Published on ICASSP 2023, Naver CLOCA
Introduction
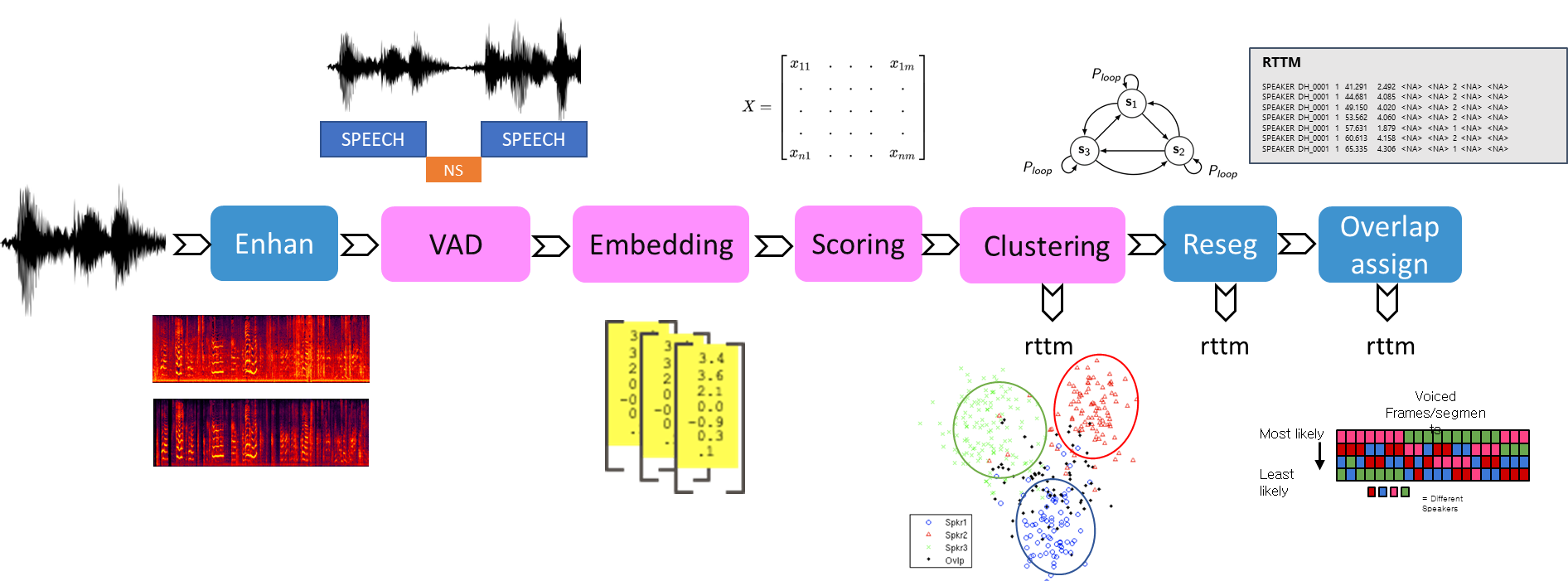
- speaker diarization system: four sub-systems
- end point detection
- speaker embedding extraction
- window size of 1.5s and shift size of 0.5s
- Three state-of-the-art models are adopted
- RawNet3\, ECAPA-TDNN\, and MFA-Conformer
- feature enhancement
- dimensionality reduction and attention-based embedding aggregation
- to refine the extracted speaker embeddings
- Clustering
- assigns speaker labels to each extracted embedding
Introduction
- Speaker embedding extractors (EEs)
- the process of separating an audio recording into segments corresponding to individual speaker
- maps an utterance to a latent space where speakers can be discriminated
- plays a critical role in speaker diarization systems
Problems
-
The authors focus on two key problems:
- 1) the difficulty of evaluating the performance of EEs for diarization
- differ between speaker verification and diarization
- 2) the fact that EEs have not been trained on inputs with multiple speakers
- such as overlapped speech and speaker changes
- degrades their performance
- 1) the difficulty of evaluating the performance of EEs for diarization
-
Propose
- two data augmentation techniques
- new evaluation protocols
-
1) the difficulty of evaluating the performance of EEs for diarization
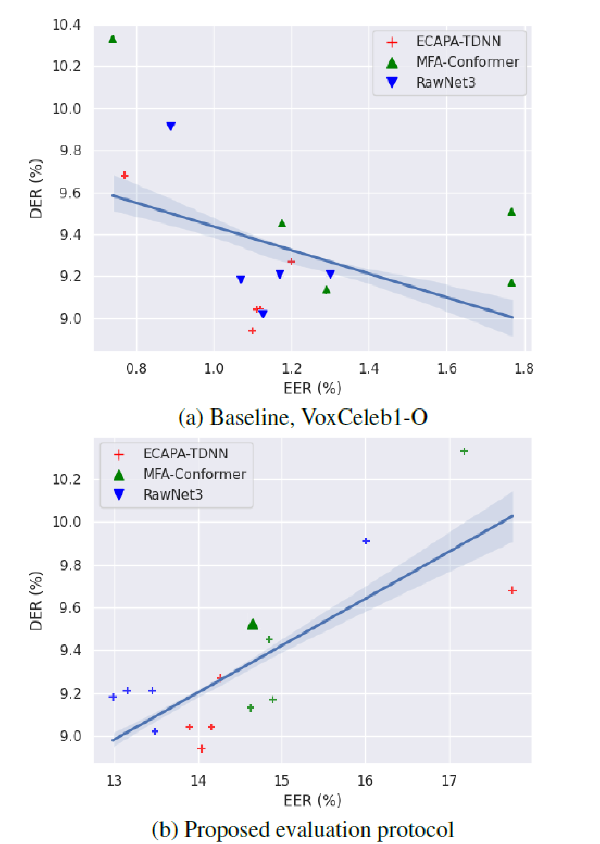
- Problem: the correlation between (EERs) of (EEs) and rate (DER) is not strong
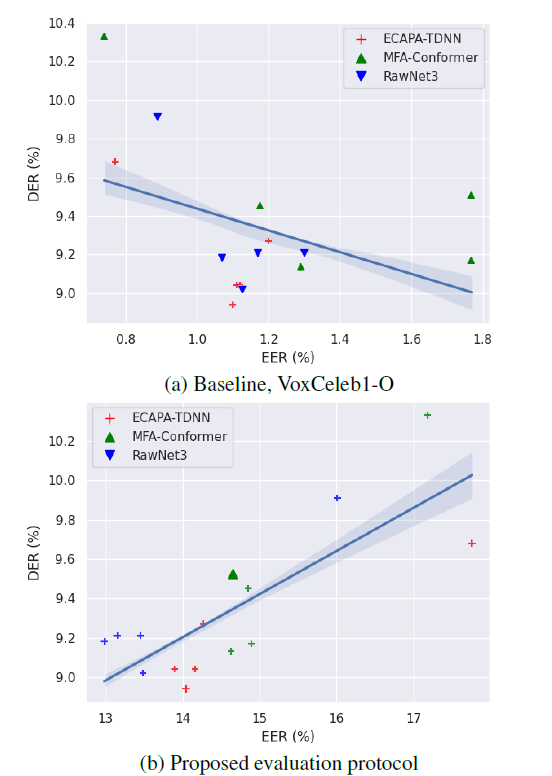
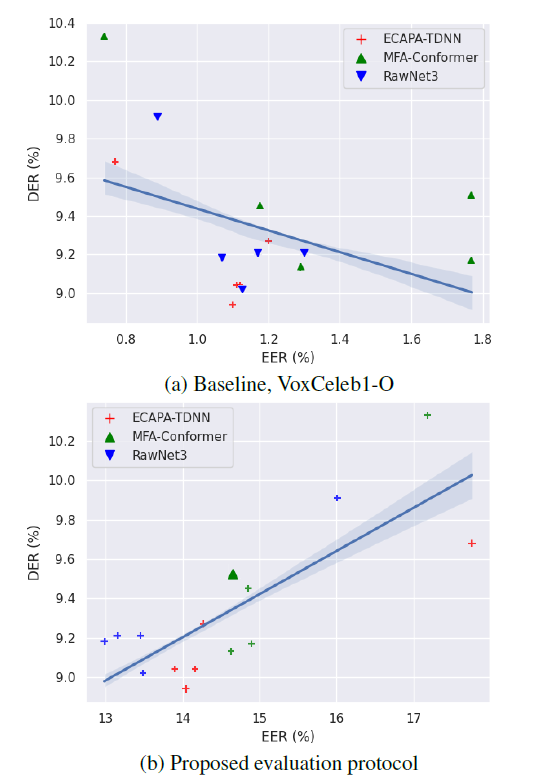
New evaluation protocols
- generating and adopting speaker verification evaluation protocols
- easier positive and harder negative trials by composing pairs within the same audio file
- They crop the input audio into short segments using RTTM files and compose trials using these segments:
- (a) target and non-target single speaker-single speaker
- (b) target and non-target overlap-single speaker
- (c) target and non-target speaker change-single speaker.

-
two data augmentation techniques
- make EEs aware of overlapped speech and speaker change segments
-
Overlapped speech augmentation
- adds a minor speaker's scaled and cropped utterance => major speaker's utterance
- randomly selected between 200ms and 700ms
- scaled to a randomly selected target signal-to-noise ratio (SNR) compared major utt.
-
Speaker change augmentation
- replaces a random region of a major speaker's utterance
- a scaled and cropped minor speaker's utterance
- first select the type of speaker change among three types:
- (i) major to minor speaker
- (ii) minor to major speaker
- (iii) major to minor to major speaker
- two different speaker changes consecutively\,
- lower maximum duration of 300ms
- prevent excessively removing the major speaker's information
- replaces a random region of a major speaker's utterance
Experiment
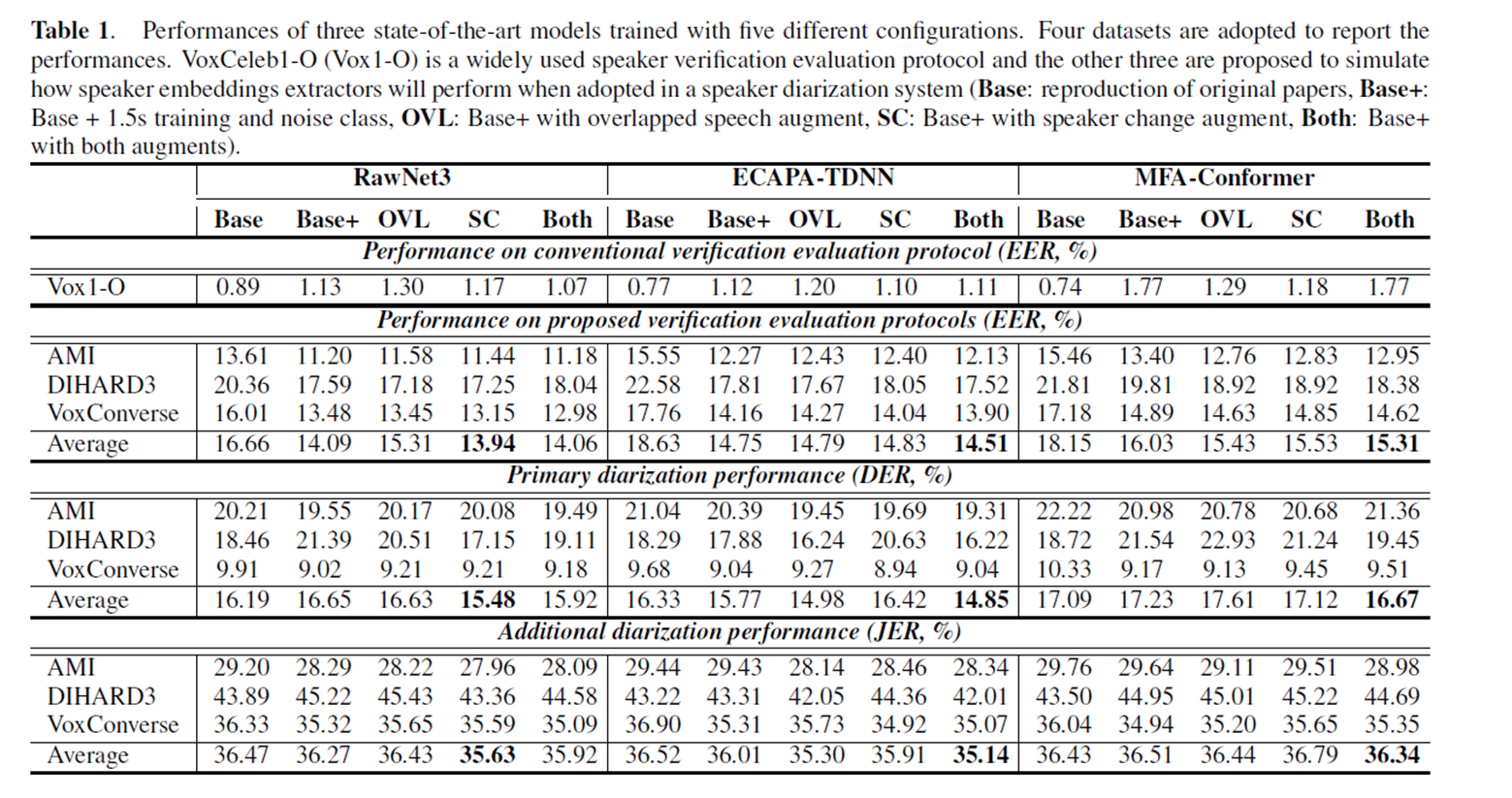
- Experiment
- three state-of-the-art models (RawNet3\, ECAPA-TDNN\, and MFA-Conformer)
- evaluate them on three datasets (AMI\, DIHARD3\, and VoxConverse).
- propose two data augmentation techniques (overlapped speech and speaker change)

Currently pursuing my Ph.D. in GIST, I am deeply intrigued by the field of speaker diarization and committed to making meaningful contributions to it.
I appreciate you giving this knowledge. I really appreciate your great post. You've really given readers of this blog article something useful and engaging to read right now geometry dash