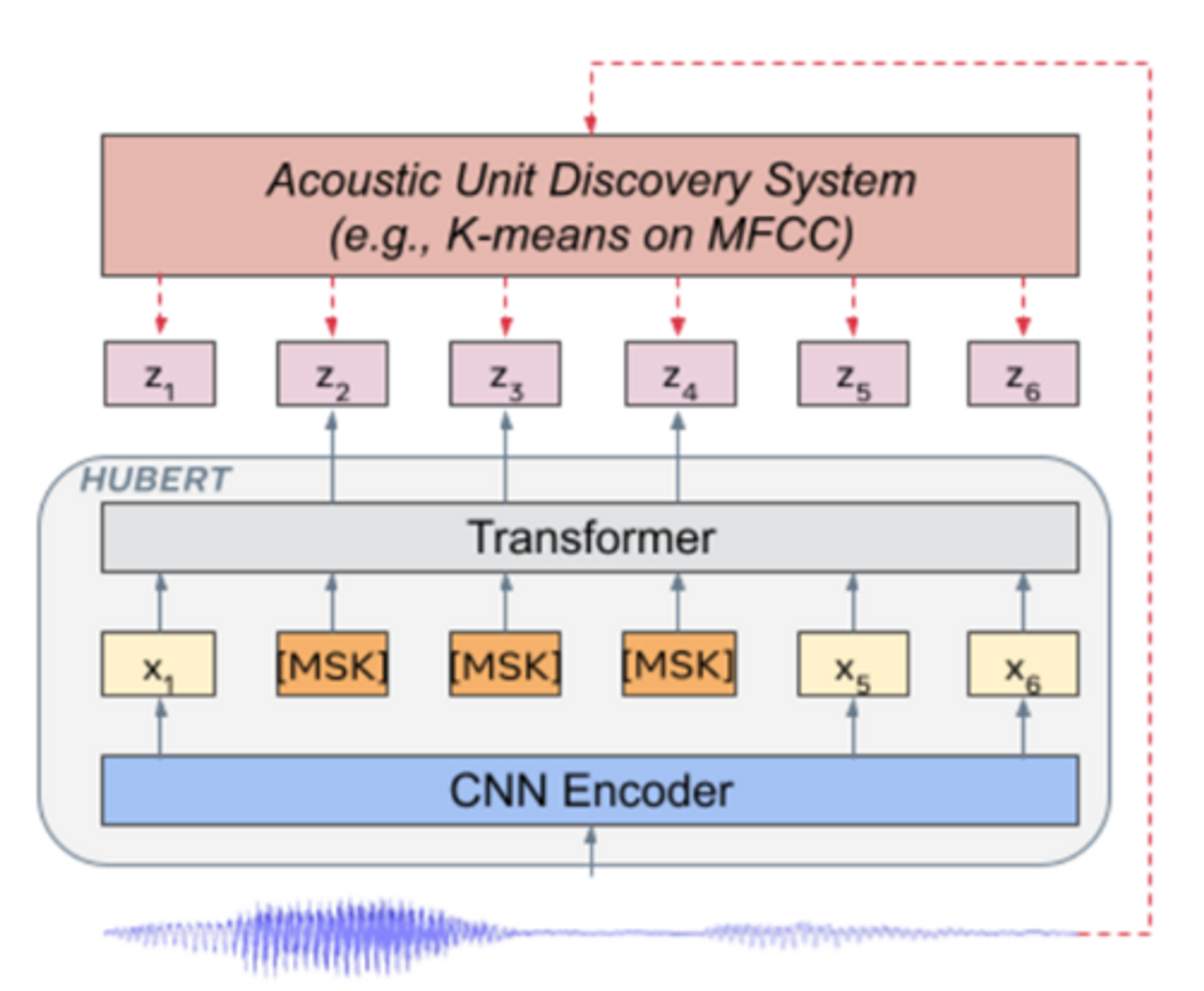
Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction, in Proc. ICLR 2022
2023년 5월 17일
2.2021, DINO (Emerging Properties in Self-Supervised Vision Transformers) [ICCV]
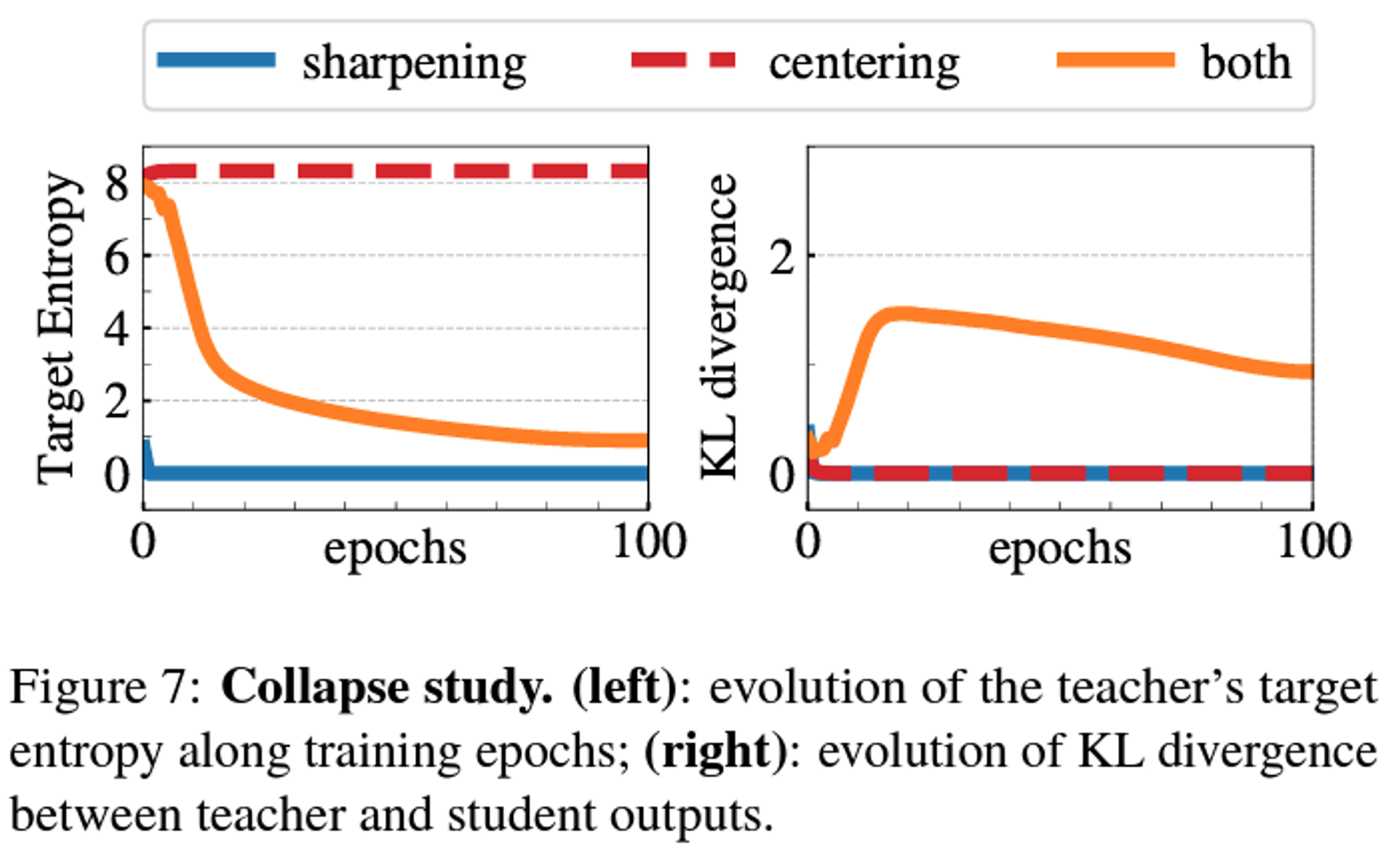
논문 리뷰
2023년 11월 16일